The fixer — Ellis called him Ray and won’t reveal his name — met him in North London near Hampstead Heath for coffee and cakes. When it came time to discuss business, to avoid being overheard, they strolled into the park.
Ray had brought Ellis a few jobs before. But this job, he warned, was of an entirely different order. As Ellis claims in “The Art of Robbery,” a self-published memoir written after his release from prison, he eventually learned that Ray had been contacted by a consultant employed by “some influential bankers from America.” The bankers “were involved in prime mortgages” and had “circumnavigated” certain regulations. Damning evidence of these circumnavigations could be found in banking files held in the King’s Cross area in a giant building known as a data center.
This is a dramatic story, and one I think should be read with a heavy dose of skepticism. It seems that most of the criminal details have been shared by Ellis. For a start, the claim that some bankers ostensibly contracted with “Ray” is just a little too perfect for a recession-era tale. These bankers are pretty much universally loathed, and this justification makes this theft seem more palatable than a simple financial motive. For example, there was a similar data centre theft in October 2006, which would be unrelated to the lending crisis in the following years.
Another problem is that Rich says crimes like these are covered-up in part by a data centre operator because they are loathe to “admit to flaws in its security, [which] would only encourage additional attacks and scare away its clients”. Therefore, the lack of evidence for the specific circumstances of this crime is supposed to be a buttress for its likelihood, not a weakness, which is not reassuring.
The story of the theft was, as far as I can tell, broken by Here is the City, then a gossipy financial news site:
The data center itself is thought to be used by a number of companies, including JPMorgan, which is believed to have told staff that some of its systems could be off-line for parts of the day today as a result of the theft. Fortunately the thieves are thought to have got away with just the computer hardware, and not any sensitive information which may also have been stored at the facility.
Reports circulating on the Internet last week that JPMorgan, a customer of Verizon Business, had been affected by the burglary were incorrect, according to a source at the investment bank. There has been no loss of service or data, said the source.
On the one hand, of course all these parties tried to cover this up. The reading-between-the-lines story implied by these early reports and Rich’s telling is that some banking higher-ups, perhaps from JPMorgan, wanted to cover up some crimes, and denying any meaningful effect is just more cover-up. But little of this is substantiated by contemporary or current reporting — which is, of course, the whole problem with using a lack of evidence as the foundation for a story.
Rich, in the Times:
“The banks knew they were sending mortgages to people who couldn’t pay back,” he says today. “That’s what broke the whole system. That was the big con.” Ellis remains convinced that the bankers who paid for the Verizon job wanted to destroy evidence of their involvement in fraudulent subprime mortgages — the inside information that Ellis received about the data center, he believes, “would have had to come from the top” — but he can’t prove it. He never saw what was on the servers.
“Our job was to get the motherboards,” he says. “We were paid quite handsomely. Whatever happened after that was none of our concern.”
In contemporaneousreports, the Metropolitan Police noted the theft of motherboards and processors. But if these bankers wanted to cover up their fraudulent practices, surely the hard drives would have been the target, right? In Rich’s version, entire servers were taken, so perhaps this is just a misunderstanding.
This story smells fishy. I believe the theft happened, of course, and Ellis’ involvement, but I am not as convinced this had anything to do with covering up some white collar crime. (By the way, the Guardian in 2018 published an interview with Ellis about the interesting prison where he was transferred and which led to his rehabilitation.)
The heist element is only about half of Rich’s story; much of it is a discussion about data centre secrecy:
The public fogginess about data centers is not an accident. It is the product of a willful strategy by the world’s largest tech corporations, whose business models rest on the public assumption that the internet, and all the data it holds, is as immaterial as air — or as a cloud, to borrow the metaphor commonly used to describe the sum of information stored on servers. As the digital-media scholar Tung-Hui Hu writes in “A Prehistory of the Cloud,” the cloud “hides its physical location by design.”
[…]
It was a lot easier to defend data when people didn’t know it existed. The more people learn about data centers, the more they hate them. […]
If you read a website like this one, you were probably aware that data centres were commonplace twenty or more years ago. Like the one near King’s Cross, some were hidden in plain sight, while others were purpose-built facilities that look like hangars stuffed with servers. But the A.I. boom has meant rapid increases in the speed, scale, and quantity of data centres. People quickly learned not only of their existence, but how much pressure they put on local resources. Tech companies, it seemed, were caught by surprise; and as someone who spends a lot of time immersed in this world, so was I.
Much of the consternation I have seen in more general audiences has been about data centres in general. People simply were not aware that Amazon has warehouses full of products, and other warehouses full of computers. As Rich writes, this is deliberate, for business secrecy reasons, security, and environmental costs. But, also, I think some of that unawareness is because of just how boring it is. If nobody wants to know hidden information, is it really a secret? It only became one when the information these companies were hiding had real-life effects.
It does seem that public awareness is putting pressure on corporations to improve data centres and make them more efficient. But that is not a standard. New data centres are powered by petroleum with a pinky promise of renewable offsets. In some regressive regions, like Alberta, new power plants for data centres must be powered by methane gas. In a further complication, Meta’s proposed data centre is scheduled to be completed before the power plant is ready, meaning it will be dependent on existing grid power for perhaps years. Meta’s is just one of the data centres proposed for Alberta. Another one, a gigawatt cluster, would also require a dedicated gas-fired power plant, while Kevin O’Leary’s questionable project is supposed to require over three times the combined power of those other two.
For years, the tech industry told us we did not need to have much concern for how digital products and services worked, and many of us did not bother to find out. But it turns out the demands of our email and Netflix subscription were comparatively easy to hide. At the very least, what we ought to demand from projects with the scale and ambition of these data centres is open disclosure of their power consumption, water use, and emissions.
But we ought to demand more than the bare minimum. Transparency does as much good as a big banner reading we are destroying the planet but we are also creating a lot of value for shareholders. When a single data centre is projected to use about as much power as the entire city of Calgary is currently — Enmax says 1,260 megawatts as of writing — we should have a say in whether that makes sense. A.I. remains a thing that is happening to us rather than with or for us. It is built on assuming consent and asking forgiveness, which has more-or-less worked for the industry and gave it way too much confidence. Tech companies could have spent decades being better corporate citizens. Data centres are just one part, but they are representative of the difference between the stories told by tech companies and the things we can actually know.
I have previously noted I am not a fan of Ed Zitron’s writing on A.I., which I think is driven more often by adherence to narrative than by genuine skepticism. Even so, his newsletter is extremely popular, and occasionally that pays off with honest-to-goodness scoops. Yesterday, he got a big one — a smattering of OpenAI financial documents revealing the company’s spending and earnings for the past two years. In 2024, it made billions of dollars less than it spent — including over a billion dollars on sales and marketing alone — and its 2025 numbers look even worse:
The financial condition of OpenAI is deeply concerning. $38.53 billion in losses are astronomical, and far higher than most believed it would be. Losses also appear to be mounting year-over-year at a dramatic rate, and I’m not sure how this company finds a way toward any kind of sustainability or profitability.
Zitron shared these documents with the Financial Times, which independently verified them, and added some much-needed context. In particular, that whopping $38.5 billion loss accrued in 2025 and highlighted by Zitron — including in his headline — seems far less dramatic:
Before OpenAI’s switch late last year to become a public benefit corporation, investors in the company received convertible interest rights rather than conventional equity. Under US accounting rules, those interests were treated as liabilities and periodically revalued as the company’s valuation increased.
As OpenAI’s worth rose, the increased value of those investor rights created a roughly $30bn charge, added the person. The charge is not expected to recur following the restructuring, they said.
That expense is not something that can be waved away, of course, but it does not seem to be materially related to the company’s actual costs of creating and selling its products. Losses without including that charge were, according to the Times’ “person familiar with the matter”, $8 billion, or roughly 60% more than in 2024. But that is against revenue of $13 billion in 2025, a significant increase over 2024’s $3.7 billion. (OpenAI, in the first three months of 2026, earned $5.7 billion.)
These juicy numbers were republished by outlets like Reuters, the Next Web, Stocktwits, Benzinga, and Startup Fortune. Shamefully, all attributed them solely to the Times without mentioning Zitron’s critical role. These publications — particularly Reuters — should be giving full credit to the original source.
That Zitron now has actual, verified numbers also allows us to check some of his own reporting. For example, in April, he was quite upset that “every outlet has continued to repeat that OpenAI ‘made $13 billion in 2025,’ despite that being very unlikely given that it would have required it to have made $8 billion in a single quarter”. It is unclear to me which outlets Zitron is referring to as I could find just one — Russia Today — using that quoted phrase verbatim.
Even so, Zitron goes on to write about some apparently conflicting numbers reported by Anthropic before concluding:
Though I cannot say for certain, both of these situations suggest that Anthropic and OpenAI are misleading their investors, the media and the general public. If I were a reporter who had written about Anthropic or OpenAI’s revenues previously, I would be concerned that I had published something that wasn’t true, and even if I was certain that I was correct, I would have to consider the existence of information that ran counter to my own. I would be concerned that Anthropic or OpenAI had lied to me, or that they were lying to someone else, and work diligently to try and find out what happened. I would, at the very least, publish that there was conflicting information.
Two days after this article, he again claimed that “every single story about OpenAI’s revenue other than my own reporting (which came directly from Azure) massively overinflates its sales”, which are more like “a mere $2.27 billion in the first half of last year”.
The numbers Zitron now has for OpenAI suggests this narrative is complete hogwash. Yes, these companies leak overly-optimistic annualized run rates, but if that was a factor in the audited financials Zitron obtained, he likely would have mentioned that. He does not — and neither does the Times, for that matter. “Due to the seriousness of this story”, Zitron wrote, “I am not going to do very much editorializing”, so we will see in a later issue of this newsletter whether he acknowledges this self-induced frenzy was all in his head.
This is why I read Zitron’s work in the framework of conspiracy thinking. He accused OpenAI of “massively overinflat[ing] its sales” and “misleading their investors” based on his own calculations using leaked Azure figures. But it turns out OpenAI did, apparently, have that $13 billion in real non-ARR-fudged revenue for last year, and its operating loss is shrinking. Real analysts, not me, can figure out whether this company is on a path to a functional business. Zitron conjured a whole fictional narrative out of misreading some numbers and then, it would seem with this latest update, misunderstanding them again because it is useful for the story. Still, he should be credited for this scoop.
You probably know the gist. Predictions and dire warnings of a future lived in an immersive virtual world had been around for decades before Neal Stephenson solidified the concept in his 1992 novel “Snow Crash”, but Stephenson called it the “metaverse”, and that was important. It was a cautionary tale. Not everyone understood that. The video game Second Life, launched in 2003, provided an early glimpse of the concept in a P.C. environment. Another piece of the puzzle, consumer-grade virtual reality, began to take shape when Oculus was founded in 2012, and shipped a developer-centric version of its virtual reality headset in 2013. The company was acquired by Facebook a year later. Oculus released a few more headsets while Facebook figured out what to do to “truly transform the way we live, work and connect with each other”.
Despite this goal, “metaverse” was not yet part of Facebook’s lingo, though it was in Oculus’vocabulary. A 2015 internal memo from Mark Zuckerberg does not once contain the word despite describing the strategy it was developing. Even “Oculus” was barely mentioned in the company’s quarterly earnings calls around this time. But in the Q1 2018 call (PDF), Zuckerberg laid out a “10-year journey” for why Facebook bought Oculus, saying “every 10 to 15 years or so, there’s a major new computing paradigm”, and it is “very likely that the next one is going to be around virtual and augmented reality”. “One of my great regrets in how we’ve run the company so far is I feel like we didn’t get to shape the way that mobile platforms developed,” Zuckerberg said, explaining that it was important to spend vast sums of money now “in order to build some of the muscles to be competitive” later. Facebook was training for a major battle that would never materialize.
In the weeks after Meta announced it was retreating from its metaverse efforts earlier this year, I revisited this and other earnings calls, plus presentations and other documentation, as I tried to better understand what the metaverse was pitched as compared to what it ultimately became. I wanted to know how something so silly was treated by executive and media figures alike as a sincere directional shift for one of the world’s biggest companies in particular. In hindsight, it feels like a particularly narrow period of hype coinciding with — and, I think, benefitting from — the most urgent years of the COVID-19 pandemic. As enthusiasm deflated, it was almost unnoticeable despite forecasters labelling it an essential next step of the internet — a necessary next frontier.
The obsession with the metaverse seems to have solidified in Silicon Valley after Matthew Ball published an essay in January 2020 in which he forecasted that, at the very least…
…it is likely to produce trillions in value as a new computing platform or content medium. But in its full vision, the Metaverse becomes the gateway to most digital experiences, a key component of all physical ones, and the next great labor platform.
Ball admits “we don’t really know how to describe the Metaverse”, but sets seven criteria that, in general, portray it as an expansion and continuation of our blended physical and digital worlds, without the constraints of a physical space and with its own economy. Most notably, he says it will offer “unprecedented interoperability” between platforms and providers. He also lists eight things it is not, among them: it is not just a virtual world, or virtual reality, or a digital economy, or a new app store, or a new platform. It is more about a set of protocols and ideas that, yes, incorporate all these elements, but the metaverse is not itself these qualities.
Ball published this essay with darkly fortuitous timing. A week earlier, Chinese health authorities had isolated a new strain of coronavirus aggressively spreading in Wuhan; a day before, they published its genetic sequence. Within a couple of months, the world had turned upside down and many of us were suddenly spending our days in a space that felt more virtual than physical. We may have only been working from home — or, at least, those of us who had the option and were not laid off — and socializing over Zoom, all while remembering the last concert we went to or the last time we ate a meal in a restaurant.
In July 2020, Forbes contributor and futurist Cathy Hackl imagined a world — one that was “for certain, it’s coming and it’s a big deal” — that connects augmented reality, neural interfaces, and a whole bunch of assumptions. In this environment, you could merely remember that you need to buy something, and then a virtual vending machine would materialize so you could order that thing. Hackl defines the metaverse as “a future iteration of the internet, made up of persistent, shared, 3D virtual spaces linked into a perceived virtual universe”.
In “The Future is a Dead Mall”, a video essay using Decentraland as a jumping-off point for a discussion of the metaverse, Dan Olson navigates several writers’ conflicting definitions before making the reasonable conclusion it is basically irrelevant:
If you comb through dozens and dozens of definitions of the metaverse you can assemble a web of broad attributes where some are generally agreed upon, while others border on being mutually exclusive. It’s a vague, largely incoherent cloud of ideas that’s malleable enough that basically anything can be called part of the metaverse, a proto-metaverse, or a semi-metaverse.
[…]
When you understand that the metaverse isn’t a distinct invention or construct, but merely a rhetorical proxy for The Future of Technology, then all of this becomes a lot easier to deal with.
I think Olson is largely correct; this is how the term is actually used. But, though not his intent, I think defining “metaverse” in vague terms is favourable to its boosters because it does not hold them to something specific. I think the explanation offered by Mark Zuckerberg in Facebook’s Q2 2021 earnings call (PDF) is actually pretty fair. This was two quarters before the company changed its name, and between prepared remarks and the question period, there were twenty total mentions of “metaverse” on this call.
So what is the metaverse? It’s a virtual environment where you can be present with people in digital spaces. You can kind of think about this as an embodied internet that you’re inside of rather than just looking at. We believe that this is going to be the successor to the mobile internet.
You’re going to be able to access the metaverse from all different devices in different levels of fidelity — from apps on phones and PCs to immersive virtual and augmented reality devices. Within the metaverse, you’re going to be able to hang out, play games with friends, work, create, and more. You’re basically going to be able to do everything that you can on the internet today as well as some things that don’t make sense on the internet today, like dancing.
So, in some ways, exactly like Olson’s definition: “different devices in different levels of fidelity” that let you socialize and do work, just like everything you currently do on the internet — plus dancing. It seems almost halfway toward being normalized in his head, though it feels as alien to read this today as it surely did then. Yet Zuckerberg is getting at something here. Virtual and augmented reality are ways of immersing us in unique environments that radically change how we interact with technology. And on the next quarter’s earnings call (PDF), Zuckerberg expanded:
[…] If you’re in the metaverse every day, then you’ll need digital clothes, digital tools, and different experiences. Our goal is to help the metaverse reach a billion people and hundreds of billions of dollars of digital commerce this decade. Strategically, helping to shape the next platform should also reduce our dependence on delivering our services through
competitors.
Your avatar cannot simply be a picture of you. You will “need digital clothes” for this space. Need.
In addition to building hype among investors during these earnings calls, Facebook was pumping up its metaverse efforts in more general audience settings. In May 2021, CNetpublished a transcript of a thirty-minute Zoom call between Zuckerberg and Scott Stein where the former could wax lyrical about the bonafides of where Meta was at the time — “with the fidelity of experiences that are possible today, to me that just says, wow, in five years this is going to be clearly better on almost all of these fronts for a lot of the things that we do”. Casey Newton, of the Verge, was given by Facebook a copy of an internal meeting in which Zuckerberg told employees the company’s “overarching goal across all of these initiatives is to help bring the metaverse to life”. The two then recorded a soft and cuddly episode of the Vergecast that allows Zuckerberg to play visionary and rattle off the company’s metaverse talking points. “I think over the next five years or so, in this next chapter of our company,” Zuckerberg told Newton, “I think we will effectively transition from people seeing us as primarily being a social media company to being a metaverse company.” By October, Sarah E. Needleman was relaying to readers of the Wall Street Journal the words of Unity Software’s Marc Whitten the imperative for businesses to develop a “metaverse strategy”. “The metaverse is going to be the biggest revolution in computing platforms the world has seen,” said Whitten, “bigger than the mobile revolution, bigger than the web revolution”.
It is not difficult to see the deliberate strategy here. In 2019 and 2020, Facebook was not talking about the metaverse and, though a few commentators connected the just-announced Horizon social world to the concept, it was not treated yet as the inevitable future. As 2021 rolled on, Facebook’s promotional drumbeat grew stronger. Suddenly people were talking about the metaverse, and connecting it all back to Facebook. There was, it would appear, real buzz — enough, at least, for the Journal to find corroborating voices and take it seriously.
Three days after its Q3 2021 earnings call, Facebook held its Connect conference, which is centred around its augmented and virtual reality efforts. This was a big moment. This would be the keynote where the company laid out its metaverse-centric vision, and changed its name to Meta to reflect this new focus, and because it had to. “From now on,” Zuckerberg said, “we’re going to be metaverse-first, not Facebook-first”.
Rewatching this presentation in 2026 is a bizarre experience, not least of which because of how it is shot. Most scenes appear to be green screened with composited animations. Demos are virtually nonexistent, with most representations of the metaverse carrying a disclaimer that they are “not actual product images” and they are “strictly for illustrative purposes only”. Even so, Zuckerberg and other executives at Meta are all-in on hyping up an experience that, at best, only barely resembles what it ended up shipping. In many cases, it is not even close.
There is a Jon Batiste concert visualized as something that could be attended in-person by someone in Los Angeles and in the metaverse by someone in Kyoto, presumably through the glasses each person is wearing. We do not see the performance from their perspective, but the implication is that the virtual viewer would see it from the same or similar perspective to the in-person attendee. Both get invited to a virtual after-party where they can buy NFT-based digital merch and meet Batiste or, at the very least, his avatar. The reality of metaverse concerts is quite different than this concept. In 2024, Meta showed a Sabrina Carpenter performance in Horizon Worlds. The seats were great, but even in this immersive environment, it appears more like a concert film than a unbroken show viewed from a single perspective. Also, I cannot find any record of an after-party or virtual merch.
Zuckerberg touts Horizon Worlds as the place users will go to socialize, and Horizon Workrooms as the virtual environment for their job. The latter has since been completely shut down, while the former was put on ice. In gaming, Zuckerberg was particularly excited about Rockstar’s port of “Grand Theft Auto: San Andreas” which, three years later, Rockstar cancelled before it had been released. He said “remote work is here to stay for a lot of people” in this keynote, less than two years before ordering in-office work three days per week; two years after that, Instagram demanded five days per week in-office. I guess “a lot of people” does not include the people who are building the products that let a lot of other people work remotely. That is a little weird.
The wishcast-a-thon of Connect 2021 was treated by some with an entirely unearned gravitas. Dean Takahashi, of VentureBeat, called it a “historic moment” and compared it to the Manhattan Project. He thought Meta could bring about universal basic income, with Zuckerberg “paying us to use his devices so that we can make a living in his ecosystem”. In a mostly skeptical article in the New York Times, Kevin Roose raised the possibility that Meta’s focus change “could help with the company’s demographic crisis”, and advocated taking it seriously because the company “has found what may be an escape hatch” from “Facebook’s messy, troubled present”.
To mark the occasion, Zuckerberg granted interviews to four publications, all embargoed until after the Connect 2021 video was published. Dylan Byers, for Puck, was left with the understanding that Zuckerberg “doesn’t really care” about press coverage or questions about the legitimacy of this pivot — in a good way. “[I]t’s just that he’s not so bothered by the unrelenting criticism, and near-term and collateral damage,” wrote Byers, “that he’s going to check his ambitions or think twice about whether or not he’s the right person to help usher in the next phase of the internet”. Alex Heath, of the Verge, implicitly acknowledges the role Facebook’s public relations team played in creating the impression of interest in the metaverse, writing “it wasn’t thrust into the mainstream conversation until Zuckerberg started talking about it publicly earlier this year”. Heath did not break any news of note; neither did Matthew Olson, of the Information. The latter did at least contradict Zuckerberg’s protest of the “relatively high fees”, “a nod to the 30% commission” of Apple’s App Store and Google’s Play Store, by stating that while “Zuckerberg didn’t indicate what commission Facebook would charge”, “Oculus’ Quest
Store currently takes 30%”.
The following day, Matthew Ball spoke with Zuckerberg in a live audio session that has since been pulled from Zuckerberg’s Facebook page, though clips remain available on YouTube. A transcript of the conversation reads like a context-free time capsule of that era, with praise for meme stocks, NFTs, and Web3 in concept more than in practice — and, of course, Ball’s writing on the metaverse. (Six months after this interview, the NFT market would well and truly collapse, with peak transactions occurring the month before Ball and Zuckerberg spoke.) Ball raises the subject of the company’s $10 billion annual spending on Reality Labs. Zuckerberg believes “the metaverse can reach a billion people, say, in the next decade, and that there can be supported hundreds of billions of dollars of commerce. And that if that’s the case, then even with relatively modest fees on the transactions that happen in our services, we think that could be a big business”. But Zuckerberg says he does not want to lose too much money, which is being treated as a “somewhat moderating force over the next period that will keep us from being able to make all of the fees maybe as low as we would want to”. The strategy is, to be clear, entirely dependent on a massive groundswell of public interest in a fundamentally new understanding of computing.
(Zuckerberg also takes time in this conversation to note his respect for intellectual property, at least for luxury brands: if “someone can just make a knock-off Gucci sweater, then I don’t think Gucci’s going to feel that good about being in that space, right, or participating in that system”. Just a few years later, Zuckerberg would allegedly approve the use of pirated ebooks for training the company’s artificial intelligence systems. The work of authors, it would seem, is not as concerning as the reaction of luxury brands.)
A few days later, Zuckerberg again eschewed traditional media outlets and sat down for an interview with Sara Dietschy; then, he chose a softer approach in spirit, if not in volume or cadence with professional talking guy Gary Vaynerchuk. Earlier that year, Vaynerchuk had launched his own NFT collection and, not long before speaking with Zuckerberg, had sold five of his paper doodles for $1.2 million at a completely real Christie’s auction, so you could say they are both on the same wavelength:
Vaynerchuk: The extremity of the NFT space is going to be even greater for what that means. It’s almost like our
world is all about to become the fashion industry because we communicate so much through what we wear. The digital version of that is going to have an incredible impact on society.
Zuckerberg: Oh, totally.
Totally. Just like the fashion industry.
In 2022, Meta added support for NFTs in Facebook and Instagram, a project which it discontinued less than a year later. Digital collectibles got a shoutout in the Connect 2021 presentation, had a brief moment in the sun, and were quickly forgotten about. These things are supposed to be building blocks of the metaverse and Meta barely tried.
Meta’s annual commitment that Ball referenced, of $10 billion, represents all Reality Labs spending, including game development, some A.I. investments, and its EssilorLuxottica collaboration. Even so, despite a complete change in corporate priorities explicitly in the direction of the metaverse, Meta’s long-term interest did not match its investment. Here is a chart I made of mentions of “metaverse” in the transcripts of quarterly earnings calls from Q1 2021 — the quarter before its public relations push — through Q1 2026:
Mentions of “metaverse” in Facebook/Meta quarterly earnings calls. Source: company transcripts.
The highest point on that chart is the Q2 2021 earnings call I used earlier for the definition of “metaverse”; the second-highest is Q4 2021, the first earnings call after Connect 2021. The total count includes mentions in Meta’s prepared remarks, plus the question-and-answer period that follows. Investor conference calls are not a perfect proxy for a company’s priorities, but they are indicative. At the very least, for a company that entirely changed course with a new goal — “from now on, we’re going to be metaverse-first” — and a directly relevant name, one might imagine the company and analysts will be similarly eager to discuss how that is going. But no. In Q4 2022, mentions are half that of the year prior. By Q1 2024, neither Meta nor the analysts on the call seem to care all that much — while there were just four mentions of “metaverse”, there were ninety of “A.I.”.
This speaks volumes. It is the kind of thing that makes you wonder if this company was ever serious about this metaverse pivot at all. It seems like it had every intention, sure, but could it ever have executed on its vision? Of the four interviewers chosen for pieces related to Connect 2021, only Ben Thompson even thought to question its feasibility. (Thompson was also the only one to say he was permitted to view a copy of the presentation in advance. I do not know if this means the other three interviewers did not see it and, therefore, could not interrogate it more thoroughly, or if they did see it and simply did not bother to ask.) At the time, Facebook had no track record in building an operating system, barely had any credibility in hardware, and it only kind of created a platform on its “blue site”. (It arguably avoided creating platforms for developers with Instagram and WhatsApp.) This same company was claiming it was launching the successor to the smartphone and the next iteration of the internet. Every one of these chosen interviewers should have been all over this, but they were too distracted by the rebrand and Facebook’s sordid history to notice it was only a concept video more than it was any kind of real concept.
2. The Others
While Meta made itself the face and name of the metaverse, it was far from alone in promising the immersive computing platform of the near-future. Time basically acknowledged this by declaring one of the best inventions of 2021 was the Qualcomm Snapdragon XR2 — a foundational headset chip, rather than Meta’s attempt to build the platform.
In April 2020, Washington Post reporter Gene Park proclaimed the “next version of the Internet is often described as the Metaverse”, going on to confidently explain how it would be built. Of all the companies involved, Park wrote, “it’s Epic Games, with Fortnite, that has the most viable path forward in terms of creating the metaverse”, citing Ball’s seminal metaverse essay.
In April 2021, months before Facebook began asserting its commitment, Epic Games announced it had raised a billion dollars to “support [its] long-term vision for the metaverse” with $200 million of that coming from Sony. A year later, Epic raised another $2 billion, a billion of which again came from Sony, and the other billion from Lego. In 2023, a Lego game was added to Fortnite, which is not really the metaverse as much as it is a nifty Minecraft-like game-within-a-game.
Yet in Epic Games’ telling, it is basically delivering the metaverse already. CEO Tim Sweeney spoke at the 2023 Game Developers Conference about the company’s vision. Since there are around 600 million monthly active users of games, like Fortnite and Minecraft, set in virtual worlds, Sweeney reckoned “we can set aside the crazy hype cycle around NFTs and VR goggles. Yes, these technologies may play a role in the future, but they are not required. This revolution is happening right now.” Sweeney spoke of interconnectedness and open standards that would allow users to move between different spaces in a unified way. “What a user would really like is to be able to buy a cool-looking outfit in one place and take it everywhere they go” Sweeney claimed. (Why do they always mention digital clothes? My theory is because they do not view fashion as having much value beyond a basic assessment that how someone dresses is an expression of identity.) Sweeney describes Fortnite, Unreal Engine, and the Epic Games Store as “on-ramps to the metaverse”, and that the users of which already understand their in-game socialization can be extended to “going to a concert and dancing” in a virtual environment. Leaving aside the contradiction with definitions of the metaverse that mandate a more immersive environment, it is a big leap to think a brief animation of Eminem scratches the same itch as an actual performance.
Microsoft, as ever ahead of a trend without fully conceptualizing it, said it was doing metaverse stuff before Facebook started referencing it in public. Satya Nadella, defining the metaverse as “made up of digital twins, simulated environments, and mixed reality”, claimed a mix of Azure features, HoloLens, and Mesh would allow enterprises to get aboard. Last year, Microsoft said it was getting out of V.R. hardware and turning its mixed reality collaboration product into a glorified Snapchat filter in Teams.
Then there is Roblox. When Andreessen Horowitz announced its investment in the company, Marc Andreessen and David George wrote that “[w]hile pundits have been distracted by the readiness debates and questions over V.R. vs. A.R., the foundations of a global metaverse have been quietly built in the background… in Roblox”. This was in February 2020 — before Epic Games, before Microsoft, and well before Meta said anything in public about the metaverse. In January 2021, as part of Wired’s predictions for the coming year, Roblox CEO David Baszucki confidently predicted “the metaverse will experience widespread use, and start to become a human co-experience utility”. In March, the company went public at a $30 billion valuation. After Facebook changed its name to Meta, Baszucki saw that as validation of its strategy. That November, he made the rounds on business television networks like Bloomberg and CNBC to advocate for the company as a trailblazer.
In January 2022, Bernhard Warner of Fortune was getting excited about the possibilities of the metaverse, writing it “might be the most important trend in tech since the iPhone”, perhaps “a tectonic shift in tech that they [big tech and big investors] can’t afford to miss”. The way Roblox was “monetizing the metaverse” was a key piece of evidence, with virtual concerts and — most importantly — brands. “A parade of consumer brands […] have set up a presence on Roblox in the past year”, wrote Warner, citing Nike’s approach as being particularly exciting. A month earlier, it had acquired a company called RTFKT, which its press release extolled was a “leading brand that leverages cutting edge innovation to deliver next generation collectibles”. Guggenheim Securities, a subsidiary of Guggenheim Partners which has over $350 billion in assets under management, said it was the “‘best idea’ of 2022”, according to Warner. People are going to need virtual outfits, right? Yet, just three years later, Nike shut down RTFKT.
Gucci, another of the brands with a virtual presence in Roblox, sold virtual handbags for in-game currency for a limited time in 2021 and 2022; users realized they could effectively counterfeit and resell them. At least one of Zuckerberg’s predictions kind of came true. And, while Warner highlighted Disney as another company with in-game presence, it has not maintained a meaningful investment because, according to Variety, it feels Roblox is unsafe for children, a sentiment that was not helped when Baszucki appeared on the “Hard Fork” podcast. Roblox has settled lawsuits with the attorneys general of Nevada, Alabama, and West Virginia over accusations its platform features enabled child exploitation by other users. Roblox has denied any wrongdoing though it says it is enabling better parental controls and tighter restrictions on children’s accounts.
Through 2021 and 2022, the metaverse hype cycle was apparent across the tech industry. Max A. Cheney, reporting for Barron’s in August 2021, noted “[m]entions of the metaverse in earnings transcripts and other corporate documents are up five times this year compared with 2020, according to data from Sentieo”. This relative figure must have a hilariously low baseline, sure, but it is an indicator of how many businesses became briefly enchanted by this concept. There were serious financial analyses of real estate in the metaverse. Keep in mind that what is meant by “real estate” is much, much, much closer to domain names than it is land and deed. In July 2022, Technavio, a market research company, forecasted this market would be worth $5.37 billion by 2026. This report was picked up by Debra Kamin, of the New York Times, who published an article in the paper’s real estate section in February 2023 explaining this “new frontier for real estate builders and investors”. The primary anecdote in Kamin’s story is a just-completed mansion in Florida with a “twin” in a metaverse platform called the Sandbox. “As these technologies get more immersive”, the homebuilder said, “it’s going to make a lot more sense” to have a 3D virtual model of a house. Kamin was not breaking news on this specific story, as it was first reported by Emma Reynolds, of Forbes, over a year earlier. One would think that Kamin could therefore have asked some more probing questions or surveyed the actual market for NFTs which, by 2023, had fallen off a cliff. But no. Instead, the builder got the imprimatur of the Times describing the combined physical and digital sale in flattering terms. Ultimately, neither the listing nor many of the sale notices mentioned the sole marketing quirk of this house, suggesting that by 2023 the novelty of a digital model of a mansion was kind of over. I was curious if the NFT was a factor in the buyer’s decision, but did not receive a response to requests for comment I sent to a phone number associated with the current owner of the property.
Both the Times and Forbes articles are individual disasters in their own right. Sure, we might not expect a pinacle of journalistic integrity from Forbes and, to a lesser extent, the unabridged property ads that form the real estate section in prestigious newspapers including the Times. But to communicate this nonsense with the framing of “real estate” is treating wild speculation with unearned seriousness. This project was also co-signed by Sotheby’s. The whole thing is an embarrassing validation of a market that, predictably, would prove to have no substance. This was obvious by the time the metaverse mansion was being peddled. Eric Ravenscraft, in Wired in December 2021, reported that the attempts at artificial scarcity “more closely resembles early-access video games and common pump-and-dump schemes” than a real estate market. Indeed, a Coingecko analysis found metaverse “land” was worth 34% less in 2024 compared to the year prior, and 72% less than at its peak in 2022. This was an average across several platforms, and the biggest decline was in the Sandbox, the digital home of that mansion’s 3D model twin. According to a CoinDesk report published last year, the Sandbox laid off half its employees and its token has dropped in value from its peak by 90%. As of March 2026, user rights to space in Sandbox and Decentraland — another metaverse platform — that had originally sold for hundreds-of-thousands to millions of dollars were not a market totalling $5.37 billion as forecasted by Technavio. They had become basically worthless.
3. Fever Dream
Officially, Meta is still all-in on the concept around which it pivoted the entire company in 2021. It still has a whole marketing page proclaiming its belief “in the future of connection in the metaverse”. You can go shop its lineup of Quest headsets which Meta says represent the best and most immersive metaverse experience, though its flagship model is now two-and-a-half years old. It has awkwardly promoted its Ray-Bans as “A.I. glasses” despite them becoming the company’s most successful line of mixed reality products, and it is desperately trying to connect its newest muse of A.I. with its last one. The single mention of “metaverse” on its Q1 2026 earnings call (PDF) is when Zuckerberg claimed to be “excited for more of our metaverse efforts to be powered by the A.I. models we’re training as well”. If you want to be unfairly generous in your interpretation of Zuckerberg’s brief remark, you could point to a December 2020 Andreessen Horowitz piece, in which general partner Jonathan Lai refers to this shape as a “pyramid”, and says that “fully A.I.-created content” is directly correlated with “spontaneous social at metaverse scale”. Obviously. I am not feeling generous.
Others in the space have not fared much better. Roblox has not mentioned the word “metaverse” in its quarterly or annual reports since Q1 2022 (PDF). Epic Games scarcely mentions it in recent news releases, either: since January last year, just one announcement contains the word “metaverse”, while seven are dedicated to the lawsuits Epic has been fighting against Apple and Google. Far from the inevitable next chapter of the internet, the metaverse, supposedly the future of how we live, work, and play online, is a non-event.
Near the end of the Connect 2021 presentation, Nick Clegg, then Meta’s global affairs chief, said “the metaverse isn’t something we’re building, so much as it’s something we’re building for”. Olson, in his video, wryly notes that, in the eyes of its promoters, “the metaverse cannot fail; you can only fail to make the metaverse”. The metaverse is so inevitable that “you might even already be in it”, according to Barron’s. But the metaverse is not predestined; it never has been. It is a construction of tech companies that saw in the pandemic their future — not ours.
A slightly charitable interpretation of what I think the pandemic demonstrated to Facebook executives, for example, was how invaluable technology companies were in maintaining connections even when most people could not do so in-person. They recognized how much time people were spending in front of screens already, even in years prior, and assumed that could be a more social experience.
But a more cynical view is no less fair. With the pandemic undoubtably came a realization of how much money Facebook stood to make, if only it had a platform. In 2019, there were two publicly traded companies worth over a trillion U.S. dollars; by the end of 2021, there were five, with Apple and Microsoft now worth over two trillion dollars each. This pandemic was not going to last forever — but it did not need to. Our world was permanently changed, or so it would have seemed, and we would surely want to virtually attend concerts and buy PNG files of band t-shirts with real money. And these companies would take their cut.
One thing I have mentioned but did not emphasize is just how often Zuckerberg and Sweeney mention Apple and Google platform fees as a primary justification for building the metaverse. Sweeney spent several years fighting lawsuits against both companies, mostly winning the one against Google and mostly losing the one against Apple. His efforts have, nevertheless, shined a spotlight on these grotesque practices. But it would be a mistake to assume this is an objection on ideological grounds. These guys just want to take those commissions for themselves. Sweeney spent his GDC 2023 presentation comparing the need for open standards in the metaverse to the openness of the web, but unlike the web, the Epic Games store takes a 12% commission. Meta beat that, though; it even beat Apple and Google. By the time the individual fees are added together, transactions made through Horizon Worlds could be levied a commission of up to 47.5%. The money thing is not even a secret; it was often the very first thing people like Zuckerberg and Sweeney discussed in interviews about their metaverse plans. This was a financial decision before it was a product or service people might actually want to use.
It would not be fair to characterize Meta’s endeavour as an impulsive flash in the pan. Zuckerberg laid out his vision in a 2015 internal memo in which he explained how the company “would like a stronger strategic position in the next
wave of computing”. Then, in January 2017, the Chan Zuckerberg Initiative acquired a company called Meta, I think mostly for the name; a year later, Zuckerberg floated the idea of a rebrand. The 2015 memo that effectively set this whole thing into motion gives the impression of a surprisingly cogent document if you set aside the wildly optimistic timelines — “VR/AR will be the next major computing platform after mobile in about 10 years” — and the idea that virtual and augmented reality are so compelling it will supersede the desire for phones and televisions. If anything, the unearned confidence in this memo should have been alarming at the time. As Zuckerberg himself writes, the “core social networking work is no longer new, Internet.org is extending something rather than inventing it, and A.I. is not yet tangible”. This is not a company known for doing new, and it is now stuck with a name reflecting a bungled attempt to change that. Staff are not happy after years of mass layoffs, court losses, role reassignments, and internal surveillance to feed the company’s A.I. projects. Do not get me wrong — Meta’s business of collecting vast amounts of information about its users and selling relevant ad slots is as strong as it has ever been. But Meta the ad company is not Meta the platform innovator.
And this feels like the why of it all. If tech companies can channel a meaningful sliver of our entire lived experience into a world of their creation, one where they collect a portion of revenue, it would make them inescapable. Ball, Sweeney, and Zuckerberg may have all written or spoken about the importance of interoperability and open standards, but these platforms want to exercise a degree of control more similar to native software than to the open web. The steps for migrating from Horizon Workrooms to a competitor’s product, for instance, are not what one would expect if openness were a priority.
For a brief couple of years, it seemed like there could be enough enthusiasm from reporters in the space, venture capitalists, and executives to make the metaverse happen. Then ChatGPT launched in November 2022, and the pandemic ended in the U.S. in May 2023, and any interest anyone may have had for spending more time with people in a virtual setting largely evaporated. It turns out we are okay with having meetings and playing games online, but we actually like seeing live music in-person and travelling to real places. The problems each of these things may have — high costs, environmental impact, and so on — are notable and real, but are not ones with metaverse-based solutions.
The pandemic did not make the metaverse. There was sufficient interest in developing it well before then, and it is possible all of these companies would have announced all these products and services on the same timeline. But in a world without a pandemic, I cannot imagine anyone would have treated these metaverse announcements with anything like the seriousness they did. The pandemic officially ended in the U.S. just six months after the first release of ChatGPT, so it is impossible to disentangle the influence of either. But it is notable to me that the nosedive in mentions of “metaverse” on Meta’s investor calls occurred in Q3 2023 — the quarter immediately following the declared end of the pandemic.
As for the futurists like Hackl, who confidently proclaimed the metaverse was “for certain”, they have found an out thanks to its flexible definition. Jeff Barrett, of the Shorty Awards’ “It’s No Fluke” podcast, published a glowing profile of “the Godmother of the Metaverse” earlier this year under the headline “Why Cathy Hackl Keeps Getting the Future Right”. “When enthusiasm cooled and narratives collapsed, many distanced themselves from the space”, writes Barrett, noting with seeming approval that “Hackl did the opposite. She reframed it”. Many people — perhaps everyone, come to think of it — could predict the future if they got to retcon their predictions to fit reality.
There are many open questions about the metaverse; most glaringly among them, whether it could actually become a thing for normal people. That depends a little bit on what definition we use. If it simply means the slow erosion of the boundary between our physical and digital environments, that is probably something that will continue to happen. For most people, though, that does not look like Meta’s Connect 2021 concept animations. Whatever that ends up being will probably be the result of people finding something useful and intriguing about doing something different. It will not be the product of big companies redirecting the money hose of platform fees onto themselves.
With thanks to Marquette University for granting me access to the Zuckerberg Files. A frustrating number of Zuckerberg’s post-Meta interviews are video-based, so the transcripts produced by this effort were invaluable. Where possible, I have checked these copies against the originals.
Apple Inc. plans to open Siri to outside artificial intelligence assistants, a major move aimed at bolstering the iPhone as an AI platform.
The company is preparing to make the change as part of a Siri overhaul in its upcoming iOS 27 operating system update, according to people with knowledge of the matter. The assistant can already tap into ChatGPT through a partnership with OpenAI, but Apple will now allow competing services to do the same.
This is not unexpected. In the Apple Intelligence introduction at WWDC 2024, Craig Federighi said “we want you to be able to use these external models without having to jump between different tools”, and that they were “starting” with ChatGPT. Gurman points this out and also notes Federighi’s teased Google Gemini integration. Tim Cook, in an October 2025 earnings call, said much the same. (Gurman also notes that this integration is “separate from Apple’s work with Google to rebuild Siri using Gemini models”, but “the news initially weighed on shares of Google”, which I am sure is exactly the reason for them dropping 3.4% and nothing to do with an existing weeklong slide but, then again, I do not work at Bloomberg so who the hell am I to say?)
Gurman, in his “Power On” newsletter over the weekend, further explored what he calls Apple “doubl[ing] down” on a “revamped A.I. and Siri strategy”:
That reality is shaping the company’s new approach, set to be unveiled at the Worldwide Developers Conference on June 8. Rather than engaging in an AI arms race, Apple is focusing on its core strengths: selling highly profitable hardware and making money off the services that run on it.
Historically, Apple’s software — iMessage, Maps and Photos, for example — has been about driving product sales rather than generating revenue in their own right. Rivals, in contrast, are aggressively monetizing AI through subscriptions and premium apps. Apple understands that few, if any, users will pay for Siri or its other AI technology. The opportunity to turn Apple Intelligence into a moneymaker has effectively passed.
What would have been more newsworthy here is if Apple’s A.I. strategy were anything other than building software exclusively for its proprietary hardware. This does not sound like a “revamped” strategy; it sounds like Apple’s whole deal. If it can use Apple Intelligence or Siri in the future, it certainly might; it is putting ads in Apple Maps after all. Services is a money-printing machine with less risk. But it is still a hardware company.
This part made me double-take and wonder if I missed something. In February 2024, following Apple’s cancellation of its car project, Gurman predicted that hardware would continue to be Apple’s primary business “for now”, as though that will change in the near future. This has been constant since Apple Intelligence was announced at WWDC that year.
What one could argue has been a change of strategy is the rumoured development of a chatbot; Gurman called it a “strategic shift” when he broke the news. But that, too, is somewhat inaccurate in two ways: Gurman’s description of it is as an overhauled version of Siri that will let people do normal Siri stuff — setting timers, end of list — plus some of the features Apple announced in 2024 but has not yet shipped which, confusingly, were also first set to ship in an update to iOS 26 without the wholly new version of Siri but also depending on Gemini. Got it?
But even that is not much of a strategy shift. Gurman tweeted in May 2024 — before WWDC and the debut of Apple Intelligence — that “Apple isn’t building its own chatbot but knows the market wants it so it’s going elsewhere for it. It’s the same playbook as search.” So, again, it is just borrowing from its ages-old playbook. It will continue to have proprietary stuff that ostensibly works seamlessly across a user’s Apple-branded hardware, allow installation of third-party add-ons, and rely on Google for some core functionality. How, exactly, is this a “revamp”?
Anyway, here is what Gurman wrote in January after the Gemini announcement and before the first build of iOS 26.4 was released:
Today, Apple appears to be less than a month away from unveiling the results of this partnership. The company has been planning an announcement of the new Siri in the second half of February, when it will give demonstrations of the functionality.
Whether that takes the form of a major event or a smaller, tightly controlled briefing — perhaps at Apple’s New York media loft — remains unclear. Either way, Apple is just weeks away from finally delivering on the Siri promises made at its Worldwide Developers Conference back in June 2024. At long last, the assistant should be able to tap into personal data and on-screen content to fulfill tasks.
Apple today shipped the first build of iOS 26.5 to developers without any sign of those features. While they may come in a later build, Juli Clover, of MacRumors, speculates they have been kicked to iOS 27.
Sometimes, I do not recognize a trap until I am already in it. Photos in iCloud is one such situation.
When Apple launched iCloud Photo Library in 2014, I was all-in. Not only is it where I store the photos I take on my iPhone, it is where I keep the ones from my digital cameras and my film scans, and everything from my old iPhoto and Aperture libraries. I have culled a bunch of bad photos and I try not to hoard, but it is more-or-less a catalogue of every photo I have taken since mid-2007. I like the idea of a centralized database of my photos, available on all my devices, that is functionally part of my backup strategy.1
But, also, it is large. When I started putting photos in there eleven years ago with a 200 GB plan, I failed to recognize it would become an albatross. iCloud Storage says it is now 1.5 TB and, between the amount of other stuff I have in iCloud and my Family Sharing usage, I have just 82 GB of available space. 2 TB seemed like such a large amount of space until I used 1.9 of it.
Apple’s next iCloud tier is a generous 6 TB, but it costs another $324 per year. I could buy a new 6 TB hard disk annually for that kind of money. While upgrading tiers is, by far, the easiest way to solve this problem, it only kicks that can down that road, the end of which currently has whatever two terabytes’ worth of cans looks like.
A better solution is to recognize I do not need instant access to all 95,000 photos in my library, but iCloud has no room for this kind of nuance. The iCloud syncing preference is either on or off for the entire library.
Unfortunately, trying to explain what goes wrong when you try to deviate from Apple’s model of how photo libraries ought to work will become a bit of a rant. And I will preface this by saying this is all using Photos running on MacOS Ventura, which is many years behind the most recent version of MacOS. It is not possible for me to use the latest version of Photos to make these changes because upgraded libraries cannot be opened by older versions of Photos. However, in my defense, I will also note that the version on Ventura is Photos 8.0 and these are the kinds of bugs and omissions inexcusable after that many revisions.
So: the next best thing is to create a separate Photos library — one that will remain unsynced with iCloud. Photos makes this pretty easy by launching while holding the Option (⌥) key. But how does one move images from one library to the other? Photos is a single-window application — you cannot even open different images in new windows, let alone run separate libraries in separate windows. This should be possible, but it is not.
As a workaround, Apple allows you to import images from one Photos library into another — but not if the source library is synced with iCloud. You therefore need to turn off iCloud sync before proceeding, at which point you may discover that iCloud is not as dependable as you might have expected.
I have “Download Originals to this Mac” enabled, which means that Photos should — should — retain a full copy of my library on my local disk. But when I unchecked the “iCloud Photos” box in Settings, I was greeted by a dialog box informing me that I would lose 817 low-resolution local copies, something which should not exist given my settings, though reassuring me that the originals were indeed safe in iCloud. There is no way to know which photos these are nor, therefore, any way to confirm they are actually stored at full resolution in iCloud. I tried all the usual troubleshooting steps. I repaired my library, then attempted to turn off iCloud Photos; now I had 850 low-resolution local copies. I tried a neat trick where you select all the pictures in your library and select “Play Slideshow”, at which point my Mac said it was downloading 733 original images, then I tried turning off iCloud Photos again and was told I would lose around 150 low-resolution copies.
You will note none of these numbers add or resolve correctly. That is, I have learned, pretty standard for Photos. Currently, it says I have 94,529 photos and 898 videos in the “Library” view, but if I select all the items in that view, it says there are a total of 95,433 items selected, which is not the same as 94,529 + 898. It is only a difference of six items but, also, it is an inexplicable difference of six.
At this point, I figured I would assume those 150 photos were probably in iCloud, sacrifice the low-resolution local copies, and prepare for importing into the second non-synced library I had created. So I did that, switched libraries, and selected my main library for import. You might think reading one Photos library from another stored on the same SSD would be pretty quick. Yes, there are over 95,000 items and they all have associated thumbnails, but it takes only a beat to load the library from scratch in Photos.
It took over thirty minutes.
After I patiently waited that out, I selected a batch of photos from a specific event and chose to import them into an album, so they stay categorized. Oh, that is right — just because you are importing across Photos libraries, that does not mean the structure will be retained. There is no way, as far as I can tell, to keep the same albums across libraries; you need to rebuild them.
After those finished importing, I pulled up my main library again to do the next event. You might expect it to retain some memory of the import source I had only just accessed. No — it took another thirty minutes to load. It does this every time I want to import media from my main library. It is not like that library is changing; it is no longer synced with iCloud, remember. It just treats every time it is opened as the first time.
And it was at this point I realized the importer did not display my library in an organized or logical fashion. I had expected it to be sorted old-to-new since that is how Photos says it is displayed, but I saw photos from many different years all jumbled together. It is almost in order, at times, but then I would notice sequential photos scattered all over.
My guess — and this is only a guess — is that it sub-orders by album, but does no further sorting after that. This is a problem for me given a quirk in my organizational structure. In addition to albums for different events, I have smart albums for each of my cameras and each of my iPhone’s individual lenses. But that still does not excuse the importer’s inability to sort old-to-new. The event I spotted early on and was able to import was basically a fluke. If I continued using this cross-library importing strategy, I would not be able to keep track of which photos I could remove from my main library.
There is another option, which is to export a selection of unmodified originals from my primary library to a folder on disk, and then switch libraries, and import them. This is an imperfect solution. Most obviously, it requires a healthy amount of spare disk space, enough to store the selected set of photos thrice, at least temporarily: once in the primary library, once in the folder, and once in the new library. It also means any adjustments made using the Photos app will be discarded — but, then again, importing directly from the library only copies the edited version of a photo without any of its history or adjustments preserved.
What I would not do, under any circumstance — and what I would strongly recommend anyone avoiding — is to use the Export Photos option. This will produce a bunch of lossy-compressed photos, and you do not want that.
Anyway, on my first attempt of trying the export-originals-then-import process, I exported the 20,528 oldest photos in my library to a folder. Then I switched to the archive library I had created, and imported that same folder. After it was complete, Photos said it had imported 17,848 items, a difference of nearly 3,000 photos. To answer your question: no, I have no idea why, or which ones, or what happened here.
This sucks. And it particularly sucks because most data is at least kind of important, but photos are really important, and I cannot trust this application to handle them.
There is this quote that has stuck with me for nearly twenty years, from Scott Forstall’s introduction to Time Machine (31:30) at WWDC 2006. Maybe it is the message itself or maybe it is the perfectly timed voice crack on the word “awful”, but this resonated with me:
When I look on my Mac, I find these pictures of my kids that, to me, are absolutely priceless. And in fact, I have thousands of these photos.
If I were to lose a single one of these photos, it would be awful. But if I were to lose all of these photos because my hard drive died, I’d be devastated. I never, ever want to lose these photos.
I have this library stored locally and backed up, or at least I though I did. I thought I could trust iCloud to be an extra layer of insurance. What I am now realizing is that iCloud may, in fact, be a liability. The simple fact is that I have no idea the state my photos library is currently in: which photos I have in full resolution locally, which ones are low-resolution with iCloud originals, and which ones have possibly been lost.
The kindest and least cynical interpretation of the state of iCloud Photos is that Apple does not care nearly enough about this “absolutely priceless” data. (A more cynical explanation is, of course, that services revenue has compromised Apple’s standards.) Many of these photos are, in fact, priceless to me, which is why I am questioning whether I want iCloud involved at all. I certainly have no reason to give Apple more money each month to keep wrecking my library.
I will need to dedicate real, significant time to minimizing my iCloud dependence. I will need to check and re-check everything I do as best I can, while recognizing the difficulty I will have in doing so with the limited information I have in my iCloud account. This is undeniably frustrating. I am glad I caught this, however, as I sure had not previously thought nearly as much as I should have about the integrity of my library. Now, I am correcting for it. I hope it is not too late.
It is no longer the sole place I store my photos. I have everything stored locally, too, and that gets backed up with Backblaze. Or, at least, I think I have everything stored locally. ↥︎
In a WWDC 2011 session, Dan Schimpf explained some of the goals of the refreshed design for Aqua in Mac OS X Lion were “meant to focus the user attention on the active window content”. This sentiment was echoed by John Siracusa in his review of Lion for Ars Technica:
Apple says that its goal with the Lion user interface was to highlight content by de-emphasizing the surrounding user interface elements.
[…] a fresh modern look where controls are clearer, smarter and easier to understand, and streamlined toolbars put the focus on your content without compromising functionality.
Then, when it revealed the Big Sur redesign in 2020, it explained:
The entire experience feels more focused, fresh, and familiar, reducing visual complexity and bringing users’ content front and centre.
And you will never guess what it promised in 2025 with the announcement of MacOS Tahoe and Liquid Glass, as introduced by Alan Dye:
Our goal is a beautiful new design that brings joy and delight to every user experience. One that’s more personal, and puts greater focus on your content — all while still feeling instantly familiar.
It is not just Apple, either. Here is Microsoft’s Jensen Harris at Build 2011 describing a key goal for the company’s then-new Metro design language:
Metro-style apps have room to breathe. They’re not about the chrome, they’re about the content. […] For years, Windows was always about adding stuff. We added bars, and panes, and doodads, and widgets, and gadgets, and bars — and stuff everywhere. And that’s how we defined our U.I., based on what new widgets we added. Now, we’ve receded into the background, and the app is sitting out there on the stage.
And later, as Microsoft rolled out app updates with its Fluent Design language, it described them in familiar terms:
With the updated OneDrive, your content takes center stage. The improved visual design reduces clutter and distractions, allowing you to focus on what’s important – your content.
This is a laudable goal if the opposite is, I assume, increasing the amount of clutter in user interfaces and making them more distracting. Nobody wants that. Then again, while the objective may be quite reasonable, there are surely different ways of achieving it — but Apple has embraced a single strategy: make the interface blend into the document. (I will be focusing on MacOS here as it is the platform I am most familiar with.)
Here is what a Pages document looks like running under Mac OS X Lion:
Click to expand (except on mobile).
Here is that same document in a newer version of Pages running on MacOS Catalina, with the Yosemite-era design language that replaced the one that came before:
Click to expand (except on mobile).
Here it is in the last version of Pages on MacOS Tahoe, using the design language introduced with Big Sur:
Click to expand (except on mobile).
And, finally, the newest version of Pages on MacOS Tahoe using the current Liquid Glass visual design language:
Click to expand (except on mobile).
There are welcome improvements in newer versions of this comparison, like the introduction of the “Format” panel on the right-hand side, which makes better use of widescreen landscape-oriented displays, and allows for larger controls. While I admire the density of the Lion-era screenshot, the mini-sized controls in that formatting menu are harder to click.1
Overall, however, what Apple has done to Pages over this period of time is representative of a broader trend of minimizing the delineation of user interface elements from each other and the document itself. This is the only tool in the toolbox, and I am skeptical it achieves what Apple intends.
Compare again the two more recent screenshots against the ones that came before, and focus on the toolbar at the top of each. In the older two, there is a well-defined separation between the toolbar — the window itself — and the document. In the Big Sur visual language, however, the toolbar is the same bright white as the document. By Tahoe and the Liquid Glass language, there is barely a distinction; the buttons simply float over the document. And, bizarrely, that degrades further with the “Reduce Transparency” accessibility preference enabled:
Click to expand (except on mobile).
(Also, no, your eyes do not deceive you: the icons in the drop cap menu, barely visible in the lower-right, are indeed pixellated.)
For me, this means a constant distraction from my document because the whole window has a similar visual language. As the toolbar and its buttons become one with the document, they lose their ability to fade into the background. In the two older examples, the contrast of the well-defined toolbar allows me to treat them as an entirely separate thing I do not need to pay attention to.
This is further justified by the lower contrast within those two older toolbars. In Lion, the grey background and moderately saturated colours are a quiet reminder of tools that are available without them being intrusive. The mix of shapes is a sufficient differentiator, something Apple threw away in the following screenshot. By making all the buttons literal and with the same bright background, the toolbar becomes a little more distracting — but at least it does not blend into the document. Without the context of the previous screenshot, the colours of each icon seem almost random, and I find the yellow-on-white “Table” button difficult to distinguish at a glance from the black-on-yellow-on-white “Comment” button.
The Big Sur-era design language is, frankly, an atrocious regression. The heterogeneous shapes may have returned, but in the form of monochromatic medium-grey icons set against a uniform white background. The icons are not bad, per se — though putting “Add Page” and “Insert” next to each other in this default toolbar layout, both represented by a plus sign, is a little confusing. But I will bet you would not guess that some of these are buttons, while others are pop-up buttons with a submenu.
Finally, there is Liquid Glass which, in its default form, has more contrast than the previous example; with “Reduce Transparency” enabled, which is how I use MacOS, it has even less. The buttons themselves have a greater amount of internal contrast with bigger, darker grey icons on a white background. This is preferential within the context of the toolbar compared to the thin, small, and low-contrast buttons in the past example, but it also means this toolbar has similar contrast to the document itself.
I would not go so far as to argue that Pages ’09 has a perfect user interface and that everything since has been a regression. The average colours used for the icon fill in both older toolbars generally fails accessibility contrast checks which, remarkably, the Big Sur design will pass. The icons in Pages ’09 rely on dark outlines and unique shapes to have sufficient contrast with the toolbar background. However, Apple has since discarded most variables it could change to design these interfaces. Every button contains an icon of a single uniform colour, within barely defined holding containers of the same shape, and without text labels by default.
This monochromatic look means any splash of colour is distracting. The yellow accent used in Pages is garish — though, thankfully, something that can mostly be mitigated by changing the Theme Colour in System Settings, under Appearance. (Unfortunately, the yellow background remains on the “Update” button in the most recent version of Pages regardless of the system accent colour.) But perhaps you also noticed the purple icon in the Liquid Glass screenshot above. Here is the full toolbar:
Click to expand (except on mobile).
Those purple icons signify features that are part of Apple Creator Studio, a paid subscription to Pages and other applications that allows you to — in the order they are presented above — generate an image, artificially boost the resolution of an image, and access a stock image library. If you would like to insert one of your own images into your Pages document, that feature has been moved to the paperclip icon. Yes, it is a menu and not a button, despite lacking the disclosure triangle of the zoom menu right beside it, and it also reminds you about the “Content Hub” and “Generate Image” features. In Pages under Lion, colour was used in the icons to help guide the user as they complete a task — click the green thing to add a shape; click the darker yellow thing to add a table. Colour is not being used in the newer version to signify these are A.I. features, as the “Writing Tools” icon remains dark grey. In this version, the coloured icons are there to guide the user to premium add-ons regardless of whether they are currently paying for them.
I decided to focus on Pages for this comparison because it has lived so many different lives in MacOS. However, it is perhaps an imperfect representation for the rest of the system. Across Mac OS X Lion, for example, the toolbars of first-party applications like Finder and Preview almost exclusively use monochromatic icons. This has been true since Mac OS X Leopard, which also introduced barely differentiated folder icons. Some toolbars in Tiger, introduced two years prior, featured icons inside uniform capsule shapes. These were questionable ideas at the time, but they still retained defining characteristics. The capsules, for example, may have had a uniform shape, but contained within were full-colour icons. Most importantly, they were all clearly controls that were differentiated from the document.
Perhaps Apple has some user studies that suggest otherwise, but I cannot see how dialling back the lines between interface and document is supposed to be beneficial for the user. It does not, in my use, result in less distraction while I am working in these apps. In fact, it often does the opposite. I do not think the prescription is rolling back to a decade-old design language. However, I think Apple should consider exploring the wealth of variables it can change to differentiate tools within toolbars, and to more clearly delineate window chrome from document.
These screenshots are a bit limited as, to capture a high-resolution interface, I switched my mid-2012 MacBook Air to a 720 × 450 display output, which shrank the available space for Pages in the Lion and Catalina screenshots. ↥︎
On November 20th American statisticians released the results of a survey. Buried in the data is a trend with implications for trillions of dollars of spending. Researchers at the Census Bureau ask firms if they have used artificial intelligence “in producing goods and services” in the past two weeks. Recently, we estimate, the employment-weighted share of Americans using AI at work has fallen by a percentage point, and now sits at 11% (see chart 1). Adoption has fallen sharply at the largest businesses, those employing over 250 people. Three years into the generative-AI wave, demand for the technology looks surprisingly flimsy.
[…]
Even unofficial surveys point to stagnating corporate adoption. Jon Hartley of Stanford University and colleagues found that in September 37% of Americans used generative AI at work, down from 46% in June. A tracker by Alex Bick of the Federal Reserve Bank of St Louis and colleagues revealed that, in August 2024, 12.1% of working-age adults used generative AI every day at work. A year later 12.6% did. Ramp, a fintech firm, finds that in early 2025 AI use soared at American firms to 40%, before levelling off. The growth in adoption really does seem to be slowing.
I am skeptical of the metrics used by the Economist to produce this summary, in part because they are all over the place, and also because they are mostly surveys. I am not sure people always know they are using a generative A.I. product, especially when those features are increasingly just part of the modern office software stack.
While the Economist has an unfortunate allergy to linking to its sources, I wanted to track them down because a fuller context is sometimes more revealing. I believe the U.S. Census data is the Business Trends and Outlook Survey though I am not certain because its charts are just plain, non-interactive images. In any case, it is the Economist’s own estimate of falling — not stalling — adoption by workers, not an estimate produced by the Census Bureau, which is curious given two of its other sources indicate more of a plateau instead of a decline.
The Hartley, et al. survey is available here and contains some fascinating results other than the specific figures highlighted by the Economist — in particular, that the construction industry has the fourth-highest adoption of generative A.I., that Gemini is shown in Figure 9 as more popular than ChatGPT even though the text on page 7 indicates the opposite, and that the word “Microsoft” does not appear once in the entire document. I have some admittedly uninformed and amateur questions about its validity. At any rate, this is the only source the Economist cites which indicates a decline.
The data point attributed to the tracker operated by the Federal Reserve Bank of St. Louis is curious. The Economist notes “in August 2024, 12.1% of working-age adults used generative A.I. every day at work. A year later 12.6% did”, but I am looking at the dashboard right now, and it says the share using generative A.I. daily at work is 13.8%, not 12.6%. In the same time period, the share of people using it “at least once last week” jumped from 36.1% to 46.9%. I have no idea where that 12.6% number came from.
Finally, Ramp’s data is easy enough to find. Again, I have to wonder about the Economist’s selective presentation. If you switch the chart from an overall view to a sector-based view, you can see adoption of paid subscriptions has more than doubled in many industries compared to October last year. This is true even in “accommodation and food services”, where I have to imagine use cases are few and far between.
After finding the actual source of the Economist’s data, it has left me skeptical of the premise of this article. However, plateauing interest — at least for now — makes sense to me on a gut level. There is a ceiling to work one can entrust to interns or entry-level employees, and that is approximately similar for many of today’s A.I. tools. There are also sector-level limits. Consider Ramp’s data showing high adoption in the tech and finance industries, with considerably less in sectors like healthcare and food services. (Curiously, Ramp says only 29% of the U.S. construction industry has a subscription to generative A.I. products, while Hartley, et al. says over 40% of the construction industry is using it.)
I commend any attempt to figure out how useful generative A.I. is in the real world. One of the problems with this industry right now is that its biggest purveyors are not public companies and, therefore, have fewer disclosure requirements. Like any company, they are incentivized to inflate their importance, but we have little understanding of how much they are exaggerating. If you want to hear some corporate gibberish, OpenAI interviewed executives at companies like Philips and Scania about their use of ChatGPT, but I do not know what I gleaned from either interview — something about experimentation and vague stuff about people being excited to use it, I suppose. It is not very compelling to me. I am not in the C-suite, though.
The biggest public A.I. firm is arguably Microsoft. It has rolled out Copilot to Windows and Office users around the world. Again, however, its press releases leave much to be desired. Levi Strauss employees, Microsoft says, “report the devices and operating system have led to significant improvements in speed, reliability and data handling, with features like the Copilot key helping reduce the time employees spend searching and free up more time for creating”. Sure. In another case study, Microsoft and Pantone brag about the integration of a colour palette generator that you can use with words instead of your eyes.
Microsoft has every incentive to pretend Copilot is a revolutionary technology. For people actually doing the work, however, its ever-nagging presence might be one of many nuisances getting in the way of the job that person actually knows how to do. A few months ago, the company replaced the familiar Office portal with a Copilot prompt box. It is still little more than a thing I need to bypass to get to my work.
All the stats and apparent enthusiasm about A.I. in the workplace are, as far as I can tell, a giant mess. A problem with this technology is that the ways in which it is revolutionary are often not very useful, its practical application in a work context is a mixed bag that depends on industry and role, and its hype encourages otherwise respectable organizations to suggest their proximity to its promised future.
The Economist being what it is, much of this article revolves around the insufficiently realized efficiency and productivity gains, and that is certainly something for business-minded people to think about. But there are more fundamental issues with generative A.I. to struggle with. It is a technology built on a shaky foundation. It shrinks the already-scant field of entry-level jobs. Its results are unpredictable and can validate harm. The list goes on, yet it is being loudly inserted into our SaaS-dominated world as a top-down mandate.
It turns out A.I. is not magic dust you can sprinkle on a workforce to double their productivity. CEOs might be thrilled by having all their email summarized, but the rest of us do not need that. We need things like better balance of work and real life, good benefits, and adequate compensation. Those are things a team leader cannot buy with a $25-per-month-per-seat ChatGPT business license.
You have seen Moraine Lake. Maybe it was on a postcard or in a travel brochure, or it was on Reddit, or in Windows Vista, or as part of a “Best of California” demo on Apple’s website. Perhaps you were doing laundry in Lucerne. But I am sure you have seen it somewhere.
Moraine Lake is not in California — or Switzerland, for that matter. It is right here in Alberta, between Banff and Lake Louise, and I have been lucky enough to visit many times. One time I was particularly lucky, in a way I only knew in hindsight. I am not sure the confluence of events occurring in October 2019 is likely to be repeated for me.
In 2019, the road up to the lake would be open to the public from May until about mid-October, though the closing day would depend on when it was safe to travel. This is one reason why so many pictures of it have only the faintest hint of snow capping the mountains behind — it is only really accessible in summer.
I am not sure why we decided to head up to Lake Louise and Moraine Lake that Saturday. Perhaps it was just an excuse to get out of the house. It was just a few days before the road was shut for the season.
We visited Lake Louise first and it was, you know, just fine. Then we headed to Moraine.
Walking from the car to the lakeshore, we could see its surface was that familiar blue-turquoise, but it was entirely frozen. I took a few images from the shore. Then we realized we could just walk on it, as did the handful of other people who were there. This is one of several photos I took from the surface of the lake, the glassy ice reflecting that famous mountain range in the background.
I am not sure I would be able to capture a similar image today. Banff and Lake Louise have received more visitors than ever in recent years, to the extent private vehicles are no longer allowed to travel up to Moraine Lake. A shuttle bus is now required. The lake also does not reliably freeze at an accessible time and, when it does, it can be covered in snow or the water line may have receded. I am not arguing this is an impossible image to create going forward. I just do not think I am likely to see it this way again.
The United States government has long had an interest in boosting its high technology sector, with manifold objectives: for soft power, espionage, and financial dominance, at least. It has accomplished this through tax incentives, funding some of the best universities in the world, lax antitrust and privacy enforcement, and — in some cases — direct involvement. The internet began as a Department of Defense project, and the government invests in businesses through firms like In-Q-Tel.
All of this has worked splendidly for them. The world’s technology stack is overwhelmingly U.S.-dependent across the board, from consumers through large businesses and up to governments, even those which are not allies. Apparently, though, it is not enough and the country’s leaders are desperately worried about regulation in Europe and competition from Eastern Asia.
Federal Trade Commission Chairman Andrew N. Ferguson sent letters today to more than a dozen prominent technology companies reminding them of their obligations to protect the privacy and data security of American consumers despite pressure from foreign governments to weaken such protections. He also warned them that censoring Americans at the behest of foreign powers might violate the law.
[…]
“I am concerned that these actions by foreign powers to impose censorship and weaken end-to-end encryption will erode Americans’ freedoms and subject them to myriad harms, such as surveillance by foreign governments and an increased risk of identity theft and fraud,” Chairman [Andrew] Ferguson wrote.
These letters (PDF) serve as a reminder to, in effect, enforce U.S. digital supremacy around the world. Many of the most popular social networks are U.S.-based and export the country’s interpretation of permissive expression laws around the world, even to countries with different expectations. Occasionally, there will be conflicting policies which may mean country-specific moderation. What Ferguson’s letter appears to be asking is for U.S. companies to be sovereign places for U.S. citizens regardless of where their speech may appear.
The U.S. government is certainly correct to protect the interests of its citizens. But let us not pretend this is not also re-emphasizing the importance to the U.S. government of exporting its speech policy internationally, especially when it fails to adhere to it on its home territory. It is not just the hypocrisy that rankles, it is also the audacity requiring posts by U.S. users to be treated as a special class, to the extent that E.U. officials enforcing their own laws in their own territory could be subjected to sanctions.
As far as encryption, I have yet to see sufficient evidence of a radical departure from previous statements made by this president. When he was running the first time around, he called for an Apple boycott over the company’s refusal to build a special version of iOS to decrypt an iPhone used by a mass shooter. During his first term, Trump demanded Apple decrypt another iPhone in a different mass shooting. After two attempted assassinations last year, Trump once again said Apple should forcibly decrypt the iPhones of those allegedly responsible. It was under his first administration in which Apple was dissuaded from launching Advanced Data Protection in the first place. U.S. companies with European divisions recently confirmed they cannot comply with E.U. privacy and security guarantees as they are subject to the provisions of the CLOUD Act enacted during the first Trump administration.
The closest Trump has gotten to changing his stance is in a February interview with the Spectator’s Ben Domenech:
BD: But the problem is he [the British Prime Minister] runs, your vice president obviously eloquently pointed this out in Munich, he runs a nation now that is removing the security helmets on Apple phones so that they can—
DJT: We told them you can’t do this.
BD: Yeah, Tulsi, I saw—
DJT: We actually told him… that’s incredible. That’s something, you know, that you hear about with China.
The red line, it seems, is not at a principled opposition to “removing the security helmet” of encryption, but in the U.K.’s specific legislation. It is a distinction with little difference. The president and U.S. law enforcement want on-demand decryption just as much as their U.K. counterparts and have attempted to legislate similar requirements.
While the U.S. has been reinforcing the supremacy of its tech companies in Europe, it has also been propping them up at home:
Intel Corporation today announced an agreement with the Trump Administration to support the continued expansion of American technology and manufacturing leadership. Under terms of the agreement, the United States government will make an $8.9 billion investment in Intel common stock, reflecting the confidence the Administration has in Intel to advance key national priorities and the critically important role the company plays in expanding the domestic semiconductor industry.
The government’s equity stake will be funded by the remaining $5.7 billion in grants previously awarded, but not yet paid, to Intel under the U.S. CHIPS and Science Act and $3.2 billion awarded to the company as part of the Secure Enclave program. Intel will continue to deliver on its Secure Enclave obligations and reaffirmed its commitment to delivering trusted and secure semiconductors to the U.S. Department of Defense. The $8.9 billion investment is in addition to the $2.2 billion in CHIPS grants Intel has received to date, making for a total investment of $11.1 billion.
Despite its size — 10% of the company, making it the single largest shareholder — this press release says this investment is “a passive ownership, with no Board representation or other governance or information rights”. Even so, this is the U.S. attempting to reassert the once-vaunted position of Intel.
This deal is not as absurd as it seems. It is entirely antithetical to the claimed free market capitalist principles common to both major U.S. political parties but, in particular, espoused by Republicans. It is probably going to be wielded in terrible ways. But I can see at least one defensible reason for the U.S. to treat the integrity of Intel as an urgent issue: geology.
Near the end of Patrick McGee’s “Apple in China” sits a section that will haunt the corners of my brain for a long time. McGee writes that a huge amount of microprocessors — “at least 80 percent of the world’s most advanced chips” — are made by TSMC in Taiwan. There are political concerns with the way China has threatened Taiwan, which can be contained and controlled by humans, and frequent earthquakes, which cannot. Even setting aside questions about control, competition, and China, it makes a lot of sense for there to be more manufacturers of high-performance chips in places with less earthquake potential. (Silicon Valley is also sitting in a geologically risky place. Why do we do this to ourselves?)
At least Intel gets the shine of a Trump co-sign, and when has that ever gone wrong?
Then there are the deals struck with Nvidia and AMD, whereby the U.S. government gets a kickback in exchange for trade. Lauren Hirsch and Maureen Farrell, New York Times:
But some of Mr. Trump’s recent moves appear to be a strong break with historical precedent. In the cases of Nvidia and AMD, the Trump administration has proposed dictating the global market that these chipmakers can have access to. The two companies have promised to give 15 percent of their revenue from China to the U.S. government in order to have the right to sell chips in that country and bypass any future U.S. restrictions.
These moves add up and are, apparently, just the beginning. The U.S. has been a dominant force in high technology in part because of a flywheel effect created by early investments, some of which came from government sources and public institutions. This additional context does not undermine the entrepreneurship that came after, and which has been a proud industry trait. In fact, it demonstrates a benefit of strong institutions.
The rest of the world should see these massive investments as an instruction to build up our own high technology industries. We should not be too proud in Canada to set up Crown corporations that can take this on, and we ought to work with governments elsewhere. We should also not lose sight of the increasing hostility of the U.S. government making these moves to reassert its dominance in the space. We can stop getting steamrolled if we want to, but we really need to want to. We can start small.
When I watched Tim Cook, in the White House, carefully assemble a glass-and-gold trophy fit for a king, it felt to me like a natural outcome of the events and actions exhaustively documented by Patrick McGee in “Apple in China”. It was a reflection of the arc of Cook’s career, and of Apple’s turnaround from dire straits to a kind of supranational superpower. It was a consequence of two of the world’s most powerful nations sliding toward the (even more) authoritarian, and a product of appeasement to strongmen on both sides of the Pacific.
At the heart of that media spectacle was an announcement by Apple of $100 billion in domestic manufacturing investment over four years, in addition to its existing $500 billion promise. This is an extraordinary amount of money to spend in the country from which Apple has extricated its manufacturing over the past twenty years. The message from Cook was “we’re going to keep building technologies at the heart of our products right here in America because we’re a proud American company and we believe deeply in the promise of this great nation”. But what becomes clear after digesting McGee’s book is that core Apple manufacturing is assuredly not returning to the United States.
Do not get me wrong: there is much to be admired in the complementary goals of reducing China-based manufacturing and an increasing U.S. role. Strip away for a minute the context of this president and his corrupt priorities. Rich nations have become dependent on people in poorer nations to make our stuff, and no nation is as critical to our global stuff supply than China. One of the benefits of global trade is that it can smooth local rockiness; a bad harvest season no longer has to mean a shortage of food. Yet even if we ignore their unique political environment and their detestable treatment of Uyghur peoples — among many domestic human rights abuses — it makes little sense for us to be so dependent on this one country. This is basically an antitrust problem.
At the same time, it sure would be nice if we made more of the stuff we buy closer to where we live. We have grown accustomed to externalizing the negative consequences of making all this stuff. Factories exist somewhere else, so the resources they consume and the pollution they create is of little concern to us. They are usually not staffed by a brand we know, and tasks may be subcontracted, so there is often sufficient plausible deniability vis a vis working conditions and labour standards. As McGee documents, activist campaigns had a brief period of limited success in pressuring Apple to reform its standards and crack down on misbehaviour before the pressure of product delivery caught up with the company and it stopped reporting its regressing numbers. Also, it is not as though Apple could truly avoid knowing the conditions at these factories when there are so many of its own employees working side-by-side with Foxconn.
All the work done by people in factories far away from where I live is, frankly, astonishing. Some people still erroneously believe the country of origin is an indicator of whether a product is made with any degree of finesse or care. This is simply untrue, and it has been for decades, as McGee emphasizes. This book is worth reading for this perspective alone. The goods made in China today are among the most precise and well-crafted anywhere, on a simply unbelievable scale. In fact, it is this very ability to produce so much great stuff so quickly that has tied Apple ever tighter to China, argues McGee:
Whereas smartphone rivals like Samsung could bolt a bunch of off-the-shelf components together and make a handset, Apple’s strategy required it to become ever more wedded to the industrial clusters forming around its production. As more of that work took place in China, with no other nation developing the same skills, Apple was growing dependent on the very capabilities it had created. (page 176)
Cook’s White House announcement, for all its patriotic fervour, only underscores this dependency. In the book’s introduction, McGee reports “Apple’s investments in China reached $55 billion per year by 2015, an astronomical figure that doesn’t include the costs of components in Apple hardware” (page 7). That sum built out a complete, nimble, and precise supply chain at vast scale. By contrast, Apple says it is contributing a total of $600 billion over four years, or $150 billion per year. In other words, it is investing about three times as much in the U.S. compared to China and getting far less. Important stuff, to be sure, but less. And, yes, Apple is moving some iPhone production out of China, but not to the U.S. — something like 18% of iPhones are now made in India. McGee’s sources are skeptical of the company’s ability to do so at scale given the organization of the supply chain and the political positioning of its contract manufacturers, but nobody involved thinks Apple is going to have a U.S. iPhone factory.
So much of this story is about the iPhone, and it can be difficult to remember Apple makes a lot of other products. To McGee’s credit, he spends the first two-and-a-half sections of this six-part book exploring Apple’s history, the complex production of the G3 and G4 iMacs, and the making of the iPod which laid the groundwork for the iPhone. But a majority of the rest of the book is about the iPhone. That is unsurprising.
First, the iPhone is the product of a staggering amount of manufacturing knowledge. It is also, of course, a sales bonanza.
In fact, among the most riveting stories in the book do not concern manufacturing at all. McGee writes of grey market iPhone sales — a side effect of which was the implementation of parts pairing and activation — and the early frenzy over the iPad. Most notably, McGee spends a couple of chapters — particularly “5 Alarm Fire” — dissecting the sub-par launch sales of the iPhone XR as revealed through executive emails and depositions after Apple was sued for allegedly misleading shareholders. The case was settled last year for $490 million without Apple admitting wrongdoing. Despite some of these documents becoming public in 2022, it seems nobody before McGee took the time to read through them. I am glad he did because it is revealing. Even pointing to the existence of these documents offers a fascinating glimpse of what Apple does when a product is selling poorly.
Frustratingly, McGee does not attribute specific claims or quotations to individual documents in this chapter. Virtually everything in “5 Alarm Fire” is cited simply to the case number, so you have to go poking around yourself if you wish to validate his claims or learn more about the story.1 It may be worthwhile, however, since it underscores the unique risk Apple takes by releasing just a few new iPhones each year. If a model is not particularly successful, Apple is not going to quietly drop it and replace it with a different SKU. With the 2018 iPhones, Apple was rocked by a bunch of different problems, most notably the decent but uninteresting iPhone XR — 79% fewer preorders (PDF) when compared to the same sales channels as the iPhone 8 and 8 Plus — and the more exciting new phones from Huawei and Xiaomi released around the same time. Apple had hoped the 2018 iPhones would be more interesting to the Chinese market since they supported dual SIMs (PDF) and the iPhone XS came in gold. Apple responded to weak initial demand with targeted promotions, increasing production of the year-old iPhone X, and more marketing, but this was not enough and the company had to lower its revenue expectations for the quarter.
That Cook called this “obviously a disaster” is, of course, a relative term, as is the way I framed this as a “risk” of Apple’s smartphone release strategy. Apple still sold millions of iPhones — even the XR — and it still made a massive amount of money. It is a unique story, however, as it is one of the few times in the book where Apple has a problem of making too many products rather than too few. It is also illustrative of increasing competition from Chinese brands and, as emails reveal (PDF), trade tensions between the U.S. and China.
The fundamental heart of the story of this book is of the tension of a “proud American company” attempting to appease two increasingly nationalist and hostile governments. McGee examines Apple’s billion-dollar investment in Didi Chuxing, and mentions Cook’s appointment to the board of Tsinghua University School of Economics and Management. This is all part of the politicking the company realized it would need to do to appease President Xi. Similarly, its massive spending in China needed to be framed correctly. For example, in 2016, it said it was investing $275 billion in China over the following five years:
As mind-bogglingly large as its $275 billion investment was, it was not really a quid pro quo. The number didn’t represent any concession on Apple’s part. It was just the $55 billion the company estimated it’d invested for 2015, multiplied by five years. […] What was new, in other words, wasn’t Apple’s investment, but its marketing of the investment. China was accumulating reams of specialized knowledge from Apple, but Beijing didn’t know this because Apple had been so secretive. From this meeting forward, the days in which Apple failed to score any political points from its investments in the country were over. It was learning to speak the local language.
One can see a similar dynamic in the press releases for U.S. investments it began publishing one year later, after Donald Trump first took office. Like Xi, Trump was eager to bend Apple to his administration’s priorities. Some of the company’s actions and investments are probably the same as those it would have made anyhow, but it is important to these autocrat types that they believe they are calling the shots.
Among the reasons the U.S. has given for taking a more hostile trade position on China is its alleged and, in some cases, proven theft of intellectual property. McGee spends less time on this — in part, I imagine, because it is a hackneyed theme frequently used only to treat innovation by Chinese companies with suspicion and contempt. This book is a more levelheaded piece of analysis. Instead of having the de rigueur chapter or two dedicated to intellectual property leaving through the back door, McGee examines the less-reported front-door access points. Companies are pressured to participate in “joint ventures” with Chinese businesses to retain access to markets, for example; this is why iCloud in China is operated not by Apple, but by AIPO Cloud (Guizhou) Technology Co. Ltd.
Even though patent and design disputes are not an area of focus for McGee, it is part of the two countries’ disagreements over trade, and one area where Apple is again stuck in the middle. A concluding anecdote in the book references the launch of the Huawei Mate XT, a phone that folds in three which, to McGee, “appears to be a marvel of industrial engineering”:2
It was only in 2014 that Jony Ive complained of cheap Chinese phones and their brazen “theft” of his designs; it was 2018 when Cupertino expressed shock at Chinese brands’ ability to match the newest features; now, a Chinese brand is designing, manufacturing, and shipping more expensive phones with alluring features that, according to analysts, Apple isn’t expected to match until 2027. No wonder the most liked comment on a YouTube unboxing video of the Mate XT is, “Now you know why USA banned Huawei.” (pages 377–378)
The Mate XT was introduced the same day as the iPhone 16 line, and the differences could not have been more stark. The iPhone was a modest evolution of the company’s industrial design language, yet would be familiar to someone who had been asleep for the preceding fifteen years. The Mate XT was anything but. The phones also had something in common: displays made by BOE. The company is one of several suppliers for the iPhone, and it enables the radical design of Huawei’s phone. But according to Samsung, BOE’s ability to make OLED and flexible displays depends on technology stolen from them. The U.S. International Trade Commission agreed and will issue a final ruling in November which is likely to prohibit U.S. imports of BOE-made displays. It seems like this will be yet another point of tension between the U.S. and China, and another thing Cook can mention during his next White House visit.
“Apple in China” is, as you can imagine, dense. I have barely made a dent in exploring it here. It is about four hundred pages and not a single one is wasted. This is not one of those typical books about Apple; there is little in here you have read before. It answers a bunch of questions I have had and serves as a way to decode Apple’s actions for the past ten years and, I think, during this second Trump presidency.
At the same time, it leaves me asking questions I did not fully consider before. I have long assumed Apple’s willingness to comply with the demands of the Chinese government are due to its supply chain and manufacturing role. That is certainly true, but I also imagine the country’s sizeable purchasing power is playing an increasing role. That is, even if Apple decentralizes its supply chain — unlikely, if McGee’s sources are to be believed — it is perhaps too large and too alluring a market for Apple to ignore. Then again, it arguably created this problem itself. Its investments in China have been so large and, McGee argues, so impactful they can be considered in the same context as the U.S.’ post-World War II European recovery efforts. Also, the design of Apple’s ecosystem is such that it can be so deferential. If the Chinese government does not want people in its country using an app, the centralized App Store means it can be yanked away.3
Cook has previously advocated for expressing social values as a corporate principle. In 2017, he said, perhaps paraphrasing his heroesMartin Luther King Jr. and John Lewis, “if you see something going on that’s not right, the most powerful form of consent is to say nothing”. But how does Cook stand firmly for those values while depending on an authoritarian country for Apple’s hardware, and trying to appease a wanna-be dictator for the good standing of his business? In short, he does not. In long, well, it is this book.
It is this tension — ably shown by McGee in specific actions and stories rather than merely written about — that elevates “Apple in China” above the typical books about Apple and its executives. It is part of the story of how Apple became massive, how an operations team became so influential, and how the seemingly dowdy business of supply chains in China applied increasingly brilliant skills and became such a valuable asset in worldwide manufacturing. And it all leads directly to Tim Cook standing between Donald Trump and J.D. Vance in the White House, using the same autocrat handling skills he has practiced for years. Few people or businesses come out of this story looking good. Some look worse than others.
The most relevant documents I found under the “415” filings from December 2023. ↥︎
I think it is really weird to cite a YouTube comment in a serious book. ↥︎
I could not find a spot for this story in this review, but it forecasts Apple’s current position:
But Jobs resented third-party developers as freeloaders. In early 1980, he had a conversation with Mike Markkula, Apple’s chairman, where the two expressed their frustration at the rise of hardware and software groups building businesses around the Apple II. They asked each other: “Why should we allow people to make money off of us? Off of our innovations?” (page 23)
Sure seems like the position Jobs was able to revisit when Apple created its rules for developing apps for the iPhone and subsequent devices. McGee sources this to Michael Malone’s 1999 book “Infinite Loop”, which I now feel I must read. ↥︎
Pew Research Centre made headlines this week when it released a report on the effects of Google’s A.I. Overviews on user behaviour. It provided apparent evidence searchers do not explore much beyond the summary when presented with one. This caused understandable alarm among journalists who focused on two stats in particular: a reduction from 15% of searches which resulted in a result being clicked to just 8% when an A.I. Overview was shown, and finding that just 1% of searches with an Overview resulted in a click on a citation in that summary.
Beatrice Nolan, of Fortune, said this was evidence A.I. was “eating search”. Thomas Claburn, of the Register, said they were “killing the web”, and Emanuel Maiberg, of 404 Media, says Google’s push to boost A.I. “will end the flow of all that traffic almost completely and destroy the business of countless blogs and news sites in the process”. In addition to the aforementioned stats, Ryan Whitwam, of Ars Technica, also noted Pew found “Google users are more likely to end their browsing session after seeing an A.I. Overview” than if they do not. It is, indeed, worrisome.
Pew’s is not the only research finding a negative impact on search traffic to publishers thanks to Google’s A.I. search efforts. Ryan Law and Xibeijia Guan of Ahrefs published, earlier this year, the results of anonymized and aggregated Google Search Console data finding a 34.5% drop in click-through rate when A.I. Overviews were present. This is lower than the 47% drop found by Pew, but still a massive amount.
Ahrefs gives two main explanations for this decline in click-through traffic. First, and most obviously, these Overviews present as though they answer a query without needing to visit any other pages. Second, they push results further down the page. On a phone, an Overview may occupy the whole height of the display, as shown in Google’s many examples. Either one of these could be affecting whether users are clicking through to more stuff.
So we have two different reports showing, rather predictably, that Google’s A.I. Overviews kneecap click rates on search listings. But these findings are complicated by the various other boxes Google might show on a results page, none of which are what Google calls an “A.I.” feature. There are a slew of Rich Result types — event information, business listings, videos, and plenty more. There are Rich Answers for when you ask a general knowledge question. There are Featured Snippets that extract and highlight information from a specific page. These “zero-click” features all look and behave similarly to A.I. Overviews. They all try to answer a user’s question immediately. They all push organic results further down the page. So what is different about results with an A.I. twist?
Part of the problem is with methodology. That deja vu you are experiencing is because I wrote about this earlier this week, but I wanted to reiterate and expand upon that. The way Pew and Ahrefs collected the data for measuring click-through rates differs considerably. Pew, via Ipsos KnowledgePanel, collected browsing data from 900 U.S. adults. Researchers then used a selection of keywords to identify search result pages with A.I. Overviews. Ahrefs, on the other hand, relied on data directly from Google Search Console automatically provided by users who connected it to the company’s search optimization software. Ahrefs compared data collected in March 2024, pre-A.I. rollout, against that from March 2025 after Google made A.I. Overviews more present in search results.
In both reports, there is no effort made to distinguish between searches with A.I. Overviews present and those with the older search features mentioned above, and that would impact average click-through rates. Since Featured Snippets rolled out, for example, they have been considered the new first position in results and, unlike A.I. Overviews in the findings of Pew and Ahref, they can drive a lot of traffic. Search optimization studies are pretty inconsistent, finding Featured Snippets on between 11%, according to Stat, and up to 80% according to Ahrefs.
But the difference is even harder to research than it seems because A.I. Overviews do not necessarily replace Featured Snippets, nor are they independent of each other. There are queries for which Overviews are displayed that had no such additional features before, there are queries where Featured Snippets are being replaced. Sometimes, the results page will show an A.I. Overview and a Featured Snippet. There does not seem to be a lot of good data to disentangle what effect each of these features has in this era. A study from Amisive from earlier this year found the combined display of Overviews and Snippets reduced click-through rates by 37%, but Amisive did not publish a full data set to permit further exploration.
But publishers do seem to be feeling the effects of A.I. on traffic from Google’s search engine. The Wall Street Journal, relying on data from Similarweb, reported a precipitous drop in search traffic to mainstream news sources like Business Insider and the Washington Post from 2022 to 2025. Similarweb said the New York Times’ share of traffic coming from search fell from 44% to 36.5% in that time. Interestingly, Similarweb’s data did not show a similar effect for the Journal itself, reporting a five-point increase in the share of traffic derived from search over the same period.
The quality of Similarweb’s data is, I think, questionable. It would be better if we had access to a large-scale first-party source. Luckily, the United States Government operates proprietary analytics software with open access. Though it is not used on all U.S. federal government websites, its data set is both general-purpose — albeit U.S.-focused — and huge: 1.55 billion sessions in the last thirty days. As of writing, 44.1% of traffic in the current calendar year is from organic Google searches, down from 46.4% in the previous calendar year. That is not the steep decline found by Similarweb, but it is a decline nevertheless — enough to drop organic Google search traffic behind direct traffic. I also imagine Google’s A.I. Overviews impact different types of websites differently; the research from Ahrefs and Amisive seems to back this up.
Google has, naturally, disputed the results of Pew’s research. In an extended comment to Search Engine Journal, the company said Pew “use[d] a flawed methodology and skewed queryset that is not representative of Search traffic”, adding “[we] have not observed significant drops in aggregate web traffic”. What Google sees as flaws in Pew’s methodology is not disclosed, nor does the company provide any numbers to support its side of the story. Sundar Pichai, Google’s CEO, has even claimed A.I. Overviews are better for referral traffic than links outside Overviews — but, again, has never provided evidence.
Intuitively, it makes sense to me that A.I. Overviews are going to have a negative impact on click-through rates, because that is kind of the whole point. The amount of information being provided to users on the results page increases while the source of that information is minimized. It also seems like the popular data sources for A.I. Overviews are of mixed quality; according to a Semrush study, Quora is the most popular citation, while Reddit is the second-most popular.
I find all of these studies frustrating and it is not necessarily the fault of the firms conducting them. Try as hard as the search optimization industry has, we still do not have terrifically reliable ways of measuring the impact each new Google feature has on organic search traffic. The party in the best possible position to demystify this — Google — tends to be extremely secretive on the grounds it does not want people gaming its systems. Also, given the vast disconnect between the limited amount Google is saying and the findings of researchers, I am not sure how much I trust its word.
It is possible we cannot know exactly how much of an effect A.I. Overviews will have on search trafic, let alone that of “answer engines” like Perplexity. The best thing any publisher can do at this point is to assume the mutual benefits are going away — and not just in search. Between Google’s legal problems and it fundamentally reshaping how people discover things in search, one has to wonder how it will evolve its advertising business. Publishers have already been prioritizing direct relationships with readers. What about advertisers, too? Even with the unknown future of A.I. technologies, it seems like it would be advantageous to stop relying so heavily on Google.
Tripp Mickle, of the New York Times, wrote another one of those articles exploring the feasibility of iPhone manufacturing in the United States. There is basically nothing new here; the only reason it seems to have been published is because the U.S. president farted out yet another tariff idea, this time one targeted specifically at the iPhone at a rate of 25%.1
Anyway, there is one thing in this article — bizarrely arranged in a question-and-answer format — that is notable:
What does China offer that the United States doesn’t?
Small hands, a massive, seasonal work force and millions of engineers.
Young Chinese women have small fingers, and that has made them a valuable contributor to iPhone production because they are more nimble at installing screws and other miniature parts in the small device, supply chain experts said. In a recent analysis the company did to explore the feasibility of moving production to the United States, the company determined that it couldn’t find people with those skills in the United States, said two people familiar with the analysis who spoke on the condition of anonymity.
I will get to the racial component of this in a moment, but this answer has no internal logic. There are two sentences in that larger paragraph. The second posits that people in the U.S. do not have the “skills” needed to carefully assemble iPhones, but the skills as defined in the first sentence are small fingers — which is not a skill. I need someone from the Times to please explain to me how someone can be trained to shrink their fingers.
Anyway, this is racist trash. In response to a question from Julia Carrie Wong of the Guardian, Times communications director Charlie Stadtlander disputed the story was furthering “racial or genetic generalizations”, and linked to a podcast segment clipped by Mickle. In it, Patrick McGee, author of “Apple in China”, says:
The tasks that are often being done to make iPhones require little fingers. So the fact that it’s young Chinese women with little fingers — that actually matters. Like, Apple engineers will talk about this.
The podcast in question is, unsurprisingly, Bari Weiss’; McGee did not mention any of this when he appeared on, for example, the Daily Show.
Maybe some Apple engineers actually believe this, and maybe some supply chain experts do, too. But it is a longstandingsexist stereotype. (Thanks to Kat for the Feminist Review link.) It is ridiculous to see this published in a paper of record as though it is just one fact among many, instead of something which ought to be debunked.
The Times has previously reported why iPhones cannot really be made in the U.S. in any significant quantity. It has nothing to do with finger size, and everything to do with a supply chain the company has helped build for decades, as McGee talks about extensively in that Daily Show interview and, presumably, writes about in his book. (I do not yet have a copy.) Wages play a role, but it is the sheer concentration of manufacturing capability that explains why iPhones are made in China, and why it has been so difficult for Apple to extricate itself from the country.
About which the funniest comment comes from Anuj Ahooja on Threads. ↥︎
There is a long line of articlesquestioningApple’s ability to deliver on artificial intelligence because of its position on data privacy. Today, we got another in the form of a newsletter.
Meanwhile, Apple was focused on vertically integrating, designing its own chips, modems, and other components to improve iPhone margins. It was using machine learning on small-scale projects, like improving its camera algorithms.
[…]
Without their ads businesses, companies like Google and Meta wouldn’t have built the ecosystems and cultures required to make them AI powerhouses, and that environment changed the way their CEOs saw the world.
Again, I will emphasize this is a newsletter. It may seem like an article from a prestige publisher that prides itself on “separat[ing] the facts from our views”, but you might notice how, aside from citing some quotes and linking to ads, none of Albergotti’s substantive claims are sourced. This is just riffing.
I remain skeptical. Albergotti frames this as both a mindset shift and a necessity for advertising companies like Google and Meta. But the company synonymous with the A.I. boom, OpenAI, does not have the same business model. Besides, Apple behaves like other A.I. firms by scraping the web and training models on massive amounts of data. The evidence for this theory seems pretty thin to me.
But perhaps a reluctance to be invasive and creepy is one reason why personalized Siri features have been delayed. I hope Apple does not begin to mimic its peers in this regard; privacy should not be sacrificed. I think it is silly to be dependent on corporate choices rather than legislation to determine this, but that is the world some of us live in.
Let us concede the point anyhow, since it suggests a role Apple could fill by providing an architecture for third-party A.I. on its products. It does not need to deliver everything to end users; it can focus on building a great platform. Albergotti might sneeze at “designing its own chips […] to improve iPhone margins”, which I am sure was one goal, but it has paid off in ridiculously powerful Macs perfectfor A.I.workflows. And, besides, it has already built some kind of plugin architecture into Apple Intelligence because it has integrated ChatGPT. There is no way for other providers to add their own extension — not yet, anyhow — but the system is there.
The crux of the issue in my mind is this: Apple has a lot of good ideas, but they don’t have a monopoly on them. I would like some other folks to come in and try their ideas out. I would like things to advance at the pace of the industry, and not Apple’s. Maybe with a blessed system in place, Apple could watch and see how people use LLMs and other generative models (instead of giving us Genmoji that look like something Fisher-Price would make). And maybe open up the existing Apple-only models to developers. There are locally installed image processing models that I would love to take advantage of in my apps.
Which brings me to my second point. The other feature that I could see Apple market for a “ChatGPT/Claude via Apple Intelligence” developer package is privacy and data retention policies. I hear from so many developers these days who, beyond pricing alone, are hesitant toward integrating third-party AI providers into their apps because they don’t trust their data and privacy policies, or perhaps are not at ease with U.S.-based servers powering the popular AI companies these days. It’s a legitimate concern that results in lots of potentially good app ideas being left on the table.
One of Apple’s specialties is in improving the experience of using many of the same technologies as everyone else. I would like to see that in A.I., too, but I have been disappointed by its lacklustre efforts so far. Even long-running projects where it has had time to learn and grow have not paid off, as anyone can see in Siri’s legacy.
What if you could replace these features? What if Apple’s operating systems were great platforms by which users could try third-party A.I. services and find the ones that fit them best? What if Apple could provide certain privacy promises, too? I bet users would want to try alternatives in a heartbeat. Apple ought to welcome the challenge.
Spencer Ackerman has been a national security reporter for over twenty years, and was partially responsible for the Guardian’s coverage of NSA documents leaked by Edward Snowden. He has good reason to be skeptical of privacy claims in general, and his experience updating his iPhone made him worried:
Recently, I installed Apple’s iOS 18.1 update. Shame on me for not realizing sooner that I should be checking app permissions for Siri — which I had thought I disabled as soon as I bought my device — but after installing it, I noticed this update appeared to change Siri’s defaults.
Apple has a history with changing preferences and dark patterns. This is particularly relevant in the case of the iOS 18.1 update because it was the one with Apple Intelligence, which creates new ambiguity between what is happening on-device and what goes to a server farm somewhere.
While easy tasks are handled by their on-device models, Apple’s cloud is used for what I’d call moderate-difficulty work: summarizing long emails, generating patches for Photos’ Clean Up feature, or refining prose in response to a prompt in Writing Tools. In my testing, Clean Up works quite well, while the other server-driven features are what you’d expect from a medium-sized model: nothing impressive.
Users shouldn’t need to care whether a task is completed locally or not, so each feature just quietly uses the backend that Apple feels is appropriate. The relative performance of these two systems over time will probably lead to some features being moved from cloud to device, or vice versa.
It would be nice if it truly did not matter — and, for many users, the blurry line between the two is probably fine. Private Cloud Compute seems to be trustworthy. But I fully appreciate Ackerman’s worries. Someone in his position necessarily must understand what is being stored and processed in which context.
However, Ackerman appears to have interpreted this setting change incorrectly:
I was alarmed to see that even my secure communications apps, like Proton and Signal, were toggled by default to “Learn from this App” and enable some subsidiary functions. I had to swipe them all off.
This setting was, to Ackerman, evidence of Apple “uploading your data to its new cloud-based AI project”, which is a reasonable assumption at a glance. Apple, like every technology company in the past two years, has decided to loudly market everything as being connected to its broader A.I. strategy. In launching these features in a piecemeal manner, though, it is not clear to a layperson which parts of iOS are related to Apple Intelligence, let alone where those interactions are taking place.
However, this particular setting is nearly three years old and unrelated to Apple Intelligence. This is related to Siri Suggestions which appear throughout the system. For example, the widget stack on my home screen suggests my alarm clock app when I charge my iPhone at night. It suggests I open the Microsoft Authenticator app on weekday mornings. When I do not answer the phone for what is clearly a scammer, it suggests I return the missed call. It is not all going to be gold.
Even at the time of its launch, its wording had the potential for confusion — something Apple has not clarified within the Settings app in the intervening years — and it seems to have been enabled by default. While this data may play a role in establishing the “personal context” Apple talks about — both are part of the App Intents framework — I do not believe it is used to train off-device Apple Intelligence models. However, Apple says this data may leave the device:
Your personal information — which is encrypted and remains private — stays up to date across all your devices where you’re signed in to the same Apple Account. As Siri learns about you on one device, your experience with Siri is improved on your other devices. If you don’t want Siri personalization to update across your devices, you can disable Siri in iCloud settings. See Keep what Siri knows about you up to date on your Apple devices.
While I believe Ackerman is incorrect about the setting’s function and how Apple handles its data, I can see how he interpreted it that way. The company is aggressively marketing Apple Intelligence, even though it is entirely unclear which parts of it are available, how it is integrated throughout the company’s operating systems, and which parts are dependent on off-site processing. There are people who really care about these details, and they should be able to get answers to these questions.
All of this stuff may seem wonderful and novel to Apple and, likely, many millions of users. But there are others who have reasonable concerns. Like any new technology, there are questions which can only be answered by those who created it. Only Apple is able to clear up the uncertainty around Apple Intelligence, and I believe it should. A cynical explanation is that this ambiguity is all deliberate because Apple’s A.I. approach is so much slower than its competitors and, so, it is disincentivized from setting clear boundaries. That is possible, but there is plenty of trust to be gained by being upfront now. Americans polled by Pew Research and Gallup have concerns about these technologies. Apple has repeatedly emphasized its privacy bonafides. But these features remain mysterious and suspicious for many people regardless of how much a giant corporation swears it delivers “stateless computation, enforceable guarantees, no privileged access, non-targetability, and verifiable transparency”.
All of that is nice, I am sure. Perhaps someone at Apple can start the trust-building by clarifying what the Siri switch does in the Settings app, though.
Brendan Nystedt, reporting for Wired on a new generation of admirers of crappy digital cameras from the early 2000s:
For those seeking to experiment with their photography, there’s an appeal to using a cheap, old digital model they can shoot with until it stops working. The results are often imperfect, but since the camera is digital, a photographer can mess around and get instant gratification. And for everyone in the vintage digital movement, the fact that the images from these old digicams are worse than those from a smartphone is a feature, not a bug.
Retromania? Not really. It feels more like a backlash against the excessive perfection of modern cameras, algorithms, and homogenized modern image-making. I don’t disagree — you don’t have to do much to come up with a great-looking photo these days. It seems we all want to rebel against the artistic choices of algorithms and machines — whether it is photos or Spotify’s algorithmic playlists versus manually crafted mixtapes.
I agree, though I do not see why we need to find just one cause — an artistic decision, a retro quality, an aesthetic trend, a rejection of perfection — when it could be driven by any number of these factors. Nailing down exactly which of these is the most important factor is not of particular interest to me; certainly, not nearly as much as understanding that people, as a general rule, value feeling.
I have written about this before and it is something I wish to emphasize repeatedly: efficiency and clarity are necessary elements, but are not the goal. There needs to be space for how things feel. I wrote this as it relates to cooking and cars and onscreen buttons, and it is still something worth pursuing each and every time we create anything.
I thought about this with these two articles, but first last week when Wil Shipley announced the end of Delicious Library:
Amazon has shut off the feed that allowed Delicious Library to look up items, unfortunately limiting the app to what users already have (or enter manually).
I wasn’t contacted about this.
I’ve pulled it from the Mac App Store and shut down the website so nobody accidentally buys a non-functional app.
Delicious Library was many things: physical and digital asset management software, a kind of personal library, and a wish list. But it was also — improbably — fun. Little about cataloguing your CDs and books sounds like it ought to be enjoyable, but Shipley and Mike Matas made it feel like something you wanted to do. You wanted to scan items with your Mac’s webcam just because it felt neat. You wanted to see all your media on a digital wooden shelf, if for no other reason than it made those items feel as real onscreen as they are in your hands.
Delicious Library became known as the progenitor of the “delicious generation” of applications, which prioritized visual appeal as much as utility. It was not enough for an app to be functional; it needed to look and feel special. The Human Interface Guidelines were just that: guidelines. One quality of this era was the apparently fastidious approach to every pixel. Another quality is that these applications often had limited features, but were so much fun to use that it was possible to overlook their restrictions.
I do not need to relitigate the subsequent years of visual interfaces going too far, then being reeled in, and then settling in an odd middle ground where I am now staring at an application window with monochrome line-based toolbar icons, deadpan typography, and glassy textures, throwing a heavy drop shadow. None of the specifics matter much. All I care about is how these things feel to look at and to use, something which can be achieved regardless of how attached you are to complex illustrations or simple line work. Like many people, I spend hours a day staring at pixels. Which parts of that are making my heart as happy as my brain? Which mundane tasks are made joyful?
This is not solely a question of software; it has relevance in our physical environment, too, especially as seemingly every little thing in our world is becoming a computer. But it can start with pixels on a screen. We can draw anything on them; why not draw something with feeling? I am not sure we achieve that through strict adherence to perfection in design systems and structures.
I am reluctant to place too much trust in my incomplete understanding of a foreign-to-me concept rooted in another country’s very particular culture, but perhaps the sabi is speaking loudest to me. Our digital interfaces never achieve a patina; in fact, the opposite is more often true: updates seem to erase the passage of time. It is all perpetually new. Is it any wonder so many of us ache for things which seem to freeze the passage of time in a slightly hazier form?
I am not sure how anyone would go about making software feel broken-in, like a well-worn pair of jeans or a lounge chair. Perhaps that is an unattainable goal for something on a screen; perhaps we never really get comfortable with even our most favourite applications. I hope not. It would be a shame if we lose that quality as software eats our world.
Apple is a famously tight-knit business. Its press releases and media conferences routinely drum the integration of hardware, software, and services as something only Apple is capable of doing. So it sticks out when features feel like they were developed by people who do not know what another part of the company is doing. This happened to me twice in the past week.
Several years ago, Apple added a very nice quality-of-life improvement to the Mac operating system: software installers began offering to delete themselves after they had done their job. This was a good idea.
In the ensuing years, Apple made some other changes to MacOS in an effort to — it says — improve privacy and security. One of the new rules it imposed was requiring the user to grant apps specific permission to access certain folders; another was a requirement to allow one app to modify or delete another.
And, so, when I installed an application earlier this month, I was shown an out-of-context dialog at the end of the process asking for access to my Downloads folder. I granted it. Then I got a notification that the Installer app was blocked from modifying or deleting another file. To change it, I had to open System Settings, toggle the switch, enter my password, and then I was prompted to restart the Installer application — but it seemed to delete itself just fine without my doing so.
This is a built-in feature, triggered by where the installer has been downloaded, using an Apple-provided installation packaging system.1 But it is stymied by a different set of system rules and unexpected permissions requests.
Another oddity is in Apple’s two-factor authentication system. Because Apple controls so much about its platforms, authentication codes are delivered through a system prompt on trusted devices. Preceding the code is a notification informing the user their “Apple Account is being used to sign in”, and it includes a map of where that is.
This map is geolocated based on the device’s IP address, which can be inaccurate for many reasons — something Apple discloses in its documentation:
This location is based on the new device’s IP address and might reflect the network that it’s connected to, rather than the exact physical location. If you know that you’re the person trying to sign in but don’t recognize the location, you can still tap Allow and view the verification code.
It turns out one of the reasons the network might think you are located somewhere other than where you are is because you may be using iCloud Private Relay. Even if you have set it to “maintain general location”, it can sometimes be incredibly inaccurate. I was alarmed to see a recent attempt from Toronto when I was trying to sign into iCloud at home in Calgary — a difference of over 3,000 kilometres.
The map gives me an impression of precision and security. But if it is made less accurate in part because of a feature Apple created and markets, it is misleading and — at times — a cause of momentary anxiety.
What is more, Safari supports automatically filling authentication codes delivered by text message. Apple’s own codes, though, cannot be automatically filled.
These are small things — barely worth the bug report. They also show how features introduced one year are subverted by those added later, almost like nobody is keeping track of all of the different capabilities in Apple’s platforms. I am sure there are more examples; these are just the ones which happened in the past week, and which I have been thinking about. They expose little cracks in what is supposed to be a tight, coherent package of software.
Thanks to Keir Ansell for tracking down this documentation for me. ↥︎
Since owners of web properties became aware of the traffic-sending power of search engines — most often Google in most places — they have been in an increasingly uncomfortable relationship as search moves beyond ten relevant links on a page. Google does not need websites, per se; it needs the information they provide. Its business recommendations are powered in part by reviews on other websites. Answers to questions appear in snippets, sourced to other websites, without the user needing to click away.
Publishers and other website owners might consider this a bad deal. They feed Google all this information hoping someone will visit their website, but Google is adding features that make it less likely they will do so. Unless they were willing to risk losing all their Google search traffic, there was little a publisher could do. Individually, they needed Google more than Google needed them.
But that has not been quite as true for Reddit. Its discussions hold a uniquely large corpus of suggestions and information on specific topics and in hyper-local contexts, as well as a whole lot of trash. While the quality of Google’s results have been sliding, searchers discovered they could append “Reddit” to a
query to find what they were looking for.
Google realized this and, earlier this year, signed a $60 million deal with Reddit allowing it to scrape the site to train its A.I. features. Part of that deal apparently involved indexing pages in search as, last month, Reddit restricted that capability to Google. That is: if you want to search Reddit, you can either use the site’s internal search engine, or you can use Google. Other search engines still display results created from before mid-July, according to404 Media, but only Google is permitted to crawl anything newer.
It is unclear to me whether this is a deal only available to Google, or if it is open to any search engine that wants to pay. Even if it was intended to be exclusive, I have a feeling it might not be for much longer. But it seems like something Reddit would only care about doing with Google because other search engines basically do not matter in the United States or worldwide.1 What amount of money do you think Microsoft would need to pay for Bing to be the sole permitted crawler of Reddit in exchange for traffic from its measly market share? I bet it is a lot more than $60 million.
Maybe that is one reason this agreement feels uncomfortable to me. Search engines are marketed as finding results across the entire web but, of course, that is not true: they most often obey rules declared in robots.txt files, but they also do not necessarily index everything they are able to, either. These are not explicit limitations. Yet it feels like it violates the premise of a search engine to say that it will be allowed to crawl and link to other webpages. The whole thing about the web is that the links are free. There is no guarantee the actual page will be freely accessible, but the link itself is not restricted. It is the central problem with link tax laws, and this pay-to-index scheme is similarly restrictive.
This is, of course, not the first time there has been tension in how a site balances search engine visibility and its own goals. Publishers have, for years, weighed their desire to be found by readers against login requirements and paywalls — guided by the overwhelming influence of Google.
Google used to require publishers provide free articles to be indexed by the search engine but, in 2017, it replaced that with a model that is more flexible for publishers. Instead of forcing a certain number of free page views, publishers are now able to provide Google with indexable data.
Then there are partnerships struck by search engines and third parties to obtain specific kinds of data. These were summarized well in the recent United States v. Google decision (PDF), and they are probably closest in spirit to this Reddit deal:
GSEs enter into data-sharing agreements with partners (usually specialized vertical providers) to obtain structured data for use in verticals. Tr. at 9148:2-5 (Holden) (“[W]e started to gather what we would call structured data, where you need to enter into relationships with partners to gather this data that’s not generally available on the web. It can’t be crawled.”). These agreements can take various forms. The GSE might offer traffic to the provider in exchange for information (i.e., data-for-traffic agreements), pay the provider revenue share, or simply compensate the provider for the information. Id. at 6181:7-18 (Barrett-Bowen).
As of 2020, Microsoft has partnered with more than 100 providers to obtain structured data, and those partners include information sources like Fandango, Glassdoor, IMDb, Pinterest, Spotify, and more. DX1305 at .004, 018–.028; accord Tr. at 6212:23–6215:10 (Barrett-Bowen) (agreeing that Microsoft partners with over 70 providers of travel and local information, including the biggest players in the space).
The government attorneys said Bing is required to pay for structured data owing to its smaller size, while Google is able to obtain structured data for free because it sends partners so much traffic. The judge ultimately rejected their argument Microsoft struggled to sign these agreements or it was impeded in doing so, but did not dispute the difference in negotiating power between the two companies.
Once more, for emphasis: Google usually gets structured data for free but, in this case, it agreed to pay $60 million; imagine how much it would cost Bing.
This agreement does feel pretty unique, though. It is hard for me to imagine many other websites with the kind of specific knowledge found aplenty on Reddit. It is a centralized version of the bulletin boards of the early 2000s for such a wide variety of interests and topics. It is such a vast user base that, while it cannot ignore Google referrals, it is not necessarily reliant on them in the same way as many other websites are.
Most other popular websites are insular social networks; Instagram and TikTok are not relying on Google referrals. Wikipedia would probably be the best comparison to Reddit in terms of the contribution it makes to the web — even greater, I think — but every article page I tried except the homepage is overwhelmingly dependent on external search engine traffic.
Meanwhile, pretty much everyone else still has to pay Google for visitors. They have to buy the ads sitting atop organic search results. They have to buy ads on maps, on shopping carousels, on videos. People who operate websites hope they will get free clicks, but many of them know they will have to pay for some of them, even though Google will happily lift and summarize their work without compensation.
I cannot think of any other web property which has this kind of leverage over Google. While this feels like a violation of the ideals and principles that have built the open web on which Google has built its empire, I wonder if Google will make many similar agreements, if any. I doubt it — at least for now. This feels funny; maybe that is why it is so unique, and why it is not worth being too troubled by it.
The uptick of Bing in the worldwide chart appears to be, in part, thanks to a growing share in China. Its market share has also grown a little in Africa and South America, but only by tiny amounts. However, Reddit is blocked in China, so a deal does not seem particularly attractive to either party. ↥︎
Anthony Ha, of TechCrunch, interviewed Jean-Paul Schmetz, CEO of Ghostery, and I will draw your attention to this exchange:
AH I want to talk about both of those categories, Big Tech and regulation. You mentioned that with GDPR, there was a fork where there’s a little bit of a decrease in tracking, and then it went up again. Is that because companies realized they can just make people say yes and consent to tracking?
J-PS What happened is that in the U.S., it continued to grow, and in Europe, it went down massively. But then the companies started to get these consent layers done. And as they figured it out, the tracking went back up. Is there more tracking in the U.S. than there is in Europe? For sure.
AH So it had an impact, but it didn’t necessarily change the trajectory?
J-PS It had an impact, but it’s not sufficient. Because these consent layers are basically meant to trick you into saying yes. And then once you say yes, they never ask again, whereas if you say no, they keep asking. But luckily, if you say yes, and you have Ghostery installed, well, it doesn’t matter, because we block it anyway.
And then Big Tech has a huge advantage because they always get consent, right? If you cannot search for something in Google unless you click on the blue button, you’re going to give them access to all of your data, and you will need to rely on people like us to be able to clean that up.
The TechCrunch headline summarizes this by saying “regulation won’t save us from ad trackers”, but I do not think that is a fair representation of this argument. What it sounds like, to me, is that regulations should be designed more effectively.
The E.U.’s ePrivacy Directive and GDPR have produced some results: tracking is somewhat less pervasive, people have a right to data access and portability, and businesses must give users a choice. That last thing is, as Schmetz points out, also its flaw, and one it shares with something like App Tracking Transparency on iOS. Apps affected by the latter are not permitted to keep asking if tracking is denied, but they do similarly rely on the assumption a user can meaningfully consent to a cascading system of trackers.
In fact, the similarities and differences between cookie banner laws and App Tracking Transparency are considerable. Both require some form of consent mechanism immediately upon accessing a website or an app, assuming a user can provide that choice. Neither can promise tracking will not occur should a user deny the request. Both are interruptive.
But cookie consent laws typically offer users more information; many European websites, for example, enumerate all their third-party trackers, while App Tracking Transparency gives users no visibility into which trackers will be allowed. The latter choice is remembered forever unless a user removes and reinstalls the app, while websites can ask you for cookie consent on each visit. Perhaps the latter may sometimes be a consequence of using Safari; it is hard to know.
App Tracking Transparency also has a system-wide switch to opt out of all third-party tracking. There used to be something similar in web browsers, but compliance was entirely optional. Its successor effort, Global Privacy Control, is sadly not as widely supported as it ought to be, but it appears to have legal teeth.
Both of these systems have another important thing in common: neither are sufficiently protective of users’ privacy because they burden individuals with the responsibility of assessing something they cannot reasonably comprehend. It is patently ridiculous to put the responsibility on individuals to mitigate a systemic problem like invasive tracking schemes.
There should be a next step to regulations like these because user tracking is not limited to browsers where Ghostery can help — if you know about it. A technological response is frustrating and it is unclear to me how effective it is on its own. This is clearly not a problem only regulation can solve but neither can browser extensions. We need both.
Since 2022, the European Parliament has been trying to pass legislation requiring digital service providers to scan for and report CSAM as it passes through their services.
Welcomed by some child welfare organisations, the regulation has nevertheless been met with alarm from privacy advocates and tech specialists who say it will unleash a massive new surveillance system and threaten the use of end-to-end encryption, currently the ultimate way to secure digital communications from prying eyes.
[…]
The proposed regulation is excessively “influenced by companies pretending to be NGOs but acting more like tech companies”, said Arda Gerkens, former director of Europe’s oldest hotline for reporting online CSAM.
This is going to require a little back-and-forth, and I will pick up the story with quotations from Matthew Green’s introductory remarks to a panel before the European Internet Services Providers Association in March 2023:
The only serious proposal that has attempted to address this technical challenge was devised — and then subsequently abandoned — by Apple in 2021. That proposal aimed only at detecting known content using a perceptual hash function. The company proposed to use advanced cryptography to “split” the evaluation of hash comparisons between the user’s device and Apple’s servers: this ensured that the device never received a readable copy of the hash database.
[…]
The Commission’s Impact Assessment deems the Apple approach to be a success, and does not grapple with this failure. I assure you that this is not how it is viewed within the technical community, and likely not within Apple itself. One of the most capable technology firms in the world threw all their knowledge against this problem, and were embarrassed by a group of hackers: essentially before the ink was dry on their proposal.
Now leaked internal EU legal advice, which was presented to diplomats from the bloc’s member states on 27 April and has been seen by the Guardian, raises significant doubts about the lawfulness of the regulation unveiled by the European Commission in May last year.
In the adopted text, MEPs excluded end-to-end encryption from the scope of the detection orders to guarantee that all users’ communications are secure and confidential. Providers would be able to choose which technologies to use as long as they comply with the strong safeguards foreseen in the law, and subject to an independent, public audit of these technologies.
While some American officials continue to attack strong encryption as an enabler of child abuse and other crimes, a key European court has upheld it as fundamental to the basic right to privacy.
[…]
The court praised end-to-end encryption generally, noting that it “appears to help citizens and businesses to defend themselves against abuses of information technologies, such as hacking, identity and personal data theft, fraud and the improper disclosure of confidential information.”
This is not directly about the proposed CSAM measures, but it is precedent for European regulators to follow.
The most recent Council proposal, which was put forward in May under the Belgian presidency, includes a requirement that “providers of interpersonal communications services” (aka messaging apps) install and operate what the draft text describes as “technologies for upload moderation”, per a text published by Netzpolitik.
Article 10a, which contains the upload moderation plan, states that these technologies would be expected “to detect, prior to transmission, the dissemination of known child sexual abuse material or of new child sexual abuse material.”
Instead of accepting this fundamental mathematical reality, some European countries continue to play rhetorical
games. They’ve come back to the table with the same idea under a new label. Instead of using the previous term “client-side scanning,” they’ve rebranded and are now calling it “upload moderation.” Some are claiming that “upload moderation” does not undermine encryption because it happens before your message or video is
encrypted. This is untrue.
Only Germany, Luxembourg, the Netherlands, Austria and Poland are relatively clear that they will not support the proposal, but this is not sufficient for a “blocking minority”.
The exact quote from [Věra Jourová] the Commissioner for Values & Transparency: “the Commission proposed the method or the rule that even encrypted messaging can be broken for the sake of better protecting children”
Coming back to the initial question: does installing surveillance software on every phone “break encryption”? The scientist in me squirms at the question. But if we rephrase as “does this proposal undermine and break the *protections offered by encryption*”: absolutely yes.
It was known that the qualified majority required to approve the proposal would be very small, particularly following the harsh criticism of privacy experts on Wednesday and Thursday.
[…]
“[On Thursday morning], it soon became clear that the required qualified majority would just not be met. The Presidency therefore decided to withdraw the item from today’s agenda, and to continue the consultations in a serene atmosphere,” a Belgian EU Presidency source told The Brussels Times.
That is a truncated history of this piece of legislation: regulators want platform operators to detect and report CSAM; platforms and experts say that will conflict with security and privacy promises, even if media is scanned prior to encryption. This proposal may be specific to the E.U., but you can find similar plans to curtail or invalidate end-to-end encryption around the world:
In Australia, lawmakers at long last clarified they do not expect technology providers to evade end-to-end encryption — but they tried really hard to make that happen.
The United Kingdom has laid the groundwork for working around encryption when “feasible technology” exists, but it also seems to allow Ofcom to compel businesses to develop it.
I selected English-speaking areas because that is the language I can read, but I am sure there are more regions facing threats of their own.
We are not served by pretending this threat is limited to any specific geography. The benefits of end-to-end encryption are being threatened globally. The E.U.’s attempt may have been pushed aside for now, but another will rise somewhere else, and then another. It is up to civil rights organizations everywhere to continue arguing for the necessary privacy and security protections offered by end-to-end encryption.
After Robb Knight found — and Wired confirmed — Perplexity summarizes websites which have followed its opt out instructions, I noticed a number of people making a similar claim: this is nothing but a big misunderstanding of the function of controls like robots.txt. A Hacker News comment thread contains several versions of these two arguments:
robots.txt is only supposed to affect automated crawling of a website, not explicit retrieval of an individual page.
It is fair to use a user agent string which does not disclose automated access because this request was not automated per se, as the user explicitly requested a particular page.
That is, publishers should expect the controls provided by Perplexity to apply only to its indexing bot, not a user-initiated page request. Wary of being the kind of person who replies to pseudonymous comments on Hacker News, this is an unnecessarily absolutist reading of how site owners expect the Robots Exclusion Protocol to work.
To be fair, that protocol was published in 1994, well before anyone had to worry about websites being used as fodder for large language model training. And, to be fairer still, it has never been formalized. A spec was only recently proposed in September 2022. It has so far been entirely voluntary, but the draft standard proposes a more rigid expectation that rules will be followed. Yet it does not differentiate between different types of crawlers — those for search, others for archival purposes, and ones which power the surveillance economy — and contains no mention of A.I. bots. Any non-human means of access is expected to comply.
The question seems to be whether what Perplexity is doing ought to be considered crawling. It is, after all, responding to a direct retrieval request from a user. This is subtly different from how a user might search Google for a URL, in which case they are asking whether that site is in the search engine’s existing index. Perplexity is ostensibly following real-time commands: go fetch this webpage and tell me about it.
But it clearly is also crawling in a more traditional sense. The New York Times and Wired both disallow PerplexityBot, yet I was able to ask it to summarize a set of recent stories from bothpublications. At the time of writing, the Wired summary is about seventeen hours outdated, and the Times summary is about two days old. Neither publication has changed its robots.txt directives recently; they were both blocking Perplexity last week, and they are blocking it today. Perplexity is not fetching these sites in real-time as a human or web browser would. It appears to be scraping sites which have explicitly said that is something they do not want.
Perplexity should be following those rules and it is shameful it is not. But what if you ask for a real-time summary of a particular page, as Knight did? Is that something which should be identifiable by a publisher as a request from Perplexity, or from the user?
The Robots Exclusion Protocol may be voluntary, but a more robust method is to block bots by detecting their user agent string. Instead of expecting visitors to abide by your “No Homers Club” sign, you are checking IDs. But these strings are unreliable and there are often good reasons for evading user agent sniffing.
Perplexity says its bot is identifiable by both its user agent and the IP addresses from which it operates. Remember: this whole controversy is that it sometimes discloses neither, making it impossible to differentiate Perplexity-originating traffic from a real human being — and there is a difference.
A webpage being rendered through a web browser is subject to the quirks and oddities of that particular environment — ad blockers, Reader mode, screen readers, user style sheets, and the like — but there is a standard. A webpage being rendered through Perplexity is actually being reinterpreted and modified. The original text of the page is transformed through automated means about which neither the reader or the publisher has any understanding.
This is true even if you ask it for a direct quote. I asked for a full paragraph of a recent article and it mashed together two separate sections. They are direct quotes, to be sure, but the article must have been interpreted to generate this excerpt.1
It is simply not the case that requesting a webpage through Perplexity is akin to accessing the page via a web browser. It is more like automated traffic — even if it is being guided by a real person.
The existing mechanisms for restricting the use of bots on our websites are imperfect and limited. Yet they are the only tools we have right now to opt out of participating in A.I. services if that is something one wishes to do, short of putting pages or an entire site behind a user name and password. It is completely reasonable for someone to assume their signal of objection to any robotic traffic ought to be respected by legitimate businesses. The absolute least Perplexity can do is respecting those objections by clearly and consistently identifying itself, and excluding websites which have indicated they do not want to be accessed by these means.
I am not presently blocking Perplexity, and my argument is not related to its ability to access the article. I am only illustrating how it reinterprets text. ↥︎
If you had just been looking at the headlines from major research organizations, you would see a lack of confidence from the public in big business, technology companies included. For years, poll after poll from around the world has found high levels of distrust in their influence, handling of private data, and new developments.
If these corporations were at all worried about this, they are not much showing it in their products — particularly the A.I. stuff they have been shipping. There has been little attempt at abating last year’s trust crisis. Google decided to launch overconfident summaries for a variety of search queries. Far from helping to sift through all that has ever been published on the web to mash together a representative summary, it was instead an embarrassing mess that made the company look ill prepared for the concept of satire. Microsoft announced a product which will record and interpret everything you do and see on your computer, but as a good thing.
Can any of them see how this looks? If not — if they really are that unaware — why should we turn to them to fill gaps and needs in society? I certainly would not wish to indulge businesses which see themselves as entirely separate from the world.
It is hard to imagine they do not, though. Sundar Pichai, in an interview with Nilay Patel, recognised there were circumstances in which an A.I. summary would be inappropriate, and cautioned that the company still considers it a work in progress. Yet Google still turned it on by default in the U.S. with plans to expand worldwide this year.
Microsoft has responded to criticism by promising Recall will now be a feature users must opt into, rather than something they must turn off after updating Windows. The company also says there are more security protections for Recall data than originally promised but, based on its track record, maybe do not get too excited yet.
These product introductions all look like hubris. Arrogance, really — recognition of the significant power these corporations wield and the lack of competition they face. Google can poison its search engine because where else are most people going to go? How many people would turn off Recall, something which requires foreknowledge of its existence, under Microsoft’s original rollout strategy?
It is more or less an admission they are all comfortable gambling with their customers’ trust to further the perception they are at the forefront of the new hotness.
None of this is a judgement on the usefulness of these features or their social impact. I remain perplexed by the combination of a crisis of trust in new technologies, and the unwillingness of the companies responsible to engage with the public. There seems to be little attempt at persuasion. Instead, we are told to get on board because this rocket ship is taking off with or without us. Concerned? Too bad: the rocket ship is shaped like a giant middle finger.
What I hope we see Monday from Apple — a company which has portrayed itself as more careful and practical than many of its contemporaries — is a recognition of how this feels from outside the industry. Expect “A.I.” to be repeated in the presentation until you are sick of those two letters; investors are going to eat it up. When normal people update their phones in September, though, they should not feel like they are being bullied into accepting our A.I. future.
People need to be given time to adjust and learn. If the polls are representative, very few people trust giant corporations to get this right — understandably — yet these tech companies seem to believe we are as enthusiastic about every change they make as they are. Sorry, we are not, no matter how big a smile a company representative is wearing when they talk about it. Investors may not be patient but many of the rest of us need time.
Apple finished naming what it — well, its “team of experts alongside a select group of artists […] songwriters, producers, and industry professionals” — believes are the hundred best albums of all time. Like pretty much every list of the type, it is overwhelmingly Anglocentric, there are obvious picks, surprise appearances good and bad, and snubs.
I am surprised the publication of this list has generated as much attention as it has. There is a whole Wall Street Journal article with more information about how it was put together, a Slate thinkpiece arguing this ranking “proves [Apple has] lost its way”, and a Variety article claiming it is more-or-less “rage bait”.
Frankly, none of this feels sincere. Not Apple’s list, and not the coverage treating it as meaningful art criticism. I am sure there are people who worked hard on it — Apple told the Journal “about 250” — and truly believe their rating carries weight. But it is fluff.
Make no mistake: this is a promotional exercise for Apple Music more than it is criticism. Sure, most lists of this type are also marketing for publications like Rolling Stone and Pitchfork and NME. Yet, for how tepid the opinions of each outlet often are, they have each given out bad reviews. We can therefore infer they have specific tastes and ideas about what separates great art from terrible art.
Apple has never said a record is bad. It has never made you question whether the artist is trying their best. It has never presented criticism so thorough it makes you wince on behalf of the people who created the album.
Perhaps the latter is a poor metric. After Steve Jobs’ death came a river of articles questioning the internal culture he fostered, with several calling him an “asshole”. But that is mixing up a mean streak and a critical eye — Jobs, apparently, had both. A fair critic can use their words to dismantle an entire project and explain why it works or, just as important, why it does not. The latter can hurt; ask any creative person who has been on the receiving end. Yet exploring why something is not good enough is an important skill to develop as both a critic and a listener.
There has been a lot of discussion about what music criticism is for since streaming reduced the cost of listening to new songs to basically zero. The conceit is that before everything was free, the function of criticism was to tell listeners which albums to buy, but I don’t think that was ever it. The function of criticism is and has always been to complicate our sense of beauty. Good criticism of music we love — or, occasionally, really hate — increases the dimensions and therefore the volume of feeling. It exercises that part of ourselves which responds to art, making it stronger.
There are huge problems with the way music has historically been critiqued, most often along racial and cultural lines. There are still problems. We will always disagree about the fairness of music reviews and reviewers.
Apple’s list has nothing to do with any of that. It does not interrogate which albums are boring, expressionless, uncreative, derivative, inconsequential, inept, or artistically bankrupt. So why should we trust it to explain what is good? Apple’s ranking of albums lacks substance because it cannot say any of these things. Doing so would be a terrible idea for the company and for artists.
It is beyond my understanding why anyone seems to be under the impression this list is anything more than a business reminding you it operates a music streaming platform to which you can subscribe for eleven dollars per month.
Speaking of the app — some time after I complained there was no way in Apple Music to view the list, Apple added a full section, which I found via foursliced on Threads. It is actually not bad. There are stories about each album, all the reveal episodes from the radio show, and interviews.
You will note something missing, however: a way to play a given album. That is, one cannot visit this page in Apple Music, see an album on the list they are interested in, and simply tap to hear it. There are play buttons on the website and, if you are signed in with your Apple Music account, you can add them to your library. But I cannot find a way to do any of this from within the app.
Benjamin Mayo found a list, but I cannot through search or simply by browsing. Why is this not a more obvious feature? It makes me feel like a dummy.
Finally. The government of the United States finally passed a law that would allow it to force the sale of, or ban, software and websites from specific countries of concern. The target is obviously TikTok — it says so right in its text — but crafty lawmakers have tried to add enough caveats and clauses and qualifiers to, they hope, avoid it being characterized as a bill of attainder, and to permit future uses. This law is very bad. It is an ineffective and illiberal position that abandons democratic values over, effectively, a single app. Unfortunately, TikTok panic is a very popularposition in the U.S. and, also, here in Canada.
The adversaries the U.S. is worried about are the “covered nations” defined in 2018 to restrict the acquisition by the U.S. of key military materials from four countries: China, Iran, North Korea, and Russia. The idea behind this definition was that it was too risky to procure magnets and other important components of, say, missiles and drones from a nation the U.S. considers an enemy, lest those parts be compromised in some way. So the U.S. wrote down its least favourite countries for military purposes, and that list is now being used in a bill intended to limit TikTok’s influence.
According to the law, it is illegal for any U.S. company to make available TikTok and any other ByteDance-owned app — or any app or website deemed a “foreign adversary controlled application” — to a user in the U.S. after about a year unless it is sold to a company outside the covered countries, and with no more than twenty percent ownership stake from any combination of entities in those four named countries. Theoretically, the parent company could be based nearly anywhere in the world; practically, if there is a buyer, it will likely be from the U.S. because of TikTok’s size. Also, the law specifically exempts e-commerce apps for some reason.
This could be interpreted as either creating an isolated version specifically for U.S. users or, as I read it, moving the global TikTok platform to a separate organization not connected to ByteDance or China.1 ByteDance’s ownership is messy, though mostly U.S.-based, but politicians worried about its Chinese origin have had enough, to the point they are acting with uncharacteristic vigour. The logic seems to be that it is necessary for the U.S. government to influence and restrict speech in order to prevent other countries from influencing or restricting speech in ways the U.S. thinks are harmful. That is, the problem is not so much that TikTok is foreign-owned, but that it has ownership ties to a country often antithetical to U.S. interests. TikTok’s popularity might, it would seem, be bad for reasons of espionage or influence — or both.
Power
So far, I have focused on the U.S. because it is the country that has taken the first step to require non-Chinese control over TikTok — at least for U.S. users but, due to the scale of its influence, possibly worldwide. It could force a business to entirely change its ownership structure. So it may look funny for a Canadian to explain their views of what the U.S. ought to do in a case of foreign political interference. This is a matter of relevance in Canada as well. Our federal government raised the alarm on “hostile state-sponsored or influenced actors” influencing Canadian media and said it had ordered a security review of TikTok. There was recently a lengthy public inquiry into interference in Canadian elections, with a special focus on China, Russia, and India. Clearly, the popularity of a Chinese application is, in the eyes of these officials, a threat.
Yet it is very hard not to see the rush to kneecap TikTok’s success as a protectionist reaction to shaking the U.S. dominance of consumer technologies, as convincingly expressed by Paris Marx at Disconnect:
In Western discourses, China’s internet policies are often positioned solely as attempts to limit the freedoms of Chinese people — and that can be part of the motivation — but it’s a politically convenient explanation for Western governments that ignores the more important economic dimension of its protectionist approach. Chinese tech is the main competitor to Silicon Valley’s dominance today because China limited the ability of US tech to take over the Chinese market, similar to how Japan and South Korea protected their automotive and electronics industries in the decades after World War II. That gave domestic firms the time they needed to develop into rivals that could compete not just within China, but internationally as well. And that’s exactly why the United States is so focused not just on China’s rising power, but how its tech companies are cutting into the global market share of US tech giants.
This seems like one reason why the U.S. has so aggressively pursued a divestment or ban since TikTok’s explosive growth in 2019 and 2020. On its face it is similar to some reasons why the E.U. has regulated U.S. businesses that have, it argues, disadvantaged European competitors, and why Canadian officials have tried to boost local publications that have seen their ad revenue captured by U.S. firms. Some lawmakers make it easy to argue it is a purely xenophobic reaction, like Senator Tom Cotton, who spent an exhausting minute questioning TikTok’s Singaporean CEO Shou Zi Chew about where he is really from. But I do not think it is entirely a protectionist racket.
A mistake I have made in the past — and which I have seen some continue to make — is assuming those who are in favour of legislating against TikTok are opposed to the kinds of dirty tricks it is accused of on principle. This is false. Many of these same people would be all too happy to allow U.S. tech companies to do exactly the same. I think the most generous version of this argument is one in which it is framed as a dispute between the U.S. and its democratic allies, and anxieties about the government of China — ByteDance is necessarily connected to the autocratic state — spreading messaging that does not align with democratic government interests. This is why you see few attempts to reconcile common objections over TikTok with the quite similar behaviours of U.S. corporations, government arms, and intelligence agencies. To wit: U.S.-based social networks also suggest posts with opaque math which could, by the same logic, influence elections in other countries. They also collect enormous amounts of personal data that is routinely wiretapped, and are required to secretly cooperate with intelligence agencies. The U.S. is not authoritarian as China is, but the behaviours in question are not unique to authoritarians. Those specific actions are unfortunately not what the U.S. government is objecting to. What it is disputing, in a most generous reading, is a specifically antidemocratic government gaining any kind of influence.
Espionage and Influence
It is easiest to start by dismissing the espionage concerns because they are mostly misguided. The peek into Americans’ lives offered by TikTok is no greater than that offered by countless ad networks and data brokers — something the U.S. is also trying to restrict more effectively through a comprehensive federal privacy law. So long as online advertising is dominated by a privacy-hostile infrastructure, adversaries will be able to take advantage of it. If the goal is to restrict opportunities for spying on people, it is idiotic to pass legislation against TikTok specifically instead of limiting the data industry.
But the charge of influence seems to have more to it, even though nobody has yet shown that TikTok is warping users’ minds in a (presumably) pro-China direction. Some U.S. lawmakers described its danger as “theoretical”; others seem positively terrified. There are a few different levels to this concern: are TikTok users uniquely subjected to Chinese government propaganda? Is TikTok moderated in a way that boosts or buries videos to align with Chinese government views? Finally, even if both of these things are true, should the U.S. be able to revoke access to software if it promotes ideologies or viewpoints — and perhaps explicit propaganda? As we will see, it looks like TikTok sometimes tilts in ways beneficial — or, at least, less damaging — to Chinese government interests, but there is no evidence of overt government manipulation and, even if there were, it is objectionable to require it to be owned by a different company or ban it.
The main culprit, it seems, is TikTok’s “uncannily good” For You feed that feels as though it “reads your mind”. Instead of users telling TikTok what they want to see, it just begins showing videos and, as people use the app, it figures out what they are interested in. How it does this is not actually that mysterious. A 2021 Wall Street Journal investigation found recommendations were made mostly based on how long you spent watching each video. Deliberate actions — like sharing and liking — play a role, sure, but if you scroll past videos of people and spend more time with a video of a dog, it learns you want dog videos.
That is not so controversial compared to the opacity in how TikTok decides what specific videos are displayed and which ones are not. Why is this particular dog video in a user’s feed and not another similar one? Why is it promoting videos reflecting a particular political viewpoint or — so a popular narrative goes — burying those with viewpoints uncomfortable for its Chinese parent company? The mysterious nature of an algorithmic feed is the kind of thing into which you can read a story of your choosing. A whole bunch of X users are permanently convinced they are being “shadow banned” whenever a particular tweet does not get as many likes and retweets as they believe it deserved, for example, and were salivating at the thought of the company releasing its ranking code to solve a nonexistent mystery. There is a whole industry of people who say they can get your website to Google’s first page for a wide range of queries using techniques that are a mix of plausible and utterly ridiculous. Opaque algorithms make people believe in magic. An alarmist reaction to TikTok’s feed should be expected particularly as it was the first popular app designed around entirely recommended material instead of personal or professional connections. This has now been widely copied.
March 2023 brought a renewed effort to divest or ban the platform. Chew, TikTok’s CEO, was called to a U.S. Congressional hearing and questioned for hours, to little effect. During that hearing, a report prepared for the Australian government was cited by some of the lawmakers, and I think it is a telling document. It is about eighty pages long — excluding its table of contents, appendices, and citations — and shows several examples of Chinese government influence on other products made by ByteDance. However, the authors found no such manipulation on TikTok itself, leading them to conclude:
In our view, ByteDance has demonstrated sufficient capability, intent, and precedent in promoting Party propaganda on its Chinese platforms to generate material risk that they could do the same on TikTok.
“They could do the same”, emphasis mine. In other words, if they had found TikTok was boosting topics and videos on behalf of the Chinese government, they would have said so — so they did not. The closest thing I could find to a covert propaganda campaign on TikTok anywhere in this report is this:
The company [ByteDance] tried to do the same on TikTok, too: In June 2022, Bloomberg reported that a Chinese government entity responsible for public relations attempted to open a stealth account on TikTok targeting Western audiences with propaganda”. [sic]
If we follow the Bloomberg citation — shown in the report as a link to the mysterious Archive.today site — the fuller context of the article by Olivia Solondisproves the impression you might get from reading the report:
In an April 2020 message addressed to Elizabeth Kanter, TikTok’s head of government relations for the UK, Ireland, Netherlands and Israel, a colleague flagged a “Chinese government entity that’s interested in joining TikTok but would not want to be openly seen as a government account as the main purpose is for promoting content that showcase the best side of China (some sort of propaganda).”
The messages indicate that some of ByteDance’s most senior government relations team, including Kanter and US-based Erich Andersen, Global Head of Corporate Affairs and General Counsel, discussed the matter internally but pushed back on the request, which they described as “sensitive.” TikTok used the incident to spark an internal discussion about other sensitive requests, the messages state.
This is the opposite conclusion to how this story was set up in the report. Chinese government public relations wanted to set up a TikTok account without any visible state connection and, when TikTok management found out about this, it said no. This Bloomberg article makes TikTok look good in the face of government pressure, not like it capitulates. Yes, it is worth being skeptical of this reporting. Yet if TikTok acquiesced to the government’s demands, surely the report would provide some evidence.
While this report for the Australian Senate does not show direct platform manipulation, it does present plenty of examples where it seems like TikTok may be biased or self-censoring. Its authors cite stories from the Washington Post and Vice finding posts containing hashtags like #HongKong and #FreeXinjiang returned results favourable to the official Chinese government position. Sometimes, related posts did not appear in search results, which is not unique to TikTok — platforms regularly use crude search term filtering to restrict discovery for lots of reasons. I would not be surprised if there were bias or self-censorship to blame for TikTok minimizing the visibility of posts critical of the subjugation of Uyghurs in China. However, it is basically routine for every social media product to be accused of suppression. The Markup found different types of posts on Instagram, for example, had captions altered or would no longer appear in search results, though it is unclear to anyone why that is the case. Meta said it was a bug, an explanation also offered frequently by TikTok.
The authors of the Australian report conducted a limited quasi-study comparing results for certain topics on TikTok to results on other social networks like Instagram and YouTube, again finding a handful of topics which favoured the government line. But there was no consistent pattern, either. Search results for “China military” on Instagram were, according to the authors, “generally flattering”, and X searches for “PLA” scarcely returned unfavourable posts. Yet results on TikTok for “China human rights”, “Tianamen”, and “Uyghur” were overwhelmingly critical of Chinese official positions.
The Network Contagion Research Institute published its own report in December 2023, similarly finding disparities between the total number of posts with specific hashtags — like #DalaiLama and #TiananmenSquare — on TikTok and Instagram. However, the study contained some pretty fundamental errors, as pointed out by — and I cannot believe I am citing these losers — the Cato Institute. The study’s authors compared total lifetime posts on each social network and, while they say they expect 1.5–2.0× the posts on Instagram because of its larger user base, they do not factor in how many of those posts could have existed before TikTok was even launched. Furthermore, they assume similar cultures and a similar use of hashtags on each app. But even benign hashtags have ridiculous differences in how often they are used on each platform. There are, as of writing, 55.3 million posts tagged “#ThrowbackThursday” on Instagram compared to 390,000 on TikTok, a ratio of 141:1. If #ThrowbackThursday were part of this study, the disparity on the two platforms would rank similarly to #Tiananmen, one of the greatest in the Institute’s report.
The problem with most of these complaints, as their authors acknowledge, is that there is a known input and a perceived output, but there are oh-so-many unknown variables in the middle. It is impossible to know how much of what we see is a product of intentional censorship, unintentional biases, bugs, side effects of other decisions, or a desire to cultivate a less stressful and more saccharine environment for users. A report by Exovera (PDF) prepared for the U.S.–China Economic and Security Review Commission indicates exactly the latter: “TikTok’s current content moderation strategy […] adheres to a strategy of ‘depoliticization’ (去政治化) and ‘localization’ (本土化) that seeks to downplay politically controversial speech and demobilize populist sentiment”, apparently avoiding “algorithmic optimization in order to promote content that evangelizes China’s culture as well as its economic and political systems” which “is liable to result in backlash”. Meta, on its own platforms, said it would not generally suggest “political” posts to users but did not define exactly what qualifies. It said its goal in limiting posts on social issues was because of user demand, but these types of posts have been difficult to moderate. A difference in which posts are found on each platform for specific search terms is not necessarily reflective of government pressure, deliberate or not. Besides, it is not as though there is no evidence for straightforward propaganda on TikTok. One just needs to look elsewhere to find it.
Propaganda
The Office of the Director of National Intelligence recently released its annual threat assessment summary (PDF). It is unclassified and has few details, so the only thing it notes about TikTok is “accounts run by a PRC propaganda arm reportedly targeted candidates from both political parties during the U.S. midterm election cycle in 2022”. It seems likely to me this is a reference to this article in Forbes, though this is a guess as there are no citations. The state-affiliated TikTok account in question — since made private — posted a bunch of news clips which portray the U.S. in an unflatteringlight. There is a related account, also marked as state-affiliated, which continues to post the same kinds of videos. It has over 33,000 followers, which sounds like a lot, but each post is typically getting only a few hundred views. Some have been viewed thousands of times, others as little as thirteen times as of writing — on a platform with exaggerated engagement numbers. Nonetheless, the conclusion is obvious: these accounts are government propaganda, and TikTok willingly hosts them.
But that is something it has in common with all social media platforms. The Russian RT News network and China’s People’s Daily newspaper have X and Facebook accounts with follower counts in the millions. Until recently, the North Korean newspaper Uriminzokkirioperated accounts on Instagram and X. It and other North Korean state-controlled media used to have YouTube channels, too, but they were shut down by YouTube in 2017 — a move that was protested by academics studying the regime’s activities. The irony of U.S.-based platforms helping to disseminate propaganda from the country’s adversaries is that it can be useful to understand them better. Merely making propaganda available — even promoting it — is a risk and also a benefit to generous speech permissions.
The DNI’s unclassified report has no details about whether TikTok is an actual threat, and the FBI has “nothing to add” in response to questions about whether TikTok is currently doing anything untoward. More secretive information was apparently provided to U.S. lawmakers ahead of their March vote and, though few details of what, exactly, was said, several were not persuaded by what they heard, including Rep. Sara Jacobs of California:
As a member of both the House Armed Services and House Foreign Affairs Committees, I am keenly aware of the threat that PRC information operations can pose, especially as they relate to our elections. However, after reviewing the intelligence, I do not believe that this bill is the answer to those threats. […] Instead, we need comprehensive data privacy legislation, alongside thoughtful guardrails for social media platforms – whether those platforms are funded by companies in the PRC, Russia, Saudi Arabia, or the United States.
Lawmakers like Rep. Jacobs were an exception among U.S. Congresspersons who, across party lines, were eager to make the case against TikTok. Ultimately, the divest-or-ban bill got wrapped up in a massive and politically popular spending package agreed to by both chambers of Congress. Its passage was enthusiastically received by the White House and it was signed into law within hours. Perhaps that outcome is the democratic one since polls so often find people in the U.S. support a sale or ban of TikTok.
I get it: TikTok scoops up private data, suggests posts based on opaque criteria, its moderation appears to be susceptible to biases, and it is a vehicle for propaganda. But you could replace “TikTok” in that sentence with any other mainstream social network and it would be just as true, albeit less scary to U.S. allies on its face.
A Principled Objection
Forcing TikTok to change its ownership structure whether worldwide or only for a U.S. audience is a betrayal of liberal democratic principles. To borrow from Jon Stewart, “if you don’t stick to your values when they’re being tested, they’re not values, they’re hobbies”. It is not surprising that a Canadian intelligence analysis specifically pointed out how those very same values are being taken advantage of by bad actors. This is not new. It is true of basically all positions hostile to democracy — from domestic nationalist groups in Canada and the U.S., to those which originate elsewhere.
Julian G. Ku, for China File, offered a seemingly reasonable rebuttal to this line of thinking:
This argument, while superficially appealing, is wrong. For well over one hundred years, U.S. law has blocked foreign (not just Chinese) control of certain crucial U.S. electronic media. The Protect Act [sic] fits comfortably within this long tradition.
Yet this counterargument falls apart both in its details and if you think about its further consequences. As Martin Peers writes at the Information, the U.S. does not prohibit all foreign ownership of media. And governing the internet like public airwaves gets way more complicated if you stretch it any further. Canada has broadcasting laws, too, and it is not alone. Should every country begin requiring social media platforms comply with laws designed for ownership of broadcast media? Does TikTok need disconnected local versions of its product in each country in which it operates? It either fundamentally upsets the promise of the internet, or it is mandating the use of protocols instead of platforms.
It also looks hypocritical. Countries with a more authoritarian bent and which openly censor the web have responded to even modest U.S. speech rules with mockery. When RT America — technically a U.S. company with Russian funding — was required to register as a foreign agent, its editor-in-chief sarcastically applauded U.S. free speech standards. The response from Chinese government officials and media outlets to the proposed TikTok ban has been similarly scoffing. Perhaps U.S. lawmakers are unconcerned about the reception of their policies by adversarial states, but it is an indicator of how these policies are being portrayed in these countries — a real-life “we are not so different, you and I” setup — that, while falsely equivalent, makes it easy for authoritarian states to claim that democracies have no values and cannot work. Unless we want to contribute to the fracturing of the internet — please, no — we cannot govern social media platforms by mirroring policies we ostensibly find repellant.
The way the government of China seeks to shape the global narrative is understandably concerning given its poor track record on speech freedoms. An October 2023 U.S. State Department “special report” (PDF) explored several instances where it boosted favourable narratives, buried critical ones, and pressured other countries — sometimes overtly, sometimes quietly. The government of China and associated businesses reportedly use social media to create the impression of dissent toward human rights NGOs, and apparently everything from university funding to new construction is a vector for espionage. On the other hand, China is terribly ineffective in its disinformation campaigns, and many of the cases profiled in that State Department report end in failure for the Chinese government initiative. In Nigeria, a pitch for a technologically oppressive “safe city” was rejected; an interview published in the Jerusalem Post with Taiwan’s foreign minister was not pulled down despite threats from China’s embassy in Israel. The report’s authors speculate about “opportunities for PRC global censorship”. But their only evidence is a “list [maintained by ByteDance] identifying people who were likely blocked or restricted” from using the company’s many platforms, though the authors can only speculate about its purpose.
The problem is that trying to address this requires better media literacy and better recognition of propaganda. That is a notoriously daunting problem. We are exposed to a more destabilizing cocktail of facts and fiction, but there is declining trust in experts and institutions to help us sort it out. Trying to address TikTok as a symptomatic or even causal component of this is frustratingly myopic. This stuff is everywhere.
Also everywhere is corporate propaganda arguing regulations would impede competition in a global business race. I hate to be mean by picking on anyone in particular, but a post from Om Malik has shades of this corporate slant. Malik is generally very good on the issues I care about, but this is not one we appear to agree on. After a seemingly impressed observation of how quickly Chinese officials were able to eject popular messaging apps from the App Store in the country, Malik compares the posture of each country’s tech industries:
As an aside, while China considers all its tech companies (like Bytedance) as part of its national strategic infrastructure, the United States (and its allies) think of Apple and other technology companies as public enemies.
This is laughable. Presumably, Malik is referring to the chillier reception these companies have faced from lawmakers, and antitrust cases against Amazon, Apple, Google, and Meta. But that tougher impression is softened by the U.S. government’s actual behaviour. When the E.U. announced the Digital Markets Act and Digital Services Act, U.S. officialssprang to the defenceof tech companies. Even before these cases, Uber expanded in Europe thanks in part to its close relationship with Obama administration officials, as Marx pointed out. The U.S. unquestionably sees its tech industry dominance as a projection of its poweraround the world, hardly treating those companies as “public enemies”.
Far more explicit were the narratives peddled by lobbyists from Targeted Victory in 2022 about TikTok’s dangers, and American Edge beginning in 2020 about how regulations will cause the U.S. to become uncompetitive with China and allow TikTok to win. Both organizations were paid by Meta to spread those messages; the latter was reportedly founded after a single large contribution from Meta. Restrictions on TikTok would obviously be beneficial to Meta’s business.
If you wanted to boost the industry — and I am not saying Malik is — that is how you would describe the situation: the U.S. is fighting corporations instead of treating them as pals to win this supposed race. It is not the kind of framing one uses if they wanted to dissuade people from the notion this is a protectionist dispute over the popularity of TikTok. But it is the kind of thing you hear from corporations via their public relations staff and lobbyists, which gets trickled into public conversation.
This Is Not a TikTok Problem
TikTok’s divestment would not be unprecedented. The Committee on Foreign Investment in the United States — henceforth, CFIUS, pronounced “siff-ee-us” — demanded, after a 2019 review, that Beijing Kunlun Tech Co Ltd sell Grindr. CFIUS concluded the risk to users’ private data was too great for Chinese ownership given Grindr’s often stigmatized and ostracized user base. After its sale, now safe in U.S. hands, a priest was outed thanks to data Grindr had been selling since before it was acquired by the Chinese firm, and it is being sued for allegedly sharing users’ HIV status with third parties. Also, because it transacts with data brokers, it potentially still leaks users’ private information to Chinese companies (PDF), apparently violating the fundamental concern triggering this divestment.
Perhaps there is comfort in Grindr’s owner residing in a country where same-sex marriage is legal rather than in one where it is not. I think that makes a lot of sense, actually. But there remain plenty of problems unaddressed by its sale to a U.S. entity.
Similarly, this U.S. TikTok law does not actually solve potential espionage or influence for a few reasons. The first is that it has not been established that either are an actual problem with TikTok. Surely, if this were something we ought to be concerned about, there would be a pattern of evidence, instead of what we actually have which is a fear something bad could happen and there would be no way to stop it. But many things could happen. I am not opposed to prophylactic laws so long as they address reasonable objections. Yet it is hard not to see this law as an outgrowth of Cold War fears over leaflets of communist rhetoric. It seems completely reasonable to be less concerned about TikTok specifically while harbouring worries about democratic backsliding worldwide and the growing power of authoritarian states like China in international relations.
Second, the Chinese government does not need local ownership if it wants to exert pressure. The world wants the country’s labour and it wants its spending power, so businesses comply without a fight, and often preemptively. Hollywood films are routinely changed before, during, and after production to fit the expectations of state censors in China, a pattern which has been pointed out using the same “Red Dawn” anecdote in story after story after story. (Abram Dylan contrasted this phenomenon with U.S. military cooperation.) Apple is only too happy to acquiesce to the government’s many demands — see the messaging apps issue mentioned earlier — including, reportedly, in its media programming. Microsoft continues to operate Bing in China, and its censorship requirements have occasionally spilled elsewhere. Economic leverage over TikTok may seem different because it does not need access to the Chinese market — TikTok is banned in the country — but perhaps a new owner would be reliant upon China.
Third, the law permits an ownership stake no greater than twenty percent from a combination of any of the “covered nations”. I would be shocked if everyone who is alarmed by TikTok today would be totally cool if its parent company were only, say, nineteen percent owned by a Chinese firm.
If we are worried about bias in algorithmically sorted feeds, there should be transparency around how things are sorted, and more controls for users including wholly opting out. If we are worried about privacy, there should be laws governing the collection, storage, use, and sharing of personal information. If ownership ties to certain countries is concerning, there are more direct actions available to monitor behaviour. I am mystified why CFIUS and TikTok apparently abandoned (PDF) a draft agreement that would give U.S.-based entities full access to the company’s systems, software, and staff, and would allow the government to end U.S. access to TikTok at a moment’s notice.
Any of these options would be more productive than this legislation. It is a law which empowers the U.S. president — whoever that may be — to declare the owner of an app with a million users a “covered company” if it is from one of those four nations. And it has been passed. TikTok will head to court to dispute it on free speech grounds, and the U.S. may respond by justifying its national security concerns.
Obviously, the U.S. government has concerns about the connections between TikTok, ByteDance, and the government of China, which have been extensively reported. Rest of World says ByteDance put pressure on TikTok to improve its financial performance and has taken greater control by bringing in management from Douyin. The Wall Street Journal says U.S. user data is not fully separated. And, of course, Emily Baker-White has reported — first for Buzzfeed News and now for Forbes — a litany of stories about TikTok’s many troubling behaviours, including spying on her. TikTok is a well scrutinized app and reporters have found conduct that has understandably raised suspicions. But virtually all of these stories focus on data obtained from users, which Chinese agencies could do — and probably are doing — without relying on TikTok. None of them have shown evidence that TikTok’s suggestions are being manipulated at the behest or demand of Chinese officials. The closest they get is an article from Baker-White and Iain Martin which alleges TikTok “served up a flood of ads from Chinese state propaganda outlets”, yet waiting until the third-to-last paragraph before acknowledging “Meta and Google ad libraries show that both platforms continue to promote pro-China narratives through advertising”. All three platforms label state-run media outlets, albeit inconsistently. Meanwhile, U.S.-owned X no longer labels any outlets with state editorial control. It is not clear to me that TikTok would necessarily operate to serve the best interests of the U.S. even if it was owned by some well-financed individual or corporation based there.
For whatever it is worth, I am not particularly tied to the idea that the government of China would not use TikTok as a vehicle for influence. The government of China is clearly involved in propaganda efforts both overt and covert. I do not know how much of my concerns are a product of living somewhere with a government and a media environment that focuses intently on the country as particularly hostile, and not necessarily undeservedly. The best version of this argument is one which questions the platform’s possible anti-democratic influence. Yes, there are many versions of this which cross into moral panic territory — a new Red Scare. I have tried to put this in terms of a more reasonable discussion, and one which is not explicitly xenophobic or envious. But even this more even-handed position is not well served by the law passed in the U.S., one which was passed without evidence of influence much more substantial than some choice hashtag searches. TikTok’s response to these findings was, among other things, to limit its hashtag comparison tool, which is not a good look. (Meta is doing basically the same by shutting down CrowdTangle.)
I hope this is not the beginning of similar isolationist policies among democracies worldwide, and that my own government takes this opportunity to recognize the actual privacy and security threats at the heart of its own TikTok investigation. Unfortunately, the head of CSIS is really leaning on the espionage angle. For years, the Canadian government has been pitching sorely needed updates to privacy legislation, and it would be better to see real progress made to protect our private data. We can do better than being a perpetual recipient of decisions made by other governments. I mean, we cannot do much — we do not have the power of the U.S. or China or the E.U. — but we can do a little bit in our own polite Canadian way. If we are worried about the influence of these platforms, a good first step would be to strengthen the rights of users. We can do that without trying to governing apps individually, or treating the internet like we do broadcasting.
To put it more bluntly, the way we deal with a possible TikTok problem is by recognizing it is not a TikTok problem. If we care about espionage or foreign influence in elections, we should address those concerns directly instead of focusing on a single app or company that — at worst — may be a medium for those anxieties. These are important problems and it is inexcusable to think they would get lost in the distraction of whether TikTok is individually blameworthy.
Because this piece has taken me so long to write, a whole bunch of great analyses have been published about this law. I thought the discussion on “Decoder” was a good overview, especially since two of the three panelists are former lawyers. ↥︎
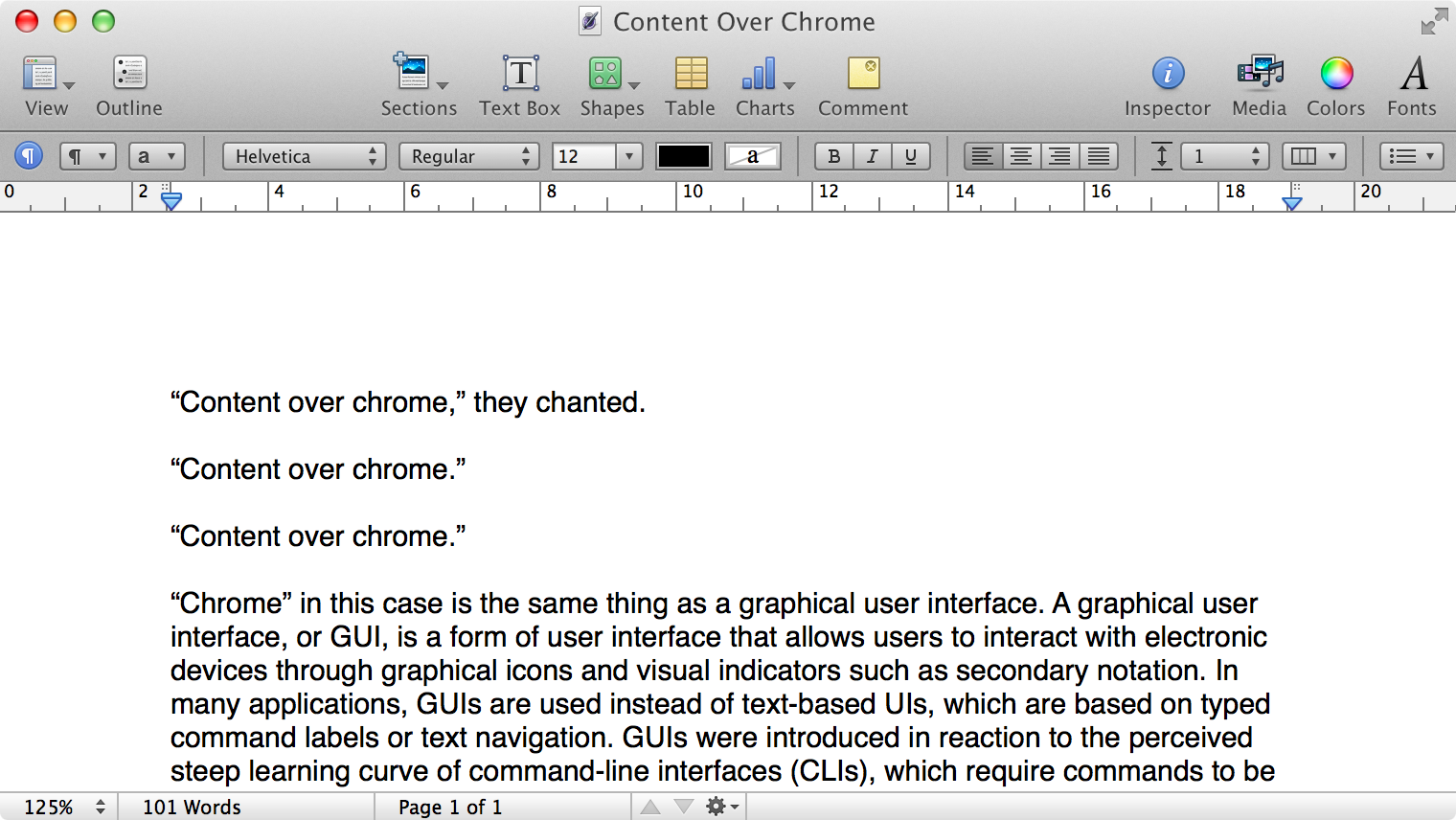
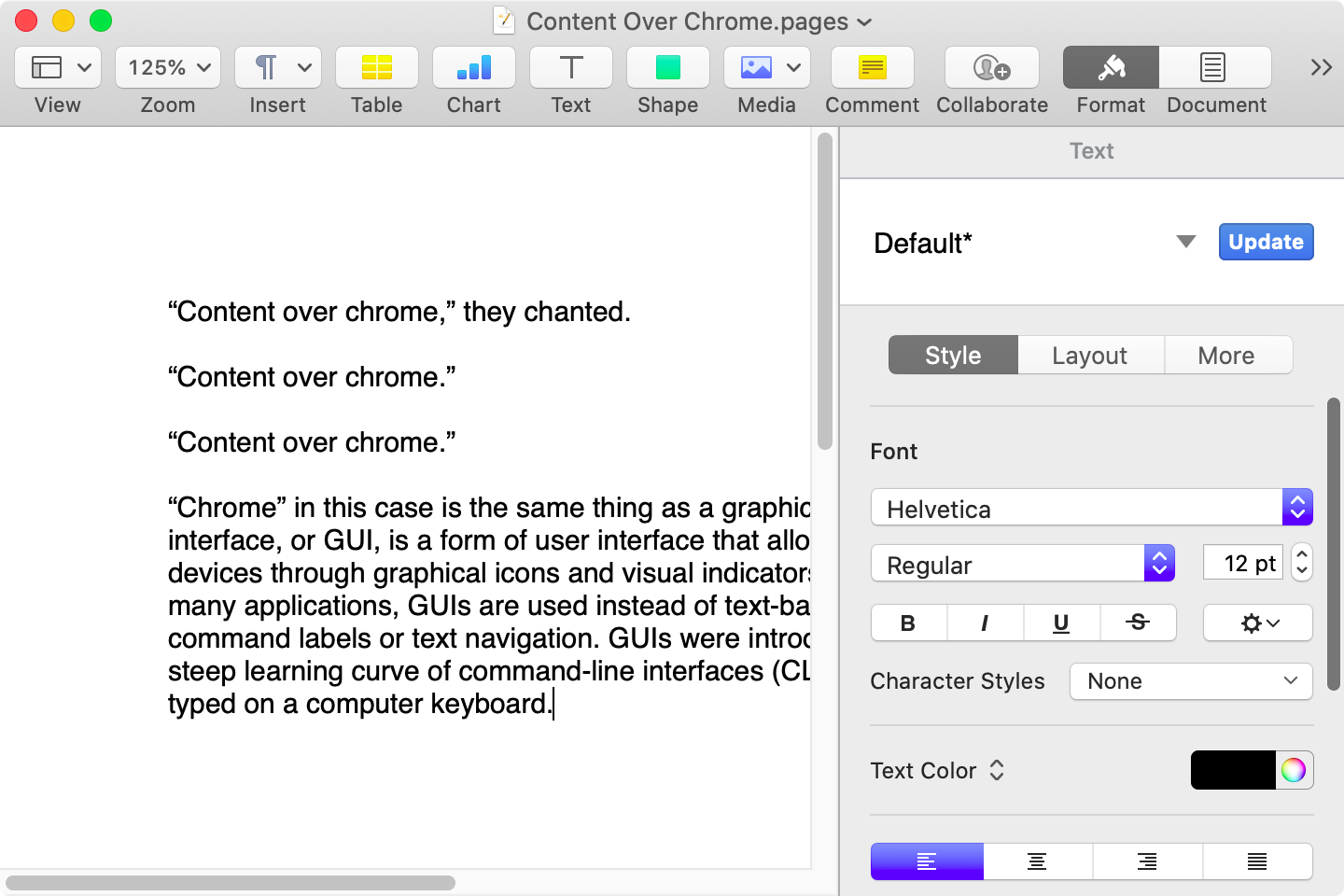
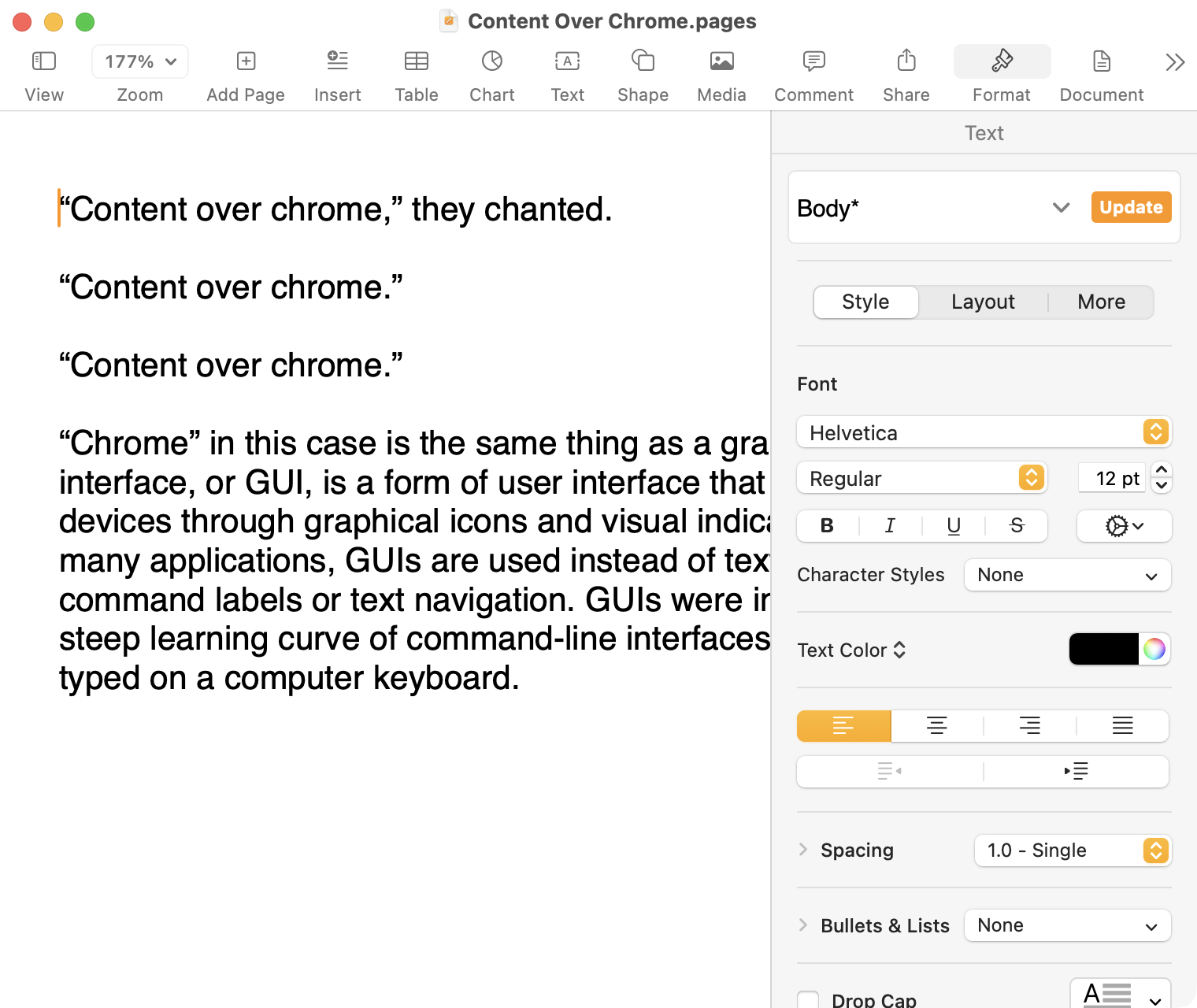
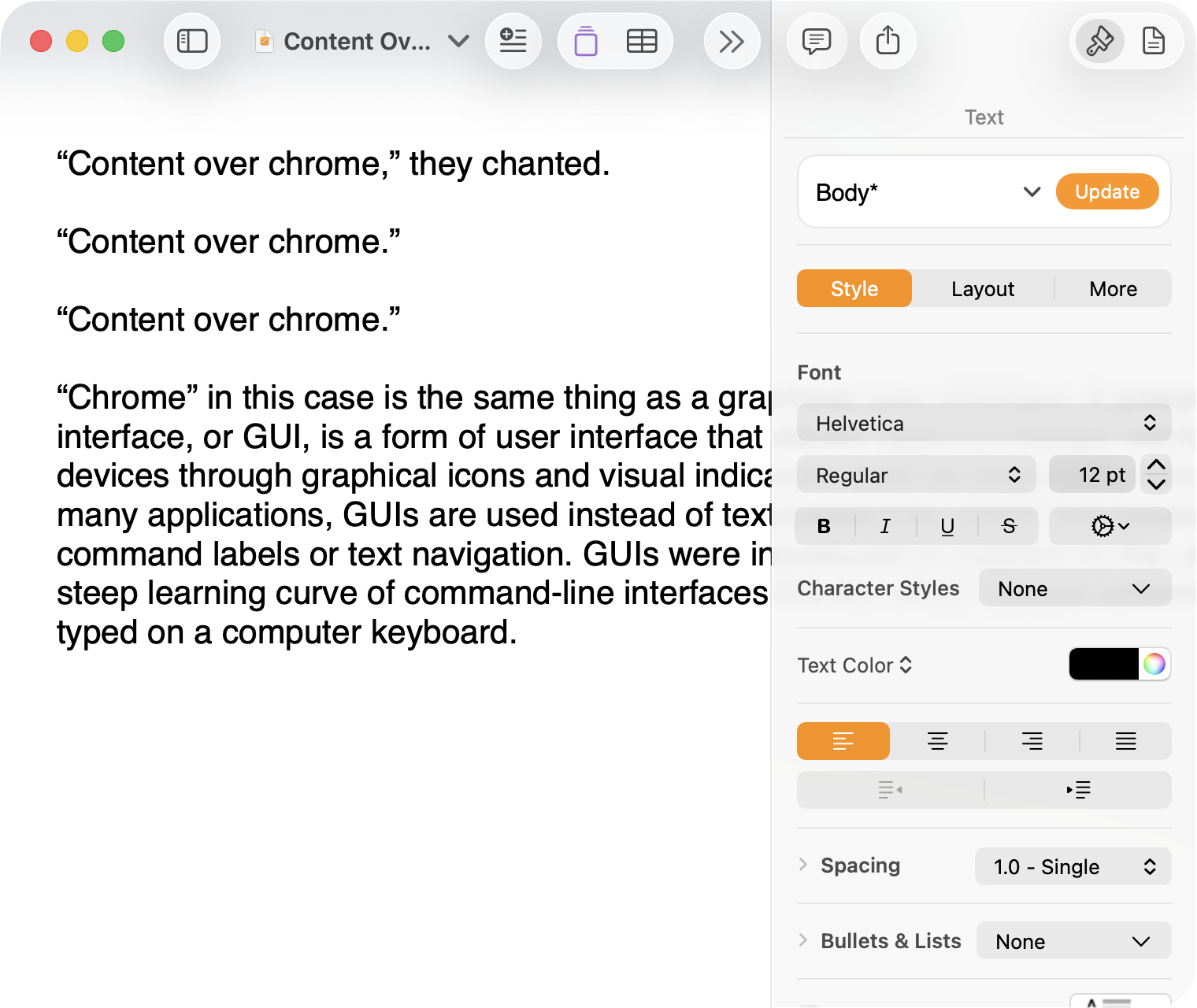
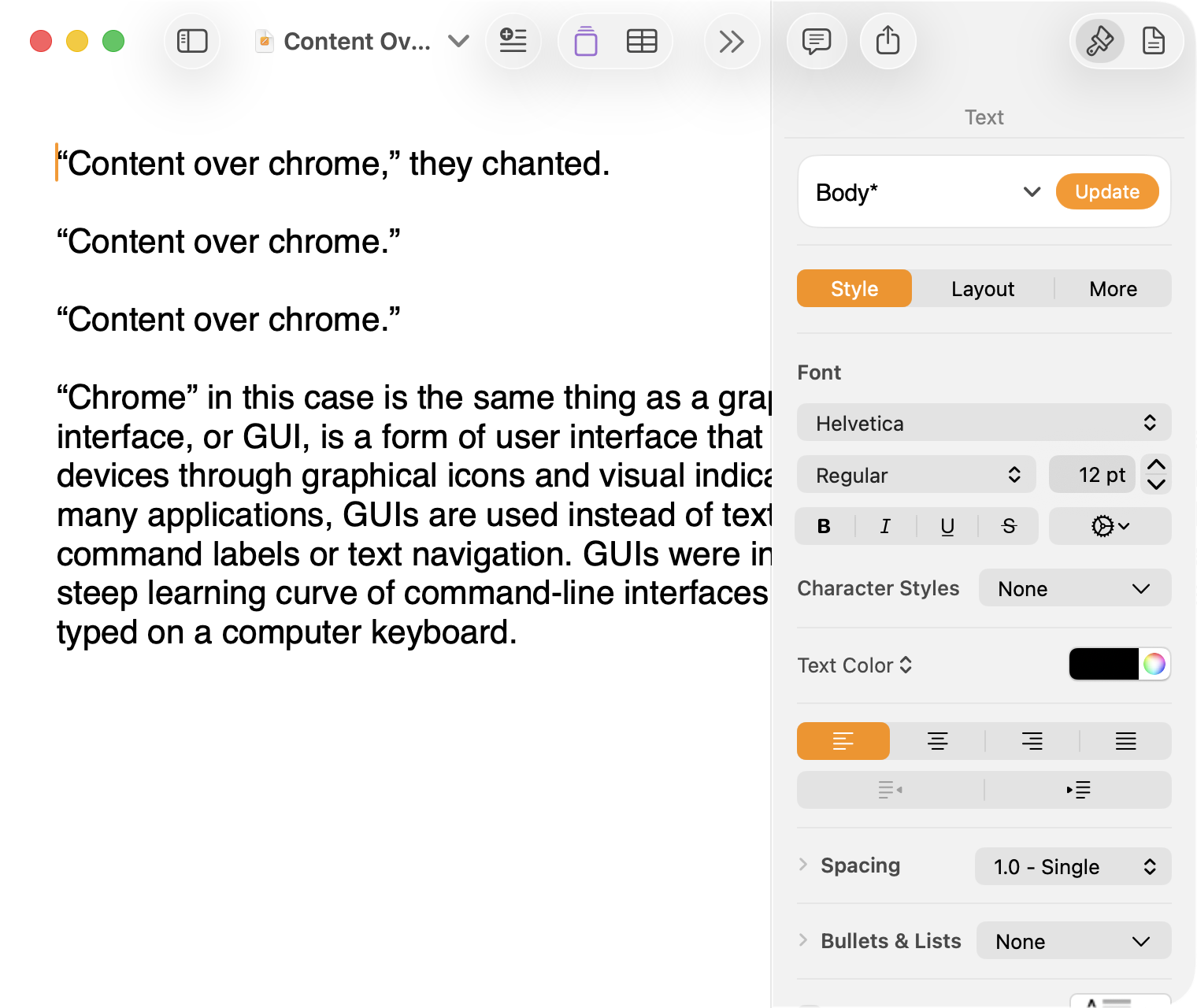


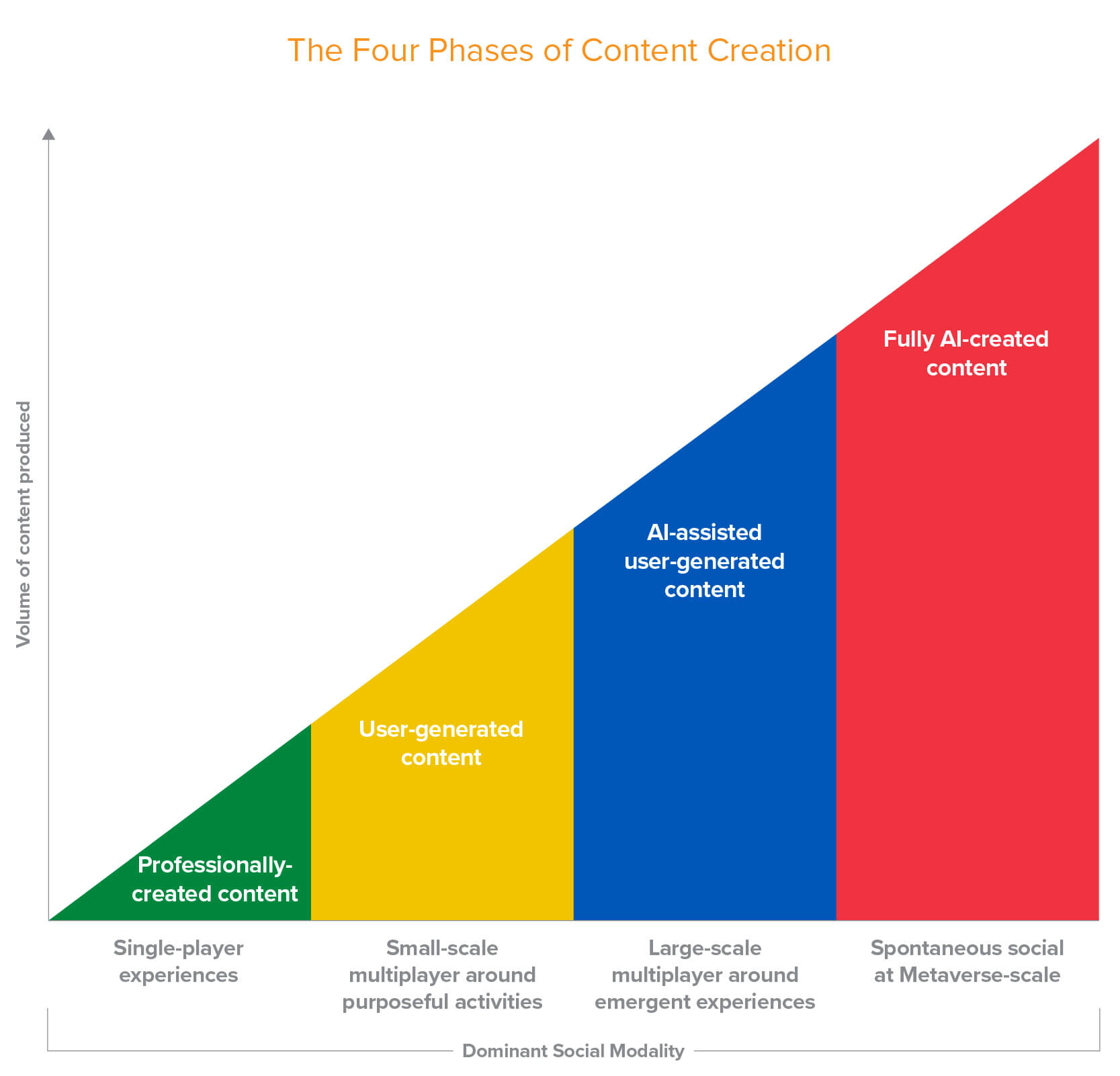{kind=link}
{kind=link}