hCaptcha is a reCAPTCHA clone that has been growing in popularity over 2020 and 2021, in particular due to Cloudflare’s conversion of their nag screens from Google’s reCAPTCHA to hCaptcha. Although hCaptcha advertises itself as being a privacy-conscious alternative to reCAPTCHA, there’s also an incentive for websites to switch over: hCaptcha will pay websites each time one of their users completes a hCaptcha challenge.
Now the question is: how does you completing a captcha earn anyone money? Of course, hCaptcha is a VC-funded business, so it can afford to burn money in the pursuit of market share; nonetheless there needs to be a plausible business model there, and it’s not obvious at first sight.
If you read the hCaptcha website, they suggest that AI startups will pay them to label their images for them. 1 Labelling images is a labour-intensive task and required for some current-generation machine learning approaches. AI startups are well-funded and have money to spend on labelling, so this sounds like a reasonable case of selling shovels during a gold rush. But the output from solving CAPTCHAs isn’t obviously isomorphic to the type of labelling required for machine learning, which is often quite specific and requires a very low error rate.
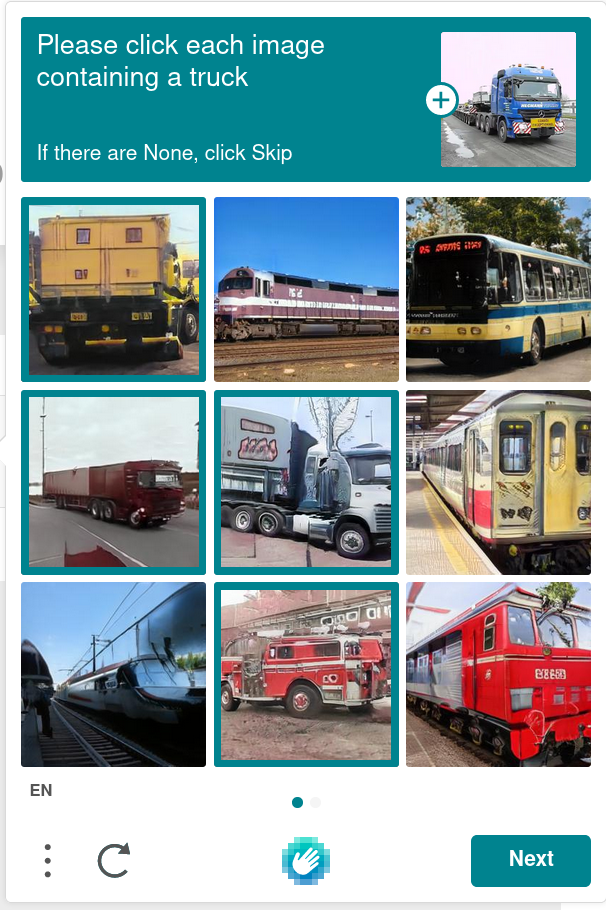
Complex CAPTCHA challenges are not possible, as web users turn out to be drunk, blind, 3 years old, or just randomly clicking buttons to get this infernal thing to go away. Accordingly, hCaptcha challenges are simple: select the images that match a simple 1-3 word prompt from a 3x3 grid. This is fortunately easy for most real people. 2 3
The most common prompts seem to be selecting buses, trucks, boats or trains out of the grid.4 The market demand for this sort of simple labelling must be rather limited, even if challenges have to be repeated many times and cross-checked to get an acceptable error rate.
So far, a little inscrutable but all seems sensible enough. But then it all gets interesting when you actually take a look at the images in a little more detail:

Starting from the top left and going right, we have:
- A boat that appears to have been painted by Dalí, with a mast drooping like a wet noodle.
- A plane with tricycle landing gear, except it’s got two sets of wheels at the front and one at the back. That’s not normal!
- A normal looking plane with some odd-looking clouds above.
- A bus with an axle in front of the door, and another behind it, and another at the back. Hmm
- A boat in a marina made of splodges.
- A normal-looking boat on a normal-looking sea, except - look at that horizon! How did that happen.
- A single-decker london bus with a ghost of it’s double-decker cousin above. And a giant moth perched on it at the back.
- Another ghostly upper deck on a regional bus.
- A sailing boat with some oddly stylised “alien” writing on the sail.
These images are obviously AI-generated. They have all the hallmarks of GAN output, with typical artifacts and oddities. Have some more and see if you can spot the same things in these other challenges - it’s not hard at all, is it!
The question then is why? Why would hCaptcha be generating these challenges - aren’t they supposed to be labelling real life, not some AI mirages? You know the labels before you generate them, what’s the point in using humans to re-label them again… And why are the results so bad - these are definitely not state of the art!
The only explanation that makes sense is that hCaptcha is not really doing this whole AI-labelling business at all, or if they are it’s only in very limited fashion. Most of the time they’re just using a GAN to generate images that defeat the bots’ image recognition AI. And the GAN isn’t trained to optimise human recognition, rather to confound the bots in an arms race, leading to the bad image quality.
If you have any better ideas I’d be glad to hear them because this whole thing doesn’t really make much sense.
Footnotes:
-
If you look closer, they have an article that purports to explain the “technical architecture of hCaptcha” which is a supreme example of buzzword-stuffing blockchain-washed nothing. There is less than zero need for a blockchain to track customer requests, much less the public Ethereum blockchain, but it’s the buzzword of the month so it must go in. ↩
-
Most real users, that is. There are some users for whom the challenge is actually too hard, or who’ve been blackholed and are interpreting bad IP reputation as poor skill. But the ones who fall down most often are those who try too hard and analyse the prompt and challenge in too much detail. The real way to solve these image challenges is to answer what you think other people will answer, rather than the correct answer. And don’t take too long either, just a quick glance is all your competition are giving! Anecdotally, this isn’t too common with hCaptcha, but reCAPTCHA challenges are extremely prone to this failure if you think too hard. ↩
-
Unfortunately this is also quite easy for bots, somewhat subverting the point of a CAPTCHA, so that’s how browser fingerprinting and IP reputation creep in to get reasonable enough results. ↩
-
These prompts are so common that a front-page post on Hacker News consisted of this observation (and prompted me to write up my thoughts on the topic from the past few months). ↩
{kind=link}
{kind=link}
{kind=link}