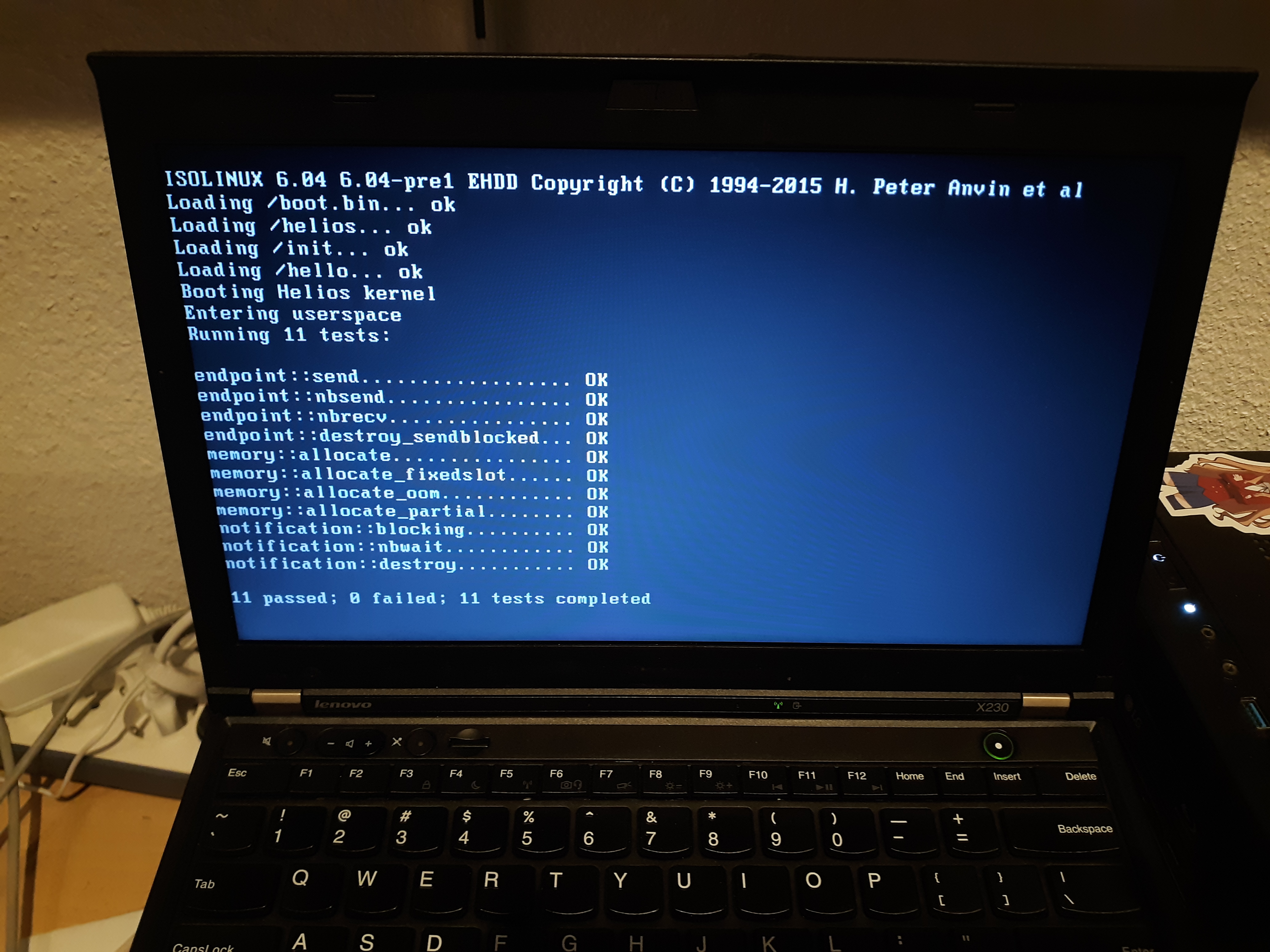
Today I would like to show you the implementation of the first userspace driver for Helios: a simple serial driver. All of the code we’re going to look at today runs in userspace, not in the kernel, so strictly speaking this should be “notes from OS hacking in Hare”, but I won’t snitch if you don’t.
Note: In the previous entry to this series, I promised to cover the userspace threading API in this post. I felt like covering this instead. Sorry!
A serial port provides a simple protocol for transferring data between two systems. It generalizes a bit, but for our purposes we can just think of this as a terminal which you can use over a simple cable and a simple protocol. It’s a standard x86_64 feature (though one which has been out of style for a couple of decades now), and its simple design (and high utility) makes it a good choice for the first driver to write for Helios. We’re going to look at the following details today:
- The system’s initramfs
- The driver loader
- The serial driver itself
The initramfs used by Helios, for the time being, is just a tarball. I imported format::tar from the standard library, a module which I designed for this express purpose, and made a few minor tweaks to make it suitable for Helios’ needs. I also implemented seeking within a tar entry to make it easier to write an ELF loader from it. The bootloader loads this tarball into memory, the kernel provides page capabilities to init for it, and then we can map it into memory and study it, something like this:
let base = rt::map_range(rt::vspace, 0, 0, &desc.pages)!;
let slice = (base: *[*]u8)[..desc.length];
const buf = bufio::fixed(slice, io::mode::READ);
const rd = tar::read(&buf);
Pulling a specific driver out of it looks like this:
// Loads a driver from the bootstrap tarball.
fn earlyload(fs: *bootstrapfs, path: str) *process = {
tar::reset(&fs.rd)!;
path = strings::ltrim(path, '/');
for (true) {
const ent = match (tar::next(&fs.rd)) {
case io::EOF =>
break;
case let ent: tar::entry =>
yield ent;
case let err: tar::error =>
abort("Invalid bootstrap.tar file");
};
defer tar::skip(&ent)!;
if (ent.name == path) {
// TODO: Better error handling here
const proc = match (load_driver(&ent)) {
case let err: io::error =>
abort("Failed to load driver from boostrap");
case let err: errors::error =>
abort("Failed to load driver from boostrap");
case let proc: *process =>
yield proc;
};
helios::task_resume(proc.task)!;
return proc;
};
};
abort("Missing bootstrap driver");
};
This code finds a file in the tarball with the given path (e.g. drivers/serial), creates a process with the driver loader, then resumes the thread and the driver is running. Let’s take a look at that driver loader next. The load_driver entry point takes an I/O handle to an ELF file and loads it:
fn load_driver(image: io::handle) (*process | io::error | errors::error) = {
const loader = newloader(image);
let earlyconf = driver_earlyconfig {
cspace_radix = 12,
};
load_earlyconfig(&earlyconf, &loader)?;
let proc = newprocess(earlyconf.cspace_radix)?;
load(&loader, proc)?;
load_config(proc, &loader)?;
let regs = helios::context {
rip = loader.header.e_entry,
rsp = INIT_STACK_ADDR,
...
};
helios::task_writeregisters(proc.task, ®s)?;
return proc;
};
This is essentially a standard ELF loader, which it calls via the more general “newprocess” and “load” functions, but drivers have an extra concern: the driver manifest. The “load_earlyconfig” processes manifest keys which are necessary to configure prior to loading the ELF image, and the “load_config” function takes care of the rest of the driver configuration. The remainder of the code configures the initial thread.
The actual driver manifest is an INI file which is embedded in a special ELF section in driver binaries. The manifest for the serial driver looks like this:
[driver]
name=pcserial
desc=Serial driver for x86_64 PCs
[cspace]
radix=12
[capabilities]
0:serial =
1:note =
2:cspace = self
3:ioport = min=3F8, max=400
4:ioport = min=2E8, max=2F0
5:irq = irq=3, note=1
6:irq = irq=4, note=1
Helios is a capability-oriented system, and in order to do anything useful, each process needs to have capabilities to work with. Each driver declares exactly what capabilities it needs and receives only these capabilities, and nothing else. This provides stronger isolation than Unix systems can offer (even with something like OpenBSD’s pledge(2)) — this driver cannot even allocate memory.
A standard x86_64 ISA serial port uses two I/O port ranges, 0x3F8-0x400 and 0x2E8-0x2F0, as well as two IRQs, IRQ 3 and 4, together providing support for up to four serial ports. The driver first requests a “serial” capability, which is a temporary design for an IPC endpoint that the driver will use to actually process read or write requests. This will be replaced with a more sophisticated device manager system in the future. It also creates a notification capability, which is later used to deliver the IRQs, and requests a capability for its own cspace so that it can manage capability slots. This will be necessary later on. Following this it requests capabilities for the system resources it needs, namely the necessary I/O ports and IRQs, the latter configured to be delivered to the notification in capability slot 1.
With the driver isolated in its own address space, running in user mode, and only able to invoke this set of capabilities, it’s very limited in what kind of exploits it’s vulnerable to. If there’s a vulnerability here, the worst that could happen is that a malicious actor on the other end of the serial port could crash the driver, which would then be rebooted by the service manager. On Linux, a bug in the serial driver can be used to compromise the entire system.
So, the driver loader parses this file and allocates the requested capabilities for the driver. I’ll skip most of the code, it’s just a boring INI file parser, but the important bit is the table for capability allocations:
type capconfigfn = fn(
proc: *process,
addr: uint,
config: const str,
) (void | errors::error);
// Note: keep these tables alphabetized
const capconfigtab: [_](const str, *capconfigfn) = [
("cspace", &cap_cspace),
("endpoint", &cap_endpoint),
("ioport", &cap_ioport),
("irq", &cap_irq),
("note", &cap_note),
("serial", &cap_serial),
// TODO: More
];
This table defines functions which, when a given INI key in the [capabilities] section is found, provisions the requested capabilities. This list is not complete; in the future all kernel objects will be added as well as userspace-defined interfaces (similar to serial) which implement various driver interfaces, such as ‘fs’ or ‘gpu’. Let’s start with the notification capability:
fn cap_note(
proc: *process,
addr: uint,
config: const str,
) (void | errors::error) = {
if (config != "") {
return errors::invalid;
};
const note = helios::newnote()?;
defer helios::destroy(note)!;
helios::copyto(proc.cspace, addr, note)?;
};
This capability takes no configuration arguments, so we first simply check that the value is empty. Then we create a notification, copy it into the driver’s capability space at the requested capability address, then destroy our copy. Simple!
The I/O port capability is a bit more involved: it does accept configuration parameters, namely what I/O port range the driver needs.
fn cap_ioport(
proc: *process,
addr: uint,
config: const str,
) (void | errors::error) = {
let min = 0u16, max = 0u16;
let have_min = false, have_max = false;
const tok = strings::tokenize(config, ",");
for (true) {
let tok = match (strings::next_token(&tok)) {
case void =>
break;
case let tok: str =>
yield tok;
};
tok = strings::trim(tok);
const (key, val) = strings::cut(tok, "=");
let field = switch (key) {
case "min" =>
have_min = true;
yield &min;
case "max" =>
have_max = true;
yield &max;
case =>
return errors::invalid;
};
match (strconv::stou16b(val, base::HEX)) {
case let u: u16 =>
*field = u;
case =>
return errors::invalid;
};
};
if (!have_min || !have_max) {
return errors::invalid;
};
const ioport = helios::ioctl_issue(rt::INIT_CAP_IOCONTROL, min, max)?;
defer helios::destroy(ioport)!;
helios::copyto(proc.cspace, addr, ioport)?;
};
Here we split the configuration string on commas and parse each as a key/value pair delimited by an equal sign (”=”), looking for a key called “min” and another called “max”. At the moment the config parsing is just implemented in this function directly, but in the future it might make sense to write a small abstraction for capability configurations like this. Once we know the I/O port range the user wants, then we issue an I/O port capability for that range and copy it into the driver’s cspace.
IRQs are a bit more involved still. An IRQ capability must be configured to deliver IRQs to a notification object.
fn cap_irq(
proc: *process,
addr: uint,
config: const str,
) (void | errors::error) = {
let irq = 0u8, note: helios::cap = 0;
let have_irq = false, have_note = false;
// ...config string parsing omitted...
const _note = helios::copyfrom(proc.cspace, note, helios::CADDR_UNDEF)?;
defer helios::destroy(_note)!;
const (ct, _) = rt::identify(_note)!;
if (ct != ctype::NOTIFICATION) {
// TODO: More semantically meaningful errors would be nice
return errors::invalid;
};
const irq = helios::irqctl_issue(rt::INIT_CAP_IRQCONTROL, _note, irq)?;
defer helios::destroy(irq)!;
helios::copyto(proc.cspace, addr, irq)?;
};
In order to do this, the driver loader copies the notification capability from the driver’s cspace and into the loader’s cspace, then creates an IRQ with that notification. It copies the new IRQ capability into the driver, then destroys its own copy of the IRQ and notification.
In this manner, the driver can declaratively state which capabilities it needs, and the loader can prepare an environment for it with these capabilities prepared. Once these capabilities are present in the driver’s cspace, the driver can invoke them by addressing the numbered capability slots in a send or receive syscall.
To summarize, the loader takes an I/O object (which we know is sourced from the bootstrap tarball) from which an ELF file can be read, finds a driver manifest, then creates a process and fills the cspace with the requested capabilities, loads the program into its address space, and starts the process.
Next, let’s look at the serial driver that we just finished loading.
Let me first note that this serial driver is a proof-of-concept at this time. A future serial driver will take a capability for a device manager object, then probe each serial port and provision serial devices for each working serial port. It will define an API which supports additional serial-specific features, such as configuring the baud rate. For now, it’s pretty basic.
This driver implements a simple event loop:
- Configure the serial port
- Wait for an interrupt or a read/write request from the user
- On interrupt, process the interrupt, writing buffered data or buffering readable data
- On a user request, buffer writes or unbuffer reads
- GOTO 2
The driver starts by defining some constants for the capability slots we set up in the manifest:
def EP: helios::cap = 0;
def IRQ: helios::cap = 1;
def CSPACE: helios::cap = 2;
def IRQ3: helios::cap = 5;
def IRQ4: helios::cap = 6;
It also defines some utility code for reading and writing to the COM registers, and constants for each of the registers defined by the interface.
// COM1 port
def COM1: u16 = 0x3F8;
// COM2 port
def COM2: u16 = 0x2E8;
// Receive buffer register
def RBR: u16 = 0;
// Transmit holding regiser
def THR: u16 = 0;
// ...other registers omitted...
const ioports: [_](u16, helios::cap) = [
(COM1, 3), // 3 is the I/O port capability address
(COM2, 4),
];
fn comin(port: u16, register: u16) u8 = {
for (let i = 0z; i < len(ioports); i += 1) {
const (base, cap) = ioports[i];
if (base != port) {
continue;
};
return helios::ioport_in8(cap, port + register)!;
};
abort("invalid port");
};
fn comout(port: u16, register: u16, val: u8) void = {
for (let i = 0z; i < len(ioports); i += 1) {
const (base, cap) = ioports[i];
if (base != port) {
continue;
};
helios::ioport_out8(cap, port + register, val)!;
return;
};
abort("invalid port");
};
We also define some statically-allocated data structures to store state for each COM port, and a function to initialize the port:
type comport = struct {
port: u16,
rbuf: [4096]u8,
wbuf: [4096]u8,
rpending: []u8,
wpending: []u8,
};
let ports: [_]comport = [
comport { port = COM1, ... },
comport { port = COM2, ... },
];
fn com_init(com: *comport) void = {
com.rpending = com.rbuf[..0];
com.wpending = com.wbuf[..0];
comout(com.port, IER, 0x00); // Disable interrupts
comout(com.port, LCR, 0x80); // Enable divisor mode
comout(com.port, DL_LSB, 0x01); // Div Low: 01: 115200 bps
comout(com.port, DL_MSB, 0x00); // Div High: 00
comout(com.port, LCR, 0x03); // Disable divisor mode, set parity
comout(com.port, FCR, 0xC7); // Enable FIFO and clear
comout(com.port, IER, ERBFI); // Enable read interrupt
};
The basics are in place. Let’s turn our attention to the event loop.
export fn main() void = {
com_init(&ports[0]);
com_init(&ports[1]);
helios::irq_ack(IRQ3)!;
helios::irq_ack(IRQ4)!;
let poll: [_]pollcap = [
pollcap { cap = IRQ, events = pollflags::RECV },
pollcap { cap = EP, events = pollflags::RECV },
];
for (true) {
helios::poll(poll)!;
if (poll[0].events & pollflags::RECV != 0) {
poll_irq();
};
if (poll[1].events & pollflags::RECV != 0) {
poll_endpoint();
};
};
};
We initialize two COM ports first, using the function we were just reading. Then we ACK any IRQs that might have already been pending when the driver starts up, and we enter the event loop proper. Here we are polling on two capabilities, the notification to which IRQs are delivered, and the endpoint which provides the serial driver’s external API.
The state for each serial port includes a read buffer and a write buffer, defined in the comport struct shown earlier. We configure the COM port to interrupt when there’s data available to read, then pull it into the read buffer. If we have pending data to write, we configure it to interrupt when it’s ready to write more data, otherwise we leave this interrupt turned off. The “poll_irq” function handles these interrupts:
fn poll_irq() void = {
helios::wait(IRQ)!;
defer helios::irq_ack(IRQ3)!;
defer helios::irq_ack(IRQ4)!;
for (let i = 0z; i < len(ports); i += 1) {
const iir = comin(ports[i].port, IIR);
if (iir & 1 == 0) {
port_irq(&ports[i], iir);
};
};
};
fn port_irq(com: *comport, iir: u8) void = {
if (iir & (1 << 2) != 0) {
com_read(com);
};
if (iir & (1 << 1) != 0) {
com_write(com);
};
};
The IIR register is the “interrupt identification register”, which tells us why the interrupt occurred. If it was because the port is readable, we call “com_read”. If the interrupt occurred because the port is writable, we call “com_write”. Let’s start with com_read. This interrupt is always enabled so that we can immediately start buffering data as the user types it into the serial port.
// Reads data from the serial port's RX FIFO.
fn com_read(com: *comport) size = {
let n: size = 0;
for (comin(com.port, LSR) & RBF == RBF; n += 1) {
const ch = comin(com.port, RBR);
if (len(com.rpending) < len(com.rbuf)) {
// If the buffer is full we just drop chars
static append(com.rpending, ch);
};
};
// This part will be explained later:
if (pending_read.reply != 0) {
const n = rconsume(com, pending_read.buf);
helios::send(pending_read.reply, 0, n)!;
pending_read.reply = 0;
};
return n;
};
This code is pretty simple. For as long as the COM port is readable, read a character from it. If there’s room in the read buffer, append this character to it.
How about writing? Well, we need some way to fill the write buffer first. This part is pretty straightforward:
// Append data to a COM port read buffer, returning the number of bytes buffered
// successfully.
fn com_wbuffer(com: *comport, data: []u8) size = {
let z = len(data);
if (z + len(com.wpending) > len(com.wbuf)) {
z = len(com.wbuf) - len(com.wpending);
};
static append(com.wpending, data[..z]...);
com_write(com);
return z;
};
This code just adds data to the write buffer, making sure not to exceed the buffer length (note that in Hare this would cause an assertion, not a buffer overflow). Then we call “com_write”, which does the actual writing to the COM port.
// Writes data to the serial port's TX FIFO.
fn com_write(com: *comport) size = {
if (comin(com.port, LSR) & THRE != THRE) {
const ier = comin(com.port, IER);
comout(com.port, IER, ier | ETBEI);
return 0;
};
let i = 0z;
for (i < 16 && len(com.wpending) != 0; i += 1) {
comout(com.port, THR, com.wpending[0]);
static delete(com.wpending[0]);
};
const ier = comin(com.port, IER);
if (len(com.wpending) == 0) {
comout(com.port, IER, ier & ~ETBEI);
} else {
comout(com.port, IER, ier | ETBEI);
};
return i;
};
If the COM port is not ready to write data, we enable an interrupt which will tell us when it is and return. Otherwise, we write up to 16 bytes — the size of the COM port’s FIFO — and remove them from the write buffer. If there’s more data to write, we enable the write interrupt, or we disable it if there’s nothing left. When enabled, this will cause an interrupt to fire when (1) we have data to write and (2) the serial port is ready to write it, and our event loop will call this function again.
That covers all of the code for driving the actual serial port. What about the interface for someone to actually use this driver?
The “serial” capability defined in the manifest earlier is a temporary construct to provision some means of communicating with the driver. It provisions an endpoint capability (which is an IPC primitive on Helios) and stashes it away somewhere in the init process so that I can write some temporary test code to actually read or write to the serial port. Either request is done by “call”ing the endpoint with the desired parameters, which will cause the poll in the event loop to wake as the endpoint becomes receivable, calling “poll_endpoint”.
fn poll_endpoint() void = {
let addr = 0u64, amt = 0u64;
const tag = helios::recv(EP, &addr, &amt);
const label = rt::label(tag);
switch (label) {
case 0 =>
const addr = addr: uintptr: *[*]u8;
const buf = addr[..amt];
const z = com_wbuffer(&ports[0], buf);
helios::reply(0, z)!;
case 1 =>
const addr = addr: uintptr: *[*]u8;
const buf = addr[..amt];
if (len(ports[0].rpending) == 0) {
const reply = helios::store_reply(helios::CADDR_UNDEF)!;
pending_read = read {
reply = reply,
buf = buf,
};
} else {
const n = rconsume(&ports[0], buf);
helios::reply(0, n)!;
};
case =>
abort(); // TODO: error
};
};
“Calls” in Helios work similarly to seL4. Essentially, when you “call” an endpoint, the calling thread blocks to receive the reply and places a reply capability in the receiver’s thread state. The receiver then processes their message and “replies” to the reply capability to wake up the calling thread and deliver the reply.
The message label is used to define the requested operation. For now, 0 is read and 1 is write. For writes, we append the provided data to the write buffer and reply with the number of bytes we buffered, easy breezy.
Reads are a bit more involved. If we don’t immediately have any data in the read buffer, we have to wait until we do to reply. We copy the reply from its special slot in our thread state into our capability space, so we can use it later. This operation is why our manifest requires cspace = self. Then we store the reply capability and buffer in a variable and move on, waiting for a read interrupt. On the other hand, if there is data buffered, we consume it and reply immediately.
fn rconsume(com: *comport, buf: []u8) size = {
let amt = len(buf);
if (amt > len(ports[0].rpending)) {
amt = len(ports[0].rpending);
};
buf[..amt] = ports[0].rpending[..amt];
static delete(ports[0].rpending[..amt]);
return amt;
};
Makes sense?
That basically covers the entire serial driver. Let’s take a quick peek at the other side: the process which wants to read from or write to the serial port. For the time being this is all temporary code to test the driver with, and not the long-term solution for passing out devices to programs. The init process keeps a list of serial devices configured on the system:
type serial = struct {
proc: *process,
ep: helios::cap,
};
let serials: []serial = [];
fn register_serial(proc: *process, ep: helios::cap) void = {
append(serials, serial {
proc = proc,
ep = ep,
});
};
This function is called by the driver manifest parser like so:
fn cap_serial(
proc: *process,
addr: uint,
config: const str,
) (void | errors::error) = {
if (config != "") {
return errors::invalid;
};
const ep = helios::newendpoint()?;
helios::copyto(proc.cspace, addr, ep)?;
register_serial(proc, ep);
};
We make use of the serial port in the init process’s main function with a little test loop to echo reads back to writes:
export fn main(bi: *rt::bootinfo) void = {
log::println("[init] Hello from Mercury!");
const bootstrap = bootstrapfs_init(&bi.modules[0]);
defer bootstrapfs_finish(&bootstrap);
earlyload(&bootstrap, "/drivers/serial");
log::println("[init] begin echo serial port");
for (true) {
let buf: [1024]u8 = [0...];
const n = serial_read(buf);
serial_write(buf[..n]);
};
};
The “serial_read” and “serial_write” functions are:
fn serial_write(data: []u8) size = {
assert(len(data) <= rt::PAGESIZE);
const page = helios::newpage()!;
defer helios::destroy(page)!;
let buf = helios::map(rt::vspace, 0, map_flags::W, page)!: *[*]u8;
buf[..len(data)] = data[..];
helios::page_unmap(page)!;
// TODO: Multiple serial ports
const port = &serials[0];
const addr: uintptr = 0x7fff70000000; // XXX arbitrary address
helios::map(port.proc.vspace, addr, 0, page)!;
const reply = helios::call(port.ep, 0, addr, len(data));
return rt::ipcbuf.params[0]: size;
};
fn serial_read(buf: []u8) size = {
assert(len(buf) <= rt::PAGESIZE);
const page = helios::newpage()!;
defer helios::destroy(page)!;
// TODO: Multiple serial ports
const port = &serials[0];
const addr: uintptr = 0x7fff70000000; // XXX arbitrary address
helios::map(port.proc.vspace, addr, map_flags::W, page)!;
const (label, n) = helios::call(port.ep, 1, addr, len(buf));
helios::page_unmap(page)!;
let out = helios::map(rt::vspace, 0, 0, page)!: *[*]u8;
buf[..n] = out[..n];
return n;
};
There is something interesting going on here. Part of this code is fairly obvious — we just invoke the IPC endpoint using helios::call, corresponding nicely to the other end’s use of helios::reply, with the buffer address and size. However, the buffer address presents a problem: this buffer is in the init process’s address space, so the serial port cannot read or write to it!
In the long term, a more sophisticated approach to shared memory management will be developed, but for testing purposes I came up with this solution. For writes, we allocate a new page, map it into our address space, and copy the data we want to write to it. Then we unmap it, map it into the serial driver’s address space instead, and perform the call. For reads, we allocate a page, map it into the serial driver, call the IPC endpoint, then unmap it from the serial driver, map it into our address space, and copy the data back out of it. In both cases, we destroy the page upon leaving this function, which frees the memory and automatically unmaps the page from any address space. Inefficient, but it works for demonstration purposes.
And that’s really all there is to it! Helios officially has its first driver. The next step is to develop a more robust solution for describing capability interfaces and device APIs, then build a PS/2 keyboard driver and a BIOS VGA mode 3 driver for driving the BIOS console, and combine these plus the serial driver into a tty on which we can run a simple shell.