Meta Platforms faces trial in Tennessee on Monday over the state’s claims that Instagram’s design is to blame for a youth mental-health crisis, one of several trials in the coming weeks testing allegations that the company’s social media platforms were intentionally built to be addictive.
I imagine Meta will spend considerable time trying to nail down a definition of “addiction”. The lawsuit makes no attempt to define the term, though it does quote several internal Meta communications acknowledging this as an outcome of the company’s products.1 In a legal sense, this might be an important question.
The term, however, seems loaded: is Instagram really comparable to cigarettes? As a matter of practicality and ethics, I have personally found it more useful to think of this in terms of whether Instagram and its competitors are intended to be hypnotic and compelling beyond users’ comfort levels. I believe they are. A social media app today looks more like gambling, where you wager your time, than it does a continuation of real-world social experiences.
It is therefore too bad this lawsuit and others like it are exclusively related to the effects they have on children. I understand why, but I think we all need greater control over what we see. There are people I know whose TikTok feeds are absolutely full of A.I.-generated nonsense, often a mix of not-harmful trash and malicious information. This will not be solved by simply telling people of all ages to just say no to using these apps.
The fixer — Ellis called him Ray and won’t reveal his name — met him in North London near Hampstead Heath for coffee and cakes. When it came time to discuss business, to avoid being overheard, they strolled into the park.
Ray had brought Ellis a few jobs before. But this job, he warned, was of an entirely different order. As Ellis claims in “The Art of Robbery,” a self-published memoir written after his release from prison, he eventually learned that Ray had been contacted by a consultant employed by “some influential bankers from America.” The bankers “were involved in prime mortgages” and had “circumnavigated” certain regulations. Damning evidence of these circumnavigations could be found in banking files held in the King’s Cross area in a giant building known as a data center.
This is a dramatic story, and one I think should be read with a heavy dose of skepticism. It seems that most of the criminal details have been shared by Ellis. For a start, the claim that some bankers ostensibly contracted with “Ray” is just a little too perfect for a recession-era tale. These bankers are pretty much universally loathed, and this justification makes this theft seem more palatable than a simple financial motive. For example, there was a similar data centre theft in October 2006, which would be unrelated to the lending crisis in the following years.
Another problem is that Rich says crimes like these are covered-up in part by a data centre operator because they are loathe to “admit to flaws in its security, [which] would only encourage additional attacks and scare away its clients”. Therefore, the lack of evidence for the specific circumstances of this crime is supposed to be a buttress for its likelihood, not a weakness, which is not reassuring.
The story of the theft was, as far as I can tell, broken by Here is the City, then a gossipy financial news site:
The data center itself is thought to be used by a number of companies, including JPMorgan, which is believed to have told staff that some of its systems could be off-line for parts of the day today as a result of the theft. Fortunately the thieves are thought to have got away with just the computer hardware, and not any sensitive information which may also have been stored at the facility.
Reports circulating on the Internet last week that JPMorgan, a customer of Verizon Business, had been affected by the burglary were incorrect, according to a source at the investment bank. There has been no loss of service or data, said the source.
On the one hand, of course all these parties tried to cover this up. The reading-between-the-lines story implied by these early reports and Rich’s telling is that some banking higher-ups, perhaps from JPMorgan, wanted to cover up some crimes, and denying any meaningful effect is just more cover-up. But little of this is substantiated by contemporary or current reporting — which is, of course, the whole problem with using a lack of evidence as the foundation for a story.
Rich, in the Times:
“The banks knew they were sending mortgages to people who couldn’t pay back,” he says today. “That’s what broke the whole system. That was the big con.” Ellis remains convinced that the bankers who paid for the Verizon job wanted to destroy evidence of their involvement in fraudulent subprime mortgages — the inside information that Ellis received about the data center, he believes, “would have had to come from the top” — but he can’t prove it. He never saw what was on the servers.
“Our job was to get the motherboards,” he says. “We were paid quite handsomely. Whatever happened after that was none of our concern.”
In contemporaneousreports, the Metropolitan Police noted the theft of motherboards and processors. But if these bankers wanted to cover up their fraudulent practices, surely the hard drives would have been the target, right? In Rich’s version, entire servers were taken, so perhaps this is just a misunderstanding.
This story smells fishy. I believe the theft happened, of course, and Ellis’ involvement, but I am not as convinced this had anything to do with covering up some white collar crime. (By the way, the Guardian in 2018 published an interview with Ellis about the interesting prison where he was transferred and which led to his rehabilitation.)
The heist element is only about half of Rich’s story; much of it is a discussion about data centre secrecy:
The public fogginess about data centers is not an accident. It is the product of a willful strategy by the world’s largest tech corporations, whose business models rest on the public assumption that the internet, and all the data it holds, is as immaterial as air — or as a cloud, to borrow the metaphor commonly used to describe the sum of information stored on servers. As the digital-media scholar Tung-Hui Hu writes in “A Prehistory of the Cloud,” the cloud “hides its physical location by design.”
[…]
It was a lot easier to defend data when people didn’t know it existed. The more people learn about data centers, the more they hate them. […]
If you read a website like this one, you were probably aware that data centres were commonplace twenty or more years ago. Like the one near King’s Cross, some were hidden in plain sight, while others were purpose-built facilities that look like hangars stuffed with servers. But the A.I. boom has meant rapid increases in the speed, scale, and quantity of data centres. People quickly learned not only of their existence, but how much pressure they put on local resources. Tech companies, it seemed, were caught by surprise; and as someone who spends a lot of time immersed in this world, so was I.
Much of the consternation I have seen in more general audiences has been about data centres in general. People simply were not aware that Amazon has warehouses full of products, and other warehouses full of computers. As Rich writes, this is deliberate, for business secrecy reasons, security, and environmental costs. But, also, I think some of that unawareness is because of just how boring it is. If nobody wants to know hidden information, is it really a secret? It only became one when the information these companies were hiding had real-life effects.
It does seem that public awareness is putting pressure on corporations to improve data centres and make them more efficient. But that is not a standard. New data centres are powered by petroleum with a pinky promise of renewable offsets. In some regressive regions, like Alberta, new power plants for data centres must be powered by methane gas. In a further complication, Meta’s proposed data centre is scheduled to be completed before the power plant is ready, meaning it will be dependent on existing grid power for perhaps years. Meta’s is just one of the data centres proposed for Alberta. Another one, a gigawatt cluster, would also require a dedicated gas-fired power plant, while Kevin O’Leary’s questionable project is supposed to require over three times the combined power of those other two.
For years, the tech industry told us we did not need to have much concern for how digital products and services worked, and many of us did not bother to find out. But it turns out the demands of our email and Netflix subscription were comparatively easy to hide. At the very least, what we ought to demand from projects with the scale and ambition of these data centres is open disclosure of their power consumption, water use, and emissions.
But we ought to demand more than the bare minimum. Transparency does as much good as a big banner reading we are destroying the planet but we are also creating a lot of value for shareholders. When a single data centre is projected to use about as much power as the entire city of Calgary is currently — Enmax says 1,260 megawatts as of writing — we should have a say in whether that makes sense. A.I. remains a thing that is happening to us rather than with or for us. It is built on assuming consent and asking forgiveness, which has more-or-less worked for the industry and gave it way too much confidence. Tech companies could have spent decades being better corporate citizens. Data centres are just one part, but they are representative of the difference between the stories told by tech companies and the things we can actually know.
Commons Quality Images (COM:QI) was created during June 2006. The purpose of COM:QI was to identify high quality photographs taken by Wikimedians and made freely available to the community at large through Commons. As of 14 June 2026 over 450,000 media files, mostly photographs, have been recognised through this process. Alongside photographs, QI has Microscopic images, animated GIF’s, and graphical works including our own QI seal (pictured).
Commons Quality Image seal
From the Beginning
In September 2005 Commons became live, just 6 months later I was encouraged over by User:Pfctdayelise who had been there from the first month. In June 2006 User:Pfctdayelise was searching to put together collections of images created by Commons users as rotating background images, or calendars to help promote the project. I tried to help, we could not even find a common subject matter consisting of reasonably sized and quality printable images. Wikimedia Commons had some great photos, some of which had been featured, but a substantial portion were images scraped from other sites like NASA and Flickr.
That started me thinking about how we raise the profile of community uploaded images and encourage efforts to improve them. Having already contributed to some Good Articles over on en.Wikipedia I thought we could create a similar project but for photographs.
Creating the project I saw some key necessities: it needed to be efficient with clear standards, while not taking weeks to decide the outcome. Most importantly it needed to focus only on images that had been taken by members of the Commons Community and that once recognised it could not be taken away. From there working with User:Wikimol and others we built the project. We also created image guidelines which would enable consistent reviewing of nominations.
Low resolution / thumbnail. Photographic QP has to have at least 1.92 megapixels (=1600×1200, for example)
JPEG problems. Too much compressed, too low JPEG quality settings in camera / when saving. Visible jpeg artifacts. => Use better quality settings (e.g. set JPEG “superfine”, shoot RAW, save in photoshop with max. quality)
Noise problems, too much noise. Be it chroma noise, luminance noise, visible grain, scratches in scans… QP should not have distracting amount of noise when viewed in 100%
Bad exposure. Overexposure, blown out highlights, underexposure, shadows details replaced by jpeg maps… In incorrectly exposed images, significant details in a significant part are lost.
Color problems. Bad white balance. Distracting (typically purple) hazing at 100%. Color aberration. QP must have reasonable colors (which does not necessarily mean natural colors).
Improper or undefined focus, insufficient depth of field. QP should have clearly defined focus, e.g. main subject in focus, foreground and background out of focus. Or the whole scene in focus. Counterexample – main subject blurry, foreground even more blurry, focus is somewhere between main subject and background. DOF could be low on purpose.
Blur. Images blurred just because of shaking hand or subject moving too fast. Motion blur in QP has to have purpose.
Poor lighting. Including: distracting reflections (usual problem with built-in flash), unintended vignetting, distracting harsh shadows. Generally bad lighting makes scenes with space look flat.
Overfiltered. There are so many PS/Gimp filters. Rarely a better image is created just by applying more and more filters…
Bad or nonexistent composition, unclear or nonexistent subject. QP should have subject and composition of the image should support depiction of that subject, not distract from it.
Bad perspective, tilt, and other distortions. An eye (or, more precisely, a brain) is a sensitive detector capable of spotting even a small tilt … falling trees, churches, inclined water surfaces,… Images of architecture should usually be rectilinear and without too much perspective distortion.
Stitched images, panoramas.
Panoramatic QP has to have a height of 800px min.
Stitching problems. Stitched images should be without artifacts, colors and lightness should be the same across the image.
All of these may look familiar to many of you as they are still present as Commons:Image guidelines, the very same guidelines that every WikiLoves or similar competition uses as their rules.
Now we had a process with guides, we approached User:LadyofHats who was known for the drawings she was uploading at that time. LOH was asked to create a seal which we could use to help identify successful photos, that seal is the one we continue to use. Some time during this the QI seal itself got recognised as a Quality Image.
In those early months every image was reviewed and the pages manually updated, a time consuming process that would occasionally be interspersed with edit conflicts. The community embraced QI and a new project called Valued Image emerged for recognising sets of image rather than individual images. It was the efforts of User:Dschwen, who had also taken on maintenance tasks, decided to create a bot that would do most of the work for us. Mike Peel continues to maintain the QICbot and has been invaluable at keeping it working, as of 16 June 2026 QICbot has performed 922,000 edits looking after QI tasks.
QI grew fast once the QICbot came on board. I stepped into the background watching the community grow QI. Over time many contributors have made QI. Like User:Poco a poco who presented at Wikimania in London on how QI helped him improve his contributions. For the curious there is an opt-in unaudited list of QI by photographers. Whether it’s one successful image or 20,000 of them they all make QI what it is.
The future
I think some of QI’s potential still hasn’t been realised. I saw it as a historical record of the growth of photography, of something researchers could look back over and see how it has matured. Perhaps more could be done to integrate QI images in content on other projects as they are recognised as our better works. Maybe a bot could triage nominations to identify the more regular issues that cause images to be rejected, though the human touch should always remain the final judge.
In the future, QICbot will reach 1 million edits, QI will reach 500,000 very soon. QI carries within itself a lot of untapped potential.
Could it be time to consider creating a sister project for Quality Videos? I know one thing: there will always be enough high quality images created by Wikimedians to make a calendar for any subject. The challenge will be in choosing just 12.
I would must take a moment to acknowledge everyone who has already helped Commons Quality Images along it’s 20 year journey there has been so many as well as everyone who joins the efforts in future. It’ll always be nice to reflect and be able to say I was able to open the door to something so special. The future of Quality Images is now a journey the Wikimedia Commons Community will decide.
QI’s prosperity comes from the collective effort of everyone! Perhaps this will encourage you to join the QI club.
A new pivot point for Apple? Seems like a good time for a new pivot for me, too. This year has been full of milestones for me, from appearing on “Jeopardy!” to reviewing David Pogue’s book about Apple for The Wall Street Journal, to crowdfunding a new podcast about Apple history. Along the way, I’ve had to say goodbye to some longstanding projects.
That’s my long way of saying that this is my last More Color column at Macworld. […]
Snell would likely not appreciate it if I mentioned how old I was when I first read his byline, so I will not, but I will point out that I continue to love what he is doing independently at Six Colors. My congratulations for an amazing run.
Over the last several years it has become readily apparent that there has been a shift in the editorial framing and focus of the New York Times when it regards issues relating to transgender people. This is particularly pronounced when it comes to issues of gender affirming care for transgender youth. The Times has contested this accusation of bias or editorial shifting of their priorities and framing, often by pointing to individual stories and claiming that the stories are rigorously fact checked and true. The issue is that any particular article can be argued about in isolation about whether or not the framing is biased against transgender people but when viewed in the aggregate the shift can become much more pronounced and difficult to defend.
To assess the framing of thousands of articles, Caraballo ran the text through three different large language models plus VADER. Caraballo notes the LLMs fared better at interpreting words in a greater context.
Setting aside the technology, it is alarming to see the Times’ coverage shift, and so noticeably in 2022. Caraballo attributes this to several predominantly internal factors, including losing the paper’s only openly trans writer, but I stumbled across another possible external influence.
[The Manhattan Institute’s] attacks on education also target K-12 schools. Starting in 2022, it began frequentlydemonizing schools for teaching “radical gender” ideology and “transitioning kids without parental consent.” Wuest says this is because disparaging public schools supports its longtime policy goals related to school choice. She cites a 2022 speech by [Christopher] Rufo at Hillsdale College.
The links in the quoted paragraph primarily go to the innocuous-seeming City Journal, though it is a publication of the Manhattan Institute. It ran loads of articles in 2022 from Rufo taking things out of context to, as Pisoni writes, advance the broader conservative policy goals of the Institute and stirring up a broader panic about trans people. And the Timeslovestaking directionfrom Rufo.
I have previously noted I am not a fan of Ed Zitron’s writing on A.I., which I think is driven more often by adherence to narrative than by genuine skepticism. Even so, his newsletter is extremely popular, and occasionally that pays off with honest-to-goodness scoops. Yesterday, he got a big one — a smattering of OpenAI financial documents revealing the company’s spending and earnings for the past two years. In 2024, it made billions of dollars less than it spent — including over a billion dollars on sales and marketing alone — and its 2025 numbers look even worse:
The financial condition of OpenAI is deeply concerning. $38.53 billion in losses are astronomical, and far higher than most believed it would be. Losses also appear to be mounting year-over-year at a dramatic rate, and I’m not sure how this company finds a way toward any kind of sustainability or profitability.
Zitron shared these documents with the Financial Times, which independently verified them, and added some much-needed context. In particular, that whopping $38.5 billion loss accrued in 2025 and highlighted by Zitron — including in his headline — seems far less dramatic:
Before OpenAI’s switch late last year to become a public benefit corporation, investors in the company received convertible interest rights rather than conventional equity. Under US accounting rules, those interests were treated as liabilities and periodically revalued as the company’s valuation increased.
As OpenAI’s worth rose, the increased value of those investor rights created a roughly $30bn charge, added the person. The charge is not expected to recur following the restructuring, they said.
That expense is not something that can be waved away, of course, but it does not seem to be materially related to the company’s actual costs of creating and selling its products. Losses without including that charge were, according to the Times’ “person familiar with the matter”, $8 billion, or roughly 60% more than in 2024. But that is against revenue of $13 billion in 2025, a significant increase over 2024’s $3.7 billion. (OpenAI, in the first three months of 2026, earned $5.7 billion.)
These juicy numbers were republished by outlets like Reuters, the Next Web, Stocktwits, Benzinga, and Startup Fortune. Shamefully, all attributed them solely to the Times without mentioning Zitron’s critical role. These publications — particularly Reuters — should be giving full credit to the original source.
That Zitron now has actual, verified numbers also allows us to check some of his own reporting. For example, in April, he was quite upset that “every outlet has continued to repeat that OpenAI ‘made $13 billion in 2025,’ despite that being very unlikely given that it would have required it to have made $8 billion in a single quarter”. It is unclear to me which outlets Zitron is referring to as I could find just one — Russia Today — using that quoted phrase verbatim.
Even so, Zitron goes on to write about some apparently conflicting numbers reported by Anthropic before concluding:
Though I cannot say for certain, both of these situations suggest that Anthropic and OpenAI are misleading their investors, the media and the general public. If I were a reporter who had written about Anthropic or OpenAI’s revenues previously, I would be concerned that I had published something that wasn’t true, and even if I was certain that I was correct, I would have to consider the existence of information that ran counter to my own. I would be concerned that Anthropic or OpenAI had lied to me, or that they were lying to someone else, and work diligently to try and find out what happened. I would, at the very least, publish that there was conflicting information.
Two days after this article, he again claimed that “every single story about OpenAI’s revenue other than my own reporting (which came directly from Azure) massively overinflates its sales”, which are more like “a mere $2.27 billion in the first half of last year”.
The numbers Zitron now has for OpenAI suggests this narrative is complete hogwash. Yes, these companies leak overly-optimistic annualized run rates, but if that was a factor in the audited financials Zitron obtained, he likely would have mentioned that. He does not — and neither does the Times, for that matter. “Due to the seriousness of this story”, Zitron wrote, “I am not going to do very much editorializing”, so we will see in a later issue of this newsletter whether he acknowledges this self-induced frenzy was all in his head.
This is why I read Zitron’s work in the framework of conspiracy thinking. He accused OpenAI of “massively overinflat[ing] its sales” and “misleading their investors” based on his own calculations using leaked Azure figures. But it turns out OpenAI did, apparently, have that $13 billion in real non-ARR-fudged revenue for last year, and its operating loss is shrinking. Real analysts, not me, can figure out whether this company is on a path to a functional business. Zitron conjured a whole fictional narrative out of misreading some numbers and then, it would seem with this latest update, misunderstanding them again because it is useful for the story. Still, he should be credited for this scoop.
The media focused on the higher age limit — it’s been happening in other parts of the world and is easier for people not well-versed in tech policy to understand, including many journalists — but it was not really the centerpiece of the legislation. If anything, the age limit serves as a stick to get companies to comply with a broader set of design standards meant to make their platforms safer for younger users. Unlike in the Australian legislation, if platforms make those changes, they can win an exemption from the age limit.
I also appreciated the implied nuance in the legislation; however, critically, those design standards have yet to be defined. Perhaps users will be granted actual control over what they see in their feeds; perhaps there will be legally defined promises for what notifications users may opt into or out of. These would be welcome improvements. But we simply do not know what they are yet.
Worse, by tying all-user policies on the one hand to an age gate on the other, I worry the outcome will be a compromise satisfying neither. Someone is currently supposed to be 13 or older to have an account with a social media service, both under Canadian law and in platforms’ terms of service agreements. Raising the floor to 16 is not the biggest issue one way or another. The real carrot is, therefore, weighing whether social media companies are willing to stop mandating their slot machine for feelings on every Canadian user in exchange for not having to verify their ages. Given the number of places already enforcing some age-gating and the development of infrastructure associated with that, I think many social media platforms will find it far easier to start carding people rather than changing their ways.
I do not think an imperfect law is inherently bad, however. Like Marx, I am encouraged to see a worldwide discussion among policymakers of how to rein in these specific kinds of businesses that have marketed directly to children despite their many design flaws for which these companies accept no responsibility. I am only skeptical these companies will do the right thing when they always prefer the cheaper and less accountable option.
Bill C-34, the Safe Social Media Act, would force social media services — defined as traditional social media platforms, live-streaming services and adult content services focused on user-shared content — to restrict accounts for children under 16 years old.
However, services could seek an exemption if they implement what officials briefing reporters called adequate safeguards to protect children. The exemption wouldn’t apply to platforms offering adult content services.
The “adequate safeguards” are not yet defined and, it turns out, are far from the only things to be determined. It was striking to read the text of the bill and come across so many key pieces punted to a later date or committee. Some of these policies, for example, might only apply to services over some number of users, but that cut-off is to be established later. There is a whole committee, the Digital Safety Commission, with “three to five full-time members” but few specific details. Even things which appear to be strictly defined — removing CSAM within twenty-four hours of being flagged by a user — might be different “if a period of a different length is provided for by regulations”.
Bill C-34 suggests the government absorbed only part of the lesson. The Criminal Code and Human Rights Act provisions are gone, but in their place the government has thrown in everything else: the original Online Harms Act platform duties, an under-16 social media ban backed by mandated age verification, Bill S-209’s pornography age verification requirements, a new AI chatbot regulatory regime, and sweeping powers for a Digital Safety Commission that will write the rules, enforce them, and decide which platforms escape the ban restriction. It is an everything-all-at-once approach in which nearly every key component, including which services face the restriction, how age gets verified, which AI systems are covered, and what standards govern exemptions, is left to regulations that do not yet exist.
The internet has plenty of problems that deserve attention. Predators exist. Addiction is real. Platforms optimize for engagement over well-being. None of those facts requires the rest of us to accept a system of digital ID that will follow every user who wants to comment on the news or express their position on whatever.
There is the tiniest, faintest shred of hope in that some platforms implementing “adequate safeguards” will not actually need to verify ages at all. I am not banking on that, to be clear, but it is at least a notion of something that could be promising. Then again, we have no idea about what that means or, in fact, any material policies in this bill. All we have is this framework, and it sucks.
For close to two years, my involvement in the Wikimedia ecosystem was mostly technical. I contributed through code during hackathons as a member of Wiki Mentor Africa. I understood the connections among platforms such as Wikipedia, Wikidata, and Wikimedia Commons. I knew their importance, but I also felt there was more I could do. Something was missing in how I was contributing.
I came into the program with one clear goal: to gain a deeper, practical understanding of how to contribute beyond the technical side of Wikimedia. I wanted to move from simply supporting the ecosystem to actively building knowledge within it.
The training opened my eyes to the structure and responsibility behind Wikimedia contributions. I learned that every Wikimedia project is guided by strong principles that protect the quality and reliability of information.
On Wikipedia, content must be notable, verifiable, and supported by reliable sources. On Wikidata, data must be structured, accurate, and referenced. On Wikimedia Commons, files must follow copyright and licensing policies.
These are not just guidelines; they are what make Wikimedia a trusted global knowledge resource.
Learning Through Practice
One of the strongest aspects of the mentorship program was its practical training. The program did not simply explain policies and standards; it required us to apply them through real contributions.
I learned how to properly reference articles, structure content, improve neutrality, and contribute according to Wikimedia standards. At first, this process was challenging. Finding reliable sources, understanding notability requirements, and writing neutrally required patience and attention to detail.
However, through continuous practice and guidance from the trainers, these concepts gradually became clearer and easier to apply.
The trainers also played a major role in making the experience impactful. Complex policies and technical concepts were broken down into simple, understandable steps, making the learning process accessible and encouraging.
Milestones That Changed My Confidence
One major milestone for me during the program was creating two articles and receiving a barnstar in recognition of my contributions.
That moment shifted my confidence completely.
For the first time, I felt that I was no longer just observing how open knowledge is built behind the scenes. I was actively contributing to the preservation and sharing of knowledge myself.
The experience helped me see Wikimedia differently. It became more than a technical ecosystem I contributed to during hackathons. It became a collaborative space where I could directly improve content, document knowledge, and support representation online.
Growing Beyond the Program
Beyond technical editing skills, the mentorship program also changed my perspective on community contribution and leadership.
Looking ahead, I plan to share what I have learned with my community and support the onboarding of new contributors. I am also stepping into a new role as a trainer for an April editathon, which reflects how much this experience has shaped my growth within the Wikimedia movement.
This journey has been both challenging and rewarding. It pushed me to learn, adapt, and contribute more meaningfully.
Wikimedia is more than a platform. It is a collective effort to make knowledge accessible to everyone.
His [Bill Gates’] carefully crafted image has been shattered as more details of Gates’s association with the late Jeffrey Epstein have spilled into public view, challenging prior efforts by the 70-year-old to downplay his relationship with the sex offender. In a February town hall with foundation employees, Gates owned up to two affairs with Russian women referenced in Epstein’s emails.
[…]
Two different polling teams — at the Gates Foundation, and his private office, Gates Ventures — for years have closely tracked opinions about Gates, including on favorability, trustworthiness and inspiration. A media analysis prepared for the Gates Foundation found that there had been a more than 40% increase in “critical news narratives” about Gates and the foundation since the Epstein files were released through February, according to internal documents reviewed by The Wall Street Journal.
There are so many little details in this story that are worth your time, but my big takeaway — aside from the Epstein stuff — is the neurotic obsession with building image that, I imagine, is fairly common among public figures. I know this, of course; you probably do, too. But to see it spelled out in the way Glazer does is quite something.
Gates pays people to obsess over his public perception for him — to choose his clothes, to work with Netflix on documentary-style vehicles for him, and to massage his blog and social media accounts. There is something truly bizarre about having a team edit together a video of a rich businessman going for pizza in an attempt to make him relatable and likeable, and then — presumably — tracking the performance of that Instagram post.
Gates and his foundation have done undeniable good in the world, while also being a figurehead of the mixed results of billionaire philanthropy. Also, he spent a lot of time around Epstein. It remains a mystery to me why billionaires like him also want to become beloved celebrity intellectual figures.
Remember, the plan was $26.4 billion [in Twitter/X revenue] by 2028. We’re more than halfway there. How’s it going? Well… when he combines xAI (grok) revenue with X revenue (so not even just breaking out X’s ad revenue)… we get… a total of $3.201 billion in 2025. So, just to put this in perspective… when he took over in 2022 he laid out a five year plan to take the company that had $4.5 billion in ad revenue the year before he bought it up to $12 billion in five years. Three years in and… it’s now somewhere pretty far below $3 billion. […]
Earlier this year, a judge found against Elon Musk in a lawsuit filed by X against advertisers claiming they staged an illegal boycott.
The SpaceX prospectus, by the way, is one of the funniest documents to ever live on the sec.gov domain. It is lucky the business it is known for is so damn photogenic because it is, at present, a profitable satellite internet provider with side businesses of space exploration and artificial intelligence that each lose money. (How it internally accounts for the cost of sending Starlink satellites into orbit is a fantastic question.) And the present business model of the latter is something Patrick Boyle described as “renting GPUs to a competitor on terms that can vanish in a fiscal quarter”. Yet the company still claims the size of its total addressable market is over $28 trillion, or over one-fifth of the entire world’s GDP.
Even so, a $1.75–2 trillion valuation is plausible simply because of Musk. Similarly, and back to that AFP article:
According to its filing, TMTG generated US$900,000 in revenue during the first quarter, a paltry amount for a company valued at US$2.47 billion on the stock market.
That valuation is not much; at time of writing, it is worth about as much as Central Garden & Pet, owners of Nylabone and McKenzie plant seeds. That company last quarter posted revenues one thousand times greater than TMTG, with profit margins of over 12%. Nevertheless, TMTG has a connection to the U.S. president, so it is similarly valued. Lots of good, normal stuff happening in the world’s largest and most powerful economy.
You probably know the gist. Predictions and dire warnings of a future lived in an immersive virtual world had been around for decades before Neal Stephenson solidified the concept in his 1992 novel “Snow Crash”, but Stephenson called it the “metaverse”, and that was important. It was a cautionary tale. Not everyone understood that. The video game Second Life, launched in 2003, provided an early glimpse of the concept in a P.C. environment. Another piece of the puzzle, consumer-grade virtual reality, began to take shape when Oculus was founded in 2012, and shipped a developer-centric version of its virtual reality headset in 2013. The company was acquired by Facebook a year later. Oculus released a few more headsets while Facebook figured out what to do to “truly transform the way we live, work and connect with each other”.
Despite this goal, “metaverse” was not yet part of Facebook’s lingo, though it was in Oculus’vocabulary. A 2015 internal memo from Mark Zuckerberg does not once contain the word despite describing the strategy it was developing. Even “Oculus” was barely mentioned in the company’s quarterly earnings calls around this time. But in the Q1 2018 call (PDF), Zuckerberg laid out a “10-year journey” for why Facebook bought Oculus, saying “every 10 to 15 years or so, there’s a major new computing paradigm”, and it is “very likely that the next one is going to be around virtual and augmented reality”. “One of my great regrets in how we’ve run the company so far is I feel like we didn’t get to shape the way that mobile platforms developed,” Zuckerberg said, explaining that it was important to spend vast sums of money now “in order to build some of the muscles to be competitive” later. Facebook was training for a major battle that would never materialize.
In the weeks after Meta announced it was retreating from its metaverse efforts earlier this year, I revisited this and other earnings calls, plus presentations and other documentation, as I tried to better understand what the metaverse was pitched as compared to what it ultimately became. I wanted to know how something so silly was treated by executive and media figures alike as a sincere directional shift for one of the world’s biggest companies in particular. In hindsight, it feels like a particularly narrow period of hype coinciding with — and, I think, benefitting from — the most urgent years of the COVID-19 pandemic. As enthusiasm deflated, it was almost unnoticeable despite forecasters labelling it an essential next step of the internet — a necessary next frontier.
The obsession with the metaverse seems to have solidified in Silicon Valley after Matthew Ball published an essay in January 2020 in which he forecasted that, at the very least…
…it is likely to produce trillions in value as a new computing platform or content medium. But in its full vision, the Metaverse becomes the gateway to most digital experiences, a key component of all physical ones, and the next great labor platform.
Ball admits “we don’t really know how to describe the Metaverse”, but sets seven criteria that, in general, portray it as an expansion and continuation of our blended physical and digital worlds, without the constraints of a physical space and with its own economy. Most notably, he says it will offer “unprecedented interoperability” between platforms and providers. He also lists eight things it is not, among them: it is not just a virtual world, or virtual reality, or a digital economy, or a new app store, or a new platform. It is more about a set of protocols and ideas that, yes, incorporate all these elements, but the metaverse is not itself these qualities.
Ball published this essay with darkly fortuitous timing. A week earlier, Chinese health authorities had isolated a new strain of coronavirus aggressively spreading in Wuhan; a day before, they published its genetic sequence. Within a couple of months, the world had turned upside down and many of us were suddenly spending our days in a space that felt more virtual than physical. We may have only been working from home — or, at least, those of us who had the option and were not laid off — and socializing over Zoom, all while remembering the last concert we went to or the last time we ate a meal in a restaurant.
In July 2020, Forbes contributor and futurist Cathy Hackl imagined a world — one that was “for certain, it’s coming and it’s a big deal” — that connects augmented reality, neural interfaces, and a whole bunch of assumptions. In this environment, you could merely remember that you need to buy something, and then a virtual vending machine would materialize so you could order that thing. Hackl defines the metaverse as “a future iteration of the internet, made up of persistent, shared, 3D virtual spaces linked into a perceived virtual universe”.
In “The Future is a Dead Mall”, a video essay using Decentraland as a jumping-off point for a discussion of the metaverse, Dan Olson navigates several writers’ conflicting definitions before making the reasonable conclusion it is basically irrelevant:
If you comb through dozens and dozens of definitions of the metaverse you can assemble a web of broad attributes where some are generally agreed upon, while others border on being mutually exclusive. It’s a vague, largely incoherent cloud of ideas that’s malleable enough that basically anything can be called part of the metaverse, a proto-metaverse, or a semi-metaverse.
[…]
When you understand that the metaverse isn’t a distinct invention or construct, but merely a rhetorical proxy for The Future of Technology, then all of this becomes a lot easier to deal with.
I think Olson is largely correct; this is how the term is actually used. But, though not his intent, I think defining “metaverse” in vague terms is favourable to its boosters because it does not hold them to something specific. I think the explanation offered by Mark Zuckerberg in Facebook’s Q2 2021 earnings call (PDF) is actually pretty fair. This was two quarters before the company changed its name, and between prepared remarks and the question period, there were twenty total mentions of “metaverse” on this call.
So what is the metaverse? It’s a virtual environment where you can be present with people in digital spaces. You can kind of think about this as an embodied internet that you’re inside of rather than just looking at. We believe that this is going to be the successor to the mobile internet.
You’re going to be able to access the metaverse from all different devices in different levels of fidelity — from apps on phones and PCs to immersive virtual and augmented reality devices. Within the metaverse, you’re going to be able to hang out, play games with friends, work, create, and more. You’re basically going to be able to do everything that you can on the internet today as well as some things that don’t make sense on the internet today, like dancing.
So, in some ways, exactly like Olson’s definition: “different devices in different levels of fidelity” that let you socialize and do work, just like everything you currently do on the internet — plus dancing. It seems almost halfway toward being normalized in his head, though it feels as alien to read this today as it surely did then. Yet Zuckerberg is getting at something here. Virtual and augmented reality are ways of immersing us in unique environments that radically change how we interact with technology. And on the next quarter’s earnings call (PDF), Zuckerberg expanded:
[…] If you’re in the metaverse every day, then you’ll need digital clothes, digital tools, and different experiences. Our goal is to help the metaverse reach a billion people and hundreds of billions of dollars of digital commerce this decade. Strategically, helping to shape the next platform should also reduce our dependence on delivering our services through
competitors.
Your avatar cannot simply be a picture of you. You will “need digital clothes” for this space. Need.
In addition to building hype among investors during these earnings calls, Facebook was pumping up its metaverse efforts in more general audience settings. In May 2021, CNetpublished a transcript of a thirty-minute Zoom call between Zuckerberg and Scott Stein where the former could wax lyrical about the bonafides of where Meta was at the time — “with the fidelity of experiences that are possible today, to me that just says, wow, in five years this is going to be clearly better on almost all of these fronts for a lot of the things that we do”. Casey Newton, of the Verge, was given by Facebook a copy of an internal meeting in which Zuckerberg told employees the company’s “overarching goal across all of these initiatives is to help bring the metaverse to life”. The two then recorded a soft and cuddly episode of the Vergecast that allows Zuckerberg to play visionary and rattle off the company’s metaverse talking points. “I think over the next five years or so, in this next chapter of our company,” Zuckerberg told Newton, “I think we will effectively transition from people seeing us as primarily being a social media company to being a metaverse company.” By October, Sarah E. Needleman was relaying to readers of the Wall Street Journal the words of Unity Software’s Marc Whitten the imperative for businesses to develop a “metaverse strategy”. “The metaverse is going to be the biggest revolution in computing platforms the world has seen,” said Whitten, “bigger than the mobile revolution, bigger than the web revolution”.
It is not difficult to see the deliberate strategy here. In 2019 and 2020, Facebook was not talking about the metaverse and, though a few commentators connected the just-announced Horizon social world to the concept, it was not treated yet as the inevitable future. As 2021 rolled on, Facebook’s promotional drumbeat grew stronger. Suddenly people were talking about the metaverse, and connecting it all back to Facebook. There was, it would appear, real buzz — enough, at least, for the Journal to find corroborating voices and take it seriously.
Three days after its Q3 2021 earnings call, Facebook held its Connect conference, which is centred around its augmented and virtual reality efforts. This was a big moment. This would be the keynote where the company laid out its metaverse-centric vision, and changed its name to Meta to reflect this new focus, and because it had to. “From now on,” Zuckerberg said, “we’re going to be metaverse-first, not Facebook-first”.
Rewatching this presentation in 2026 is a bizarre experience, not least of which because of how it is shot. Most scenes appear to be green screened with composited animations. Demos are virtually nonexistent, with most representations of the metaverse carrying a disclaimer that they are “not actual product images” and they are “strictly for illustrative purposes only”. Even so, Zuckerberg and other executives at Meta are all-in on hyping up an experience that, at best, only barely resembles what it ended up shipping. In many cases, it is not even close.
There is a Jon Batiste concert visualized as something that could be attended in-person by someone in Los Angeles and in the metaverse by someone in Kyoto, presumably through the glasses each person is wearing. We do not see the performance from their perspective, but the implication is that the virtual viewer would see it from the same or similar perspective to the in-person attendee. Both get invited to a virtual after-party where they can buy NFT-based digital merch and meet Batiste or, at the very least, his avatar. The reality of metaverse concerts is quite different than this concept. In 2024, Meta showed a Sabrina Carpenter performance in Horizon Worlds. The seats were great, but even in this immersive environment, it appears more like a concert film than a unbroken show viewed from a single perspective. Also, I cannot find any record of an after-party or virtual merch.
Zuckerberg touts Horizon Worlds as the place users will go to socialize, and Horizon Workrooms as the virtual environment for their job. The latter has since been completely shut down, while the former was put on ice. In gaming, Zuckerberg was particularly excited about Rockstar’s port of “Grand Theft Auto: San Andreas” which, three years later, Rockstar cancelled before it had been released. He said “remote work is here to stay for a lot of people” in this keynote, less than two years before ordering in-office work three days per week; two years after that, Instagram demanded five days per week in-office. I guess “a lot of people” does not include the people who are building the products that let a lot of other people work remotely. That is a little weird.
The wishcast-a-thon of Connect 2021 was treated by some with an entirely unearned gravitas. Dean Takahashi, of VentureBeat, called it a “historic moment” and compared it to the Manhattan Project. He thought Meta could bring about universal basic income, with Zuckerberg “paying us to use his devices so that we can make a living in his ecosystem”. In a mostly skeptical article in the New York Times, Kevin Roose raised the possibility that Meta’s focus change “could help with the company’s demographic crisis”, and advocated taking it seriously because the company “has found what may be an escape hatch” from “Facebook’s messy, troubled present”.
To mark the occasion, Zuckerberg granted interviews to four publications, all embargoed until after the Connect 2021 video was published. Dylan Byers, for Puck, was left with the understanding that Zuckerberg “doesn’t really care” about press coverage or questions about the legitimacy of this pivot — in a good way. “[I]t’s just that he’s not so bothered by the unrelenting criticism, and near-term and collateral damage,” wrote Byers, “that he’s going to check his ambitions or think twice about whether or not he’s the right person to help usher in the next phase of the internet”. Alex Heath, of the Verge, implicitly acknowledges the role Facebook’s public relations team played in creating the impression of interest in the metaverse, writing “it wasn’t thrust into the mainstream conversation until Zuckerberg started talking about it publicly earlier this year”. Heath did not break any news of note; neither did Matthew Olson, of the Information. The latter did at least contradict Zuckerberg’s protest of the “relatively high fees”, “a nod to the 30% commission” of Apple’s App Store and Google’s Play Store, by stating that while “Zuckerberg didn’t indicate what commission Facebook would charge”, “Oculus’ Quest
Store currently takes 30%”.
The following day, Matthew Ball spoke with Zuckerberg in a live audio session that has since been pulled from Zuckerberg’s Facebook page, though clips remain available on YouTube. A transcript of the conversation reads like a context-free time capsule of that era, with praise for meme stocks, NFTs, and Web3 in concept more than in practice — and, of course, Ball’s writing on the metaverse. (Six months after this interview, the NFT market would well and truly collapse, with peak transactions occurring the month before Ball and Zuckerberg spoke.) Ball raises the subject of the company’s $10 billion annual spending on Reality Labs. Zuckerberg believes “the metaverse can reach a billion people, say, in the next decade, and that there can be supported hundreds of billions of dollars of commerce. And that if that’s the case, then even with relatively modest fees on the transactions that happen in our services, we think that could be a big business”. But Zuckerberg says he does not want to lose too much money, which is being treated as a “somewhat moderating force over the next period that will keep us from being able to make all of the fees maybe as low as we would want to”. The strategy is, to be clear, entirely dependent on a massive groundswell of public interest in a fundamentally new understanding of computing.
(Zuckerberg also takes time in this conversation to note his respect for intellectual property, at least for luxury brands: if “someone can just make a knock-off Gucci sweater, then I don’t think Gucci’s going to feel that good about being in that space, right, or participating in that system”. Just a few years later, Zuckerberg would allegedly approve the use of pirated ebooks for training the company’s artificial intelligence systems. The work of authors, it would seem, is not as concerning as the reaction of luxury brands.)
A few days later, Zuckerberg again eschewed traditional media outlets and sat down for an interview with Sara Dietschy; then, he chose a softer approach in spirit, if not in volume or cadence with professional talking guy Gary Vaynerchuk. Earlier that year, Vaynerchuk had launched his own NFT collection and, not long before speaking with Zuckerberg, had sold five of his paper doodles for $1.2 million at a completely real Christie’s auction, so you could say they are both on the same wavelength:
Vaynerchuk: The extremity of the NFT space is going to be even greater for what that means. It’s almost like our
world is all about to become the fashion industry because we communicate so much through what we wear. The digital version of that is going to have an incredible impact on society.
Zuckerberg: Oh, totally.
Totally. Just like the fashion industry.
In 2022, Meta added support for NFTs in Facebook and Instagram, a project which it discontinued less than a year later. Digital collectibles got a shoutout in the Connect 2021 presentation, had a brief moment in the sun, and were quickly forgotten about. These things are supposed to be building blocks of the metaverse and Meta barely tried.
Meta’s annual commitment that Ball referenced, of $10 billion, represents all Reality Labs spending, including game development, some A.I. investments, and its EssilorLuxottica collaboration. Even so, despite a complete change in corporate priorities explicitly in the direction of the metaverse, Meta’s long-term interest did not match its investment. Here is a chart I made of mentions of “metaverse” in the transcripts of quarterly earnings calls from Q1 2021 — the quarter before its public relations push — through Q1 2026:
Mentions of “metaverse” in Facebook/Meta quarterly earnings calls. Source: company transcripts.
The highest point on that chart is the Q2 2021 earnings call I used earlier for the definition of “metaverse”; the second-highest is Q4 2021, the first earnings call after Connect 2021. The total count includes mentions in Meta’s prepared remarks, plus the question-and-answer period that follows. Investor conference calls are not a perfect proxy for a company’s priorities, but they are indicative. At the very least, for a company that entirely changed course with a new goal — “from now on, we’re going to be metaverse-first” — and a directly relevant name, one might imagine the company and analysts will be similarly eager to discuss how that is going. But no. In Q4 2022, mentions are half that of the year prior. By Q1 2024, neither Meta nor the analysts on the call seem to care all that much — while there were just four mentions of “metaverse”, there were ninety of “A.I.”.
This speaks volumes. It is the kind of thing that makes you wonder if this company was ever serious about this metaverse pivot at all. It seems like it had every intention, sure, but could it ever have executed on its vision? Of the four interviewers chosen for pieces related to Connect 2021, only Ben Thompson even thought to question its feasibility. (Thompson was also the only one to say he was permitted to view a copy of the presentation in advance. I do not know if this means the other three interviewers did not see it and, therefore, could not interrogate it more thoroughly, or if they did see it and simply did not bother to ask.) At the time, Facebook had no track record in building an operating system, barely had any credibility in hardware, and it only kind of created a platform on its “blue site”. (It arguably avoided creating platforms for developers with Instagram and WhatsApp.) This same company was claiming it was launching the successor to the smartphone and the next iteration of the internet. Every one of these chosen interviewers should have been all over this, but they were too distracted by the rebrand and Facebook’s sordid history to notice it was only a concept video more than it was any kind of real concept.
2. The Others
While Meta made itself the face and name of the metaverse, it was far from alone in promising the immersive computing platform of the near-future. Time basically acknowledged this by declaring one of the best inventions of 2021 was the Qualcomm Snapdragon XR2 — a foundational headset chip, rather than Meta’s attempt to build the platform.
In April 2020, Washington Post reporter Gene Park proclaimed the “next version of the Internet is often described as the Metaverse”, going on to confidently explain how it would be built. Of all the companies involved, Park wrote, “it’s Epic Games, with Fortnite, that has the most viable path forward in terms of creating the metaverse”, citing Ball’s seminal metaverse essay.
In April 2021, months before Facebook began asserting its commitment, Epic Games announced it had raised a billion dollars to “support [its] long-term vision for the metaverse” with $200 million of that coming from Sony. A year later, Epic raised another $2 billion, a billion of which again came from Sony, and the other billion from Lego. In 2023, a Lego game was added to Fortnite, which is not really the metaverse as much as it is a nifty Minecraft-like game-within-a-game.
Yet in Epic Games’ telling, it is basically delivering the metaverse already. CEO Tim Sweeney spoke at the 2023 Game Developers Conference about the company’s vision. Since there are around 600 million monthly active users of games, like Fortnite and Minecraft, set in virtual worlds, Sweeney reckoned “we can set aside the crazy hype cycle around NFTs and VR goggles. Yes, these technologies may play a role in the future, but they are not required. This revolution is happening right now.” Sweeney spoke of interconnectedness and open standards that would allow users to move between different spaces in a unified way. “What a user would really like is to be able to buy a cool-looking outfit in one place and take it everywhere they go” Sweeney claimed. (Why do they always mention digital clothes? My theory is because they do not view fashion as having much value beyond a basic assessment that how someone dresses is an expression of identity.) Sweeney describes Fortnite, Unreal Engine, and the Epic Games Store as “on-ramps to the metaverse”, and that the users of which already understand their in-game socialization can be extended to “going to a concert and dancing” in a virtual environment. Leaving aside the contradiction with definitions of the metaverse that mandate a more immersive environment, it is a big leap to think a brief animation of Eminem scratches the same itch as an actual performance.
Microsoft, as ever ahead of a trend without fully conceptualizing it, said it was doing metaverse stuff before Facebook started referencing it in public. Satya Nadella, defining the metaverse as “made up of digital twins, simulated environments, and mixed reality”, claimed a mix of Azure features, HoloLens, and Mesh would allow enterprises to get aboard. Last year, Microsoft said it was getting out of V.R. hardware and turning its mixed reality collaboration product into a glorified Snapchat filter in Teams.
Then there is Roblox. When Andreessen Horowitz announced its investment in the company, Marc Andreessen and David George wrote that “[w]hile pundits have been distracted by the readiness debates and questions over V.R. vs. A.R., the foundations of a global metaverse have been quietly built in the background… in Roblox”. This was in February 2020 — before Epic Games, before Microsoft, and well before Meta said anything in public about the metaverse. In January 2021, as part of Wired’s predictions for the coming year, Roblox CEO David Baszucki confidently predicted “the metaverse will experience widespread use, and start to become a human co-experience utility”. In March, the company went public at a $30 billion valuation. After Facebook changed its name to Meta, Baszucki saw that as validation of its strategy. That November, he made the rounds on business television networks like Bloomberg and CNBC to advocate for the company as a trailblazer.
In January 2022, Bernhard Warner of Fortune was getting excited about the possibilities of the metaverse, writing it “might be the most important trend in tech since the iPhone”, perhaps “a tectonic shift in tech that they [big tech and big investors] can’t afford to miss”. The way Roblox was “monetizing the metaverse” was a key piece of evidence, with virtual concerts and — most importantly — brands. “A parade of consumer brands […] have set up a presence on Roblox in the past year”, wrote Warner, citing Nike’s approach as being particularly exciting. A month earlier, it had acquired a company called RTFKT, which its press release extolled was a “leading brand that leverages cutting edge innovation to deliver next generation collectibles”. Guggenheim Securities, a subsidiary of Guggenheim Partners which has over $350 billion in assets under management, said it was the “‘best idea’ of 2022”, according to Warner. People are going to need virtual outfits, right? Yet, just three years later, Nike shut down RTFKT.
Gucci, another of the brands with a virtual presence in Roblox, sold virtual handbags for in-game currency for a limited time in 2021 and 2022; users realized they could effectively counterfeit and resell them. At least one of Zuckerberg’s predictions kind of came true. And, while Warner highlighted Disney as another company with in-game presence, it has not maintained a meaningful investment because, according to Variety, it feels Roblox is unsafe for children, a sentiment that was not helped when Baszucki appeared on the “Hard Fork” podcast. Roblox has settled lawsuits with the attorneys general of Nevada, Alabama, and West Virginia over accusations its platform features enabled child exploitation by other users. Roblox has denied any wrongdoing though it says it is enabling better parental controls and tighter restrictions on children’s accounts.
Through 2021 and 2022, the metaverse hype cycle was apparent across the tech industry. Max A. Cheney, reporting for Barron’s in August 2021, noted “[m]entions of the metaverse in earnings transcripts and other corporate documents are up five times this year compared with 2020, according to data from Sentieo”. This relative figure must have a hilariously low baseline, sure, but it is an indicator of how many businesses became briefly enchanted by this concept. There were serious financial analyses of real estate in the metaverse. Keep in mind that what is meant by “real estate” is much, much, much closer to domain names than it is land and deed. In July 2022, Technavio, a market research company, forecasted this market would be worth $5.37 billion by 2026. This report was picked up by Debra Kamin, of the New York Times, who published an article in the paper’s real estate section in February 2023 explaining this “new frontier for real estate builders and investors”. The primary anecdote in Kamin’s story is a just-completed mansion in Florida with a “twin” in a metaverse platform called the Sandbox. “As these technologies get more immersive”, the homebuilder said, “it’s going to make a lot more sense” to have a 3D virtual model of a house. Kamin was not breaking news on this specific story, as it was first reported by Emma Reynolds, of Forbes, over a year earlier. One would think that Kamin could therefore have asked some more probing questions or surveyed the actual market for NFTs which, by 2023, had fallen off a cliff. But no. Instead, the builder got the imprimatur of the Times describing the combined physical and digital sale in flattering terms. Ultimately, neither the listing nor many of the sale notices mentioned the sole marketing quirk of this house, suggesting that by 2023 the novelty of a digital model of a mansion was kind of over. I was curious if the NFT was a factor in the buyer’s decision, but did not receive a response to requests for comment I sent to a phone number associated with the current owner of the property.
Both the Times and Forbes articles are individual disasters in their own right. Sure, we might not expect a pinacle of journalistic integrity from Forbes and, to a lesser extent, the unabridged property ads that form the real estate section in prestigious newspapers including the Times. But to communicate this nonsense with the framing of “real estate” is treating wild speculation with unearned seriousness. This project was also co-signed by Sotheby’s. The whole thing is an embarrassing validation of a market that, predictably, would prove to have no substance. This was obvious by the time the metaverse mansion was being peddled. Eric Ravenscraft, in Wired in December 2021, reported that the attempts at artificial scarcity “more closely resembles early-access video games and common pump-and-dump schemes” than a real estate market. Indeed, a Coingecko analysis found metaverse “land” was worth 34% less in 2024 compared to the year prior, and 72% less than at its peak in 2022. This was an average across several platforms, and the biggest decline was in the Sandbox, the digital home of that mansion’s 3D model twin. According to a CoinDesk report published last year, the Sandbox laid off half its employees and its token has dropped in value from its peak by 90%. As of March 2026, user rights to space in Sandbox and Decentraland — another metaverse platform — that had originally sold for hundreds-of-thousands to millions of dollars were not a market totalling $5.37 billion as forecasted by Technavio. They had become basically worthless.
3. Fever Dream
Officially, Meta is still all-in on the concept around which it pivoted the entire company in 2021. It still has a whole marketing page proclaiming its belief “in the future of connection in the metaverse”. You can go shop its lineup of Quest headsets which Meta says represent the best and most immersive metaverse experience, though its flagship model is now two-and-a-half years old. It has awkwardly promoted its Ray-Bans as “A.I. glasses” despite them becoming the company’s most successful line of mixed reality products, and it is desperately trying to connect its newest muse of A.I. with its last one. The single mention of “metaverse” on its Q1 2026 earnings call (PDF) is when Zuckerberg claimed to be “excited for more of our metaverse efforts to be powered by the A.I. models we’re training as well”. If you want to be unfairly generous in your interpretation of Zuckerberg’s brief remark, you could point to a December 2020 Andreessen Horowitz piece, in which general partner Jonathan Lai refers to this shape as a “pyramid”, and says that “fully A.I.-created content” is directly correlated with “spontaneous social at metaverse scale”. Obviously. I am not feeling generous.
Others in the space have not fared much better. Roblox has not mentioned the word “metaverse” in its quarterly or annual reports since Q1 2022 (PDF). Epic Games scarcely mentions it in recent news releases, either: since January last year, just one announcement contains the word “metaverse”, while seven are dedicated to the lawsuits Epic has been fighting against Apple and Google. Far from the inevitable next chapter of the internet, the metaverse, supposedly the future of how we live, work, and play online, is a non-event.
Near the end of the Connect 2021 presentation, Nick Clegg, then Meta’s global affairs chief, said “the metaverse isn’t something we’re building, so much as it’s something we’re building for”. Olson, in his video, wryly notes that, in the eyes of its promoters, “the metaverse cannot fail; you can only fail to make the metaverse”. The metaverse is so inevitable that “you might even already be in it”, according to Barron’s. But the metaverse is not predestined; it never has been. It is a construction of tech companies that saw in the pandemic their future — not ours.
A slightly charitable interpretation of what I think the pandemic demonstrated to Facebook executives, for example, was how invaluable technology companies were in maintaining connections even when most people could not do so in-person. They recognized how much time people were spending in front of screens already, even in years prior, and assumed that could be a more social experience.
But a more cynical view is no less fair. With the pandemic undoubtably came a realization of how much money Facebook stood to make, if only it had a platform. In 2019, there were two publicly traded companies worth over a trillion U.S. dollars; by the end of 2021, there were five, with Apple and Microsoft now worth over two trillion dollars each. This pandemic was not going to last forever — but it did not need to. Our world was permanently changed, or so it would have seemed, and we would surely want to virtually attend concerts and buy PNG files of band t-shirts with real money. And these companies would take their cut.
One thing I have mentioned but did not emphasize is just how often Zuckerberg and Sweeney mention Apple and Google platform fees as a primary justification for building the metaverse. Sweeney spent several years fighting lawsuits against both companies, mostly winning the one against Google and mostly losing the one against Apple. His efforts have, nevertheless, shined a spotlight on these grotesque practices. But it would be a mistake to assume this is an objection on ideological grounds. These guys just want to take those commissions for themselves. Sweeney spent his GDC 2023 presentation comparing the need for open standards in the metaverse to the openness of the web, but unlike the web, the Epic Games store takes a 12% commission. Meta beat that, though; it even beat Apple and Google. By the time the individual fees are added together, transactions made through Horizon Worlds could be levied a commission of up to 47.5%. The money thing is not even a secret; it was often the very first thing people like Zuckerberg and Sweeney discussed in interviews about their metaverse plans. This was a financial decision before it was a product or service people might actually want to use.
It would not be fair to characterize Meta’s endeavour as an impulsive flash in the pan. Zuckerberg laid out his vision in a 2015 internal memo in which he explained how the company “would like a stronger strategic position in the next
wave of computing”. Then, in January 2017, the Chan Zuckerberg Initiative acquired a company called Meta, I think mostly for the name; a year later, Zuckerberg floated the idea of a rebrand. The 2015 memo that effectively set this whole thing into motion gives the impression of a surprisingly cogent document if you set aside the wildly optimistic timelines — “VR/AR will be the next major computing platform after mobile in about 10 years” — and the idea that virtual and augmented reality are so compelling it will supersede the desire for phones and televisions. If anything, the unearned confidence in this memo should have been alarming at the time. As Zuckerberg himself writes, the “core social networking work is no longer new, Internet.org is extending something rather than inventing it, and A.I. is not yet tangible”. This is not a company known for doing new, and it is now stuck with a name reflecting a bungled attempt to change that. Staff are not happy after years of mass layoffs, court losses, role reassignments, and internal surveillance to feed the company’s A.I. projects. Do not get me wrong — Meta’s business of collecting vast amounts of information about its users and selling relevant ad slots is as strong as it has ever been. But Meta the ad company is not Meta the platform innovator.
And this feels like the why of it all. If tech companies can channel a meaningful sliver of our entire lived experience into a world of their creation, one where they collect a portion of revenue, it would make them inescapable. Ball, Sweeney, and Zuckerberg may have all written or spoken about the importance of interoperability and open standards, but these platforms want to exercise a degree of control more similar to native software than to the open web. The steps for migrating from Horizon Workrooms to a competitor’s product, for instance, are not what one would expect if openness were a priority.
For a brief couple of years, it seemed like there could be enough enthusiasm from reporters in the space, venture capitalists, and executives to make the metaverse happen. Then ChatGPT launched in November 2022, and the pandemic ended in the U.S. in May 2023, and any interest anyone may have had for spending more time with people in a virtual setting largely evaporated. It turns out we are okay with having meetings and playing games online, but we actually like seeing live music in-person and travelling to real places. The problems each of these things may have — high costs, environmental impact, and so on — are notable and real, but are not ones with metaverse-based solutions.
The pandemic did not make the metaverse. There was sufficient interest in developing it well before then, and it is possible all of these companies would have announced all these products and services on the same timeline. But in a world without a pandemic, I cannot imagine anyone would have treated these metaverse announcements with anything like the seriousness they did. The pandemic officially ended in the U.S. just six months after the first release of ChatGPT, so it is impossible to disentangle the influence of either. But it is notable to me that the nosedive in mentions of “metaverse” on Meta’s investor calls occurred in Q3 2023 — the quarter immediately following the declared end of the pandemic.
As for the futurists like Hackl, who confidently proclaimed the metaverse was “for certain”, they have found an out thanks to its flexible definition. Jeff Barrett, of the Shorty Awards’ “It’s No Fluke” podcast, published a glowing profile of “the Godmother of the Metaverse” earlier this year under the headline “Why Cathy Hackl Keeps Getting the Future Right”. “When enthusiasm cooled and narratives collapsed, many distanced themselves from the space”, writes Barrett, noting with seeming approval that “Hackl did the opposite. She reframed it”. Many people — perhaps everyone, come to think of it — could predict the future if they got to retcon their predictions to fit reality.
There are many open questions about the metaverse; most glaringly among them, whether it could actually become a thing for normal people. That depends a little bit on what definition we use. If it simply means the slow erosion of the boundary between our physical and digital environments, that is probably something that will continue to happen. For most people, though, that does not look like Meta’s Connect 2021 concept animations. Whatever that ends up being will probably be the result of people finding something useful and intriguing about doing something different. It will not be the product of big companies redirecting the money hose of platform fees onto themselves.
With thanks to Marquette University for granting me access to the Zuckerberg Files. A frustrating number of Zuckerberg’s post-Meta interviews are video-based, so the transcripts produced by this effort were invaluable. Where possible, I have checked these copies against the originals.
The answer is that there’s an entire genre of media coverage best described as “rich guy has an opinion.” It’s surprisingly common, and once you notice it you’ll see it everywhere: entire news stories dedicated to the otherwise unremarkable opinion of a rich person, or news stories that fold the opinions of rich people into their otherwise neutral coverage. It’s taken for granted in many newsrooms that a person’s wealth imbues their opinions with newsworthiness.
Karl Bode has called this “CEO Said a Thing! journalism”, and it is all over the place. I think Shamshiri’s broader definition is useful, too, especially in lower-stakes situations.
This week, for example, the Calgary Herald published a whole entire article dedicated to the complaints of a local landlord about a new protected bike lane. She is quoted as saying “[t]here will be no parking whatsoever for any of the businesses that are already here” below a photograph of her standing in front of the large parking lot, which will remain unchanged following the bike lane upgrades. The only other person apparently interviewed for the article is the area’s councillor. This is just one wealthy person’s grievances treated as inherently newsworthy.
Maybe you are in the market for a great Bluesky client. Maybe you are in the market for a great Mastodon client. Maybe you are in the market for a combination great Bluesky and Mastodon client.
Today, Ben McCarthy and I are launching Indigo. It’s a full-featured client for both Mastodon and Bluesky, available on iPhone, iPad and macOS. Go get it on the App Store!
I have been using Indigo for a while as my primary iOS client for Bluesky and Mastodon, and I think it is terrific. I would happily use it as a standalone app for either. Mixing the two services in one app, though, is better than I had imagined. Everything feels right: posts are colour-coded, you can reply with either account, and there are clever ways of handling existing cross-posting.
Indigo will automatically detect when a post is duplicated across both networks. If the content is very similar and they both appear within a few minutes as each other, Indigo will merge them so you’re not seeing them twice. You can toggle between each version as well as perform actions like quoting or replying to both posts simultaneously. We’ve done a lot to make the experience of using two different services at once feel seamless.
This kind of app might not work for everyone. I understand the arguments for treating these worlds entirely differently. For me, though, this is a little bit like how I prefer reading email newsletters in my RSS app: my brain is not differentiating between articles on a website and articles sent by email when I just want to read all the new articles. Likewise, I am rarely thinking I need to check Bluesky or I need to check Mastodon; I am usually just in the mood to scroll through or post on social media. Indigo scratches that itch.
There is a caveat. Though Indigo supports multiple accounts of each type, only one of each can be active at a time. This makes sense and, I expect, would have no impact for most people. For those of us with accounts for different purposes, however, it does mean it is slightly more cumbersome than the way account switching typically works in a single-service client. This is, for me, a reasonable compromise.
Mike Masnick, of Techdirt, unsurprisingly opposes the verdicts earlier this week finding Meta and Google guilty of liability for how their products impact children’s safety. I think it is a perspective worth reading. Unlike the Wall Street Journal, Masnick respects your intelligence and brings actual substance. Still, I have some disagreements.
Masnick, on the “design choices” argument:
This distinction — between “design” and “content” — sounds reasonable for about three seconds. Then you realize it falls apart completely.
Here’s a thought experiment: imagine Instagram, but every single post is a video of paint drying. Same infinite scroll. Same autoplay. Same algorithmic recommendations. Same notification systems. Is anyone addicted? Is anyone harmed? Is anyone suing?
Of course not. Because infinite scroll is not inherently harmful. Autoplay is not inherently harmful. Algorithmic recommendations are not inherently harmful. These features only matter because of the content they deliver. The “addictive design” does nothing without the underlying user-generated content that makes people want to keep scrolling.
This sounds like a reasonable retort until you think about it for three more seconds and realize that the lack of neutrality in the outcomes of these decisions is the entire point. Users post all kinds of stuff on social media platforms, and those posts can be delivered in all kinds of different ways, as Masnick also writes. They can be shown in reverse-chronological order in a lengthy scroll, or they can be shown one at a time like with Stories. The source of the posts someone sees might be limited to just accounts a user has opted into, or it can be broadened to any account from anyone in the world. Twitter used to have a public “firehose” feed.
But many of the biggest and most popular platforms have coalesced around a feed of material users did not ask for. This is not like television, where each show has been produced and vetted by human beings, and there are expectations for what is on at different times of the day. This is automated and users have virtually no control within the platforms themselves. If you do not like what Instagram is serving you on your main feed, your choice is to stop using Instagram entirely — even if you like and use other features.
Platforms know people will post objectionable and graphic material if they are given a text box or an upload button. We know it is “impossible” to moderate a platform well at scale. But we are supposed to believe they have basically no responsibility for what users post and what their systems surface in users’ feeds? Pick one.
Masnick, on the risks of legal accountability for smaller platforms:
And this is already happening. TikTok and Snap were also named as defendants in the California case. They both settled before trial — not because they necessarily thought they’d lose on the merits, but because the cost of fighting through a multi-week jury trial can be staggering. If companies the size of TikTok and Snap can’t stomach the expense, imagine what this means for mid-size platforms, small forums, or individual website operators.
I am going to need a citation that TikTok and Snap caved because they could not afford continuing to fight. It seems just as plausible they could see which way the winds were blowing, given what I have read so far in the evidence that has been released.
Masnick:
One of the key pieces of evidence the New Mexico attorney general used against Meta was the company’s 2023 decision to add end-to-end encryption to Facebook Messenger. The argument went like this: predators used Messenger to groom minors and exchange child sexual abuse material. By encrypting those messages, Meta made it harder for law enforcement to access evidence of those crimes. Therefore, the encryption was a design choice that enabled harm.
The state is now seeking court-mandated changes including “protecting minors from encrypted communications that shield bad actors.”
Yes, the end result of the New Mexico ruling might be that Meta is ordered to make everyone’s communications less secure. That should be terrifying to everyone. Even those cheering on the verdict.
This is undeniably a worrisome precedent. I will note Raúl Torrez, New Mexico’s Attorney General and the man who brought this case against Meta, says he wants to do so for minors only. The implementation of this is an obvious question, though one that mandated age-gating would admittedly make straightforward.
Meta cited low usage when it announced earlier this month that it would be turning off end-to-end encryption in Instagram. If it is a question of safety or liability, it is one Meta would probably find difficult to articulate given end-to-end encryption remains available and enabled by default in Messenger and WhatsApp. An executive raised concerns about the feature when it was being planned, drawing a distinction between it and WhatsApp because the latter “does not make it easy to make social connections, meaning making Messenger e2ee will be far, far worse”.
I think Masnick makes some good arguments in this piece and raises some good questions. It is very possible or even likely this all gets unwound when it is appealed. I, too, expect the ripple effects of these cases to create some chaos. But I do not think the correct response to a lack of corporate accountability — or, frankly, standards — is, in Masnick’s words, “actually funding mental health care for young people”. That is not to say mental health should not be funded, only that it is a red herring response. In the U.S., total spending on children’s mental health care rose by 50% between 2011 and 2017; it continued to rise through the pandemic, of course. Perhaps that is not enough. But, also, it is extraordinary to think that we should allow companies to do knowingly harmful things and expect everyone else to correct for the predictable outcomes.
A New Mexico jury found Tuesday that social media conglomerate Meta is harmful to children’s mental health and in violation of state consumer protection law.
The landmark decision comes after a nearly seven-week trial. Jurors sided with state prosecutors who argued that Meta — which owns Instagram, Facebook and WhatsApp — prioritized profits over safety. The jury determined Meta violated parts of the state’s Unfair Practices Act on accusations the company hid what it knew [about] the dangers of child sexual exploitation on its platforms and impacts on child mental health.
Meta communications jackass Andy Stone noted on X his company’s delight to be liable for “a fraction of what the State sought”. The company says it will appeal the verdict.
Meta and Google were found liable in a landmark legal case that social media platforms are designed to be addictive to children, opening up the tech giants to penalties in thousands of similar claims filed around the US.
A jury in the Los Angeles trial on Wednesday returned a verdict after nine days of deliberation, finding Meta’s platforms such as Instagram and Google’s YouTube were harmful to children and teenagers and that the companies failed to warn users of the dangers.
To come to its liability decision, the jury was asked whether the companies’ negligence was a substantial factor in causing harm to KGM [the plaintiff] and if the tech firms knew the design of their products was dangerous. The 12-person panel of jurors returned a 10-2 split answering in favor of the plaintiff on every single question.
Collectively, the suits seek to prove that harm flowed not from user content but from the design and operation of the platforms themselves.
That’s a critical legal distinction, experts say. Social media companies have so far been protected by a powerful 1996 law called Section 230, which has shielded the apps from responsibility for what happens to children who use it.
For its part, the Wall Street Journal editorial board is standing up for beleaguered social media companies in an editorial today criticizing everything about these verdicts, including this specific means of liability, which it calls a “dodge” around Section 230.
But it is not. The principles described by Section 230 are a good foundation for the internet. This law, while U.S.-centric, has enabled the web around the world to flourish. Making companies legally liable for the things users post will not fix the mess we are in, but it would cause great damage if enacted.
Product design, though, is a different question. It would be a mistake, I think, to read Section 230 as a blanket allowance for any way platforms wish to use or display users’ posts. (Update: In part, that is because it is a free speech question.) From my entirely layman perspective, it has never struck me as entirely reasonable that the recommendations systems of these platforms should have no duty or expectation of care.
The Journal’s editorial board largely exists to produce rage bait and defend the interests of the powerful, so I am loath to give it too much attention, but I thought this paragraph was pretty rich:
Trial lawyers and juries may figure that Big Tech companies can afford to pay, but extorting companies is certain to have downstream consequences. Meta and Google are spending hundreds of billions of dollars on artificial intelligence this year, which could have positive social impacts such as accelerating treatments for cancer.
Do not sue tech companies because they could be finding cancer treatments — why should I take this editorial board seriously if its members are writing jokes like these? They think you are stupid.
As for the two cases, I am curious about how these conclusions actually play out. I imagine other people who feel their lives have been eroded by the specific way these platforms are designed will be able to test their claims in court, too, and that it will be complicated by the inevitably lengthy appeals and relitigation process.
I am admittedly a little irritated by both decisions being reached by jury instead of a judge; I would have preferred to see reasoning instead of overwhelming agreement among random people. However, it sends a strong signal to big social media platforms that people saw and heard evidence about how these products are designed, and they agreed it was damaging. This is true of all users, not just children. Meta tunes its feeds (PDF) for maximizing engagement across the board, and it surely is not the only one. There are a staggering number of partially redacted exhibits released today to go through, if one is so inclined.
If these big social platforms are listening, the signals are out there: people may be spending a lot of time with these products, but that is not a good proxy for their enjoyment or satisfaction. Research indicates a moderate amount of use is correlated with neutral or even positive outcomes among children, yet there are too many incentives in these apps to push past self-control mechanisms. These products should be designed differently.
Since roughly the turn of the millennium, Google Search has been the bedrock of the web. People loved Google’s trustworthy “10 blue links” search experience and its unspoken promise: The website you click is the website you get.
Now, Google is beginning to replace news headlines in its search results with ones that are AI-generated. After doing something similar in its Google Discover news feed, it’s starting to mess with headlines in the traditional “10 blue links,” too. We’ve found multiple examples where Google replaced headlines we wrote with ones we did not, sometimes changing their meaning in the process.
As I noted when I linked to Hollister’s article about Discover back in December, this is not new in search results; it has been happening for years.
I am not arguing this is good or normal — the examples Hollister shows are extremely poor reflections of the articles in question — but I do not understand why it is only gaining traction now, nor how it meaningfully differs from what Google has been doing all along. It is indeed frustrating.
Many of the results you see in Google Search misrepresent the source material and are misleading. But that has been true for a while — which is a problem unto itself. People should not trust the results they see as represented by Google Search. The visual tone Google has maintained, however, is that it is a neutral directory. The summaries in A.I. Overview are delivered with an unearned dry authority, and the ten links below it are there because of a tense truce between Google’s goals and those of search optimization professionals.
Also, I had no idea that Search Engine Land had been acquired at some point by Semrush which, in turn, was bought by Adobe.
The growing bloat of popular tech rhetoric could serve as evidence for how the tech industry, having conquered so much of daily life, work, and entertainment, has begun to exhaust its imaginative capacities. Industry leaders promised that the mammoth capital for AI outlay would lead to the creation of a smarter-than-human intelligence that would serve as a universal solvent, fixing climate change, poverty, and even the problem of death itself. But that horizon — which we are supposed to reach by pumping out more fossil-fuel emissions and destabilizing labor and education — remains impossibly far away.
Gallup’s polling on views of different business sectors has, frustratingly, no ability to permalink to a particular industry and its historical rankings; so, you will need to go down to “Industry and Business Sector Ratings, B Through E” and then click the pagination arrow to get to “Computer Industry” on the second page. Once there, you will find what seem at first glance to be some remarkably stable figures.
Look a little closer, though, and the numbers tell a different story. Summing the “very” and “somewhat” figures for each type of response shows a marked decline in positive reception since a high in 2017, and a steady climb in negative reception. There are lots of reasons for this; many of them I have written about. But I do not think these loudmouth executives are doing the industry any favours by bullshitting their way through interviews and promising nonsense.
That is the data-driven answer. These guys also just sound really stupid when they say stuff like “it also takes a lot of energy to train a human” or “the long-term vision is to […] create a tradeable asset out of any difference in opinion” or “I bought Twitter […] to try to help humanity, whom I love”. I know I am writing this on a website called Pixel Envy and I am, well, me, but these barons sound comical and dorky.
Nilay Patel and Liz Lopatto discussed “prediction markets” on the Verge’s “Decoder” podcast; here is Patel’s summary:
Insider trading is supposed to be illegal, and so is operating an unregulated sports book. So you’re now starting to see Kalshi and Polymarket getting hit from both sides of this broader regulatory debate, and 2026 is shaping up to be the year that all of this really comes to a head. To what end? It’s hard to say, especially as these companies cozy up to the Trump administration.
But it’s also becoming increasingly untenable for prediction markets to sit in the middle of the tension between gambling on the news and trying to self-regulate such that they don’t encourage insider trading.
A little under a month after Gallup announced it would stop polling for presidential approval, the Associated Press said it would begin integrating Kalshi bets into its election coverage. As Patel and Lopatto say, however, election betting is among the least problematic news gambling.
Hank Green was not getting a lot of traction on a promotional post on Threads about a sale on his store. He got just over thirty likes, which does not sound awful, until you learn that was over the span of seven hours and across Green’s following of 806,000 accounts on Threads.
So he tried replying to rage bait with basically the same post, and that was far more successful. But, also, it has some pretty crappy implications:
That’s the signal that Threads is taking from this: Threads is like oh, there’s a discussion going on.
It’s 2025! Meta knows that “lots of discussion” is not a surrogate for “good things happening”!
I assume the home feed ranking systems are similar for Threads and Instagram — though they might not be — and I cannot tell you how many times my feed is packed with posts from many days to a week prior. So many businesses I frequent use it as a promotional tool for time-bound things I learn about only afterward. The same thing is true of Stories, since they are sorted based on how frequently you interact with an account.
Everyone is allowed one conspiracy theory, right? Mine is that a primary reason Meta is hostile to reverse-chronological feeds is because it requires businesses to buy advertising. I have no proof to support this, but it seems entirely plausible.
Every media era gets the fabulists it deserves. If Stephen Glass, Jayson Blair and the other late 20th century fakers were looking for the prestige and power that came with journalism in that moment, then this generation’s internet scammers are scavenging in the wreckage of a degraded media environment. They’re taking advantage of an ecosystem uniquely susceptible to fraud—where publications with prestigious names publish rickety journalism under their brands, where fact-checkers have been axed and editors are overworked, where technology has made falsifying pitches and entire articles trivially easy, and where decades of devaluing journalism as simply more “content” have blurred the lines so much it can be difficult to remember where they were to begin with.
This is likely not the first story you have read about a freelancer managing to land bylines in prestigious publications thanks to dependency on A.I. tools, but it is one told very well.
Jennifer Pattison Tuohy, of the Verge, interviewed Ring founder Jamie Siminoff about a new book — which Tuohy has not read — written with Andrew Postman about the success of the company. During this conversation, Tuohy stumbled into Siminoff making a pretty outrageous claim:
While research suggests that today’s video doorbells do little to prevent crime, Siminoff believes that with enough cameras and with AI, Ring could eliminate most of it. Not all crime — “you’ll never stop crime a hundred percent … there’s crimes that are impossible to stop,” he concedes — but close.
“I think that in most normal, average neighborhoods, with the right amount of technology — not too crazy — and with AI, that we can get very close to zero out crime. Get much closer to the mission than I ever thought,” he says. “By the way, I don’t think it’s 10 years away. That’s in 12 to 24 months … maybe even within a year.”
If this sounds ridiculous to you, congratulations, you are thinking harder than whomever wrote the headline on this article:
Ring’s CEO says his cameras can almost ‘zero out crime’ within the next 12 months
The word “almost” and the phrase “very close” are working very hard to keep the core of Siminoff’s claim intact. What he says is that, by this time next year, “normal” communities with enough Ring cameras and a magic dusting of A.I. will have virtually no crime. The caveats are there to imply more nuance, but they are merely an escape hatch for when someone revisits this next year.
The near-complete elimination of crime in “normal” areas — whatever that means — will very obviously not happen. Tuohy cites a 2023 Scientific American story which, in turn, points to articles in MIT Technology Review and CNet. The first debunks a study Ring likes to promote claiming its devices drove a 55% decline in burglaries in Wilshire Park, Los Angeles in 2015, with cameras on about forty homes. Not only does the public data does not support this dramatic reduction, but:
Even if the doorbells had a positive effect, it seemed not to last. In 2017, Wilshire Park suffered more burglaries than in any of the previous seven years.
The CNet article collects a series of reports from other police departments indicating Ring cameras have questionable efficacy at deterring crime on a city-wide level.
This is also something we can know instinctually, since we already have plenty of surveillance cameras. A 2019 meta analysis (PDF) by Eric Piza, et al., found CCTV adoption decreased crime by about 13%. That is not nothing, but it is also a long way from nearly 100%. One could counter that these tests did not factor in Ring’s A.I. features, like summaries of what the camera saw — we have spent so much energy creating summary-making machines — and finding lost dogs.
The counterargument to all of this, however, is that Ring’s vision is a police state enforced by private enterprise. A 2022 paper (PDF) by Dan Calacci, et al., found race was, unsurprisingly, a motivating factor in reports of suspicious behaviour, and that reports within Ring’s Neighbors app was not correlated with the actual frequency of those crimes. Ring recently partnered with Flock, adding a further layer of creepiness.
I will allow that perhaps an article about Siminoff’s book is not the correct place to litigate these claims. By the very same logic, however, the Verge should be more cautious in publishing them, and should not have promoted them in a headline.
The uptick in artificial social networks, [Rudy] Fraser tells me, is being driven by the same tech egoists who have eroded public trust and inflamed social isolation through “divisive” algorithms. “[They] are now profiting on that isolation by creating spaces where folks can surround themselves with sycophantic bots.”
I saw this quote circulating on Bluesky over the weekend and it has been rattling around my head since. It cuts to the heart of one reason why A.I.-based “social” networks like Sora and Meta’s Vibes feel so uncomfortable.
Unfortunately, I found the very next paragraph from Parham uncompelling:
In the many conversations I had with experts, similar patterns of thought emerged. The current era of content production prioritizes aesthetics over substance. We are a culture hooked on optimization and exposure; we crave to be seen. We live on our phones and through our screens. We’re endlessly watching and being watched, submerged in a state of looking. With a sort of all-consuming greed, we are transforming into a visual-first society — an infinite form of entertainment for one another to consume, share, fight over, and find meaning through.
Of course our media reflects aesthetic trends and tastes; it always has. I do not know that there was a halcyon era of substance-over-style media, nor do I believe there was a time since celebrity was a feasible achievement in which at least some people did not desire it. In a 1948 British survey of children 10–15 years old, one-sixth to one-third of respondents aspired to “‘romantic’ [career] choices like film acting, sport, and the arts”. An article published in Scouting Magazine in 2000 noted children leaned toward high-profile careers — not necessarily celebrity, but jobs “every child is exposed to”. We love this stuff because we have always loved this stuff.
Among the bits I quibble with in the above, however, this stood out as a new and different thing: “[w]e’re endlessly watching and being watched”. That, I think, is the kind of big change Fraser is quoted as speaking about, and something I think is concerning. We already worried about echo chambers, and platforms like YouTube responded by adjustingrecommendations to less frequently send users to dark places. Let us learn something, please.
A company that still believes that its technology was imminently going to run large swathes of the economy, and would be so powerful as to reconfigure our experience of the world as we know it, wouldn’t be seeking to make a quick buck selling ads against deep fake videos of historical figures wrestling. They also wouldn’t be entertaining the idea, as [Sam] Altman did last week, that they might soon start offering an age-gated version of ChatGPT so that adults could enjoy AI-generated “erotica.”
To me, these are the acts of a company that poured tens of billions of investment dollars into creating what they hoped would be the most consequential invention in modern history, only to finally realize that what they wrought, although very cool and powerful, isn’t powerful enough on its own to deliver a new world all at once.
I do not think Sora smells of desperation, but I do think it is the product of a company that views unprecedented scale as its primary driver. I think OpenAI wants to be everywhere — and not in the same way that a consumer electronics company wants its smartphones to be the category’s most popular, or anything like that. I wonder if Ben Thompson’s view of OpenAI as “the Windows of A.I.” is sufficient. I think OpenAI is hoping to be a ubiquitous layer in our digital world; or, at least, it is behaving that way.
The Secret Service is lying to the press. They know it’s just a normal criminal SIM farm and are hyping it into some sort of national security or espionage threat. We know this because they are using the correct technical terms that demonstrate their understanding of typical SIM farm crimes. The claim that they will likely find other such SIM farms in other cities likewise shows they understand this is a normal criminal activity and not any special national security threat.
One of the things we must always keep in mind is that press releases are written to persuade. That is as true for businesses as it is for various government agencies. In this case, the Secret Service wanted attention, so they exaggerated the threat. And one wonders why public trust in institutions is falling.
The opposition’s shadow finance minister James Paterson has since urged the Australian Labor government to follow suit.
Mr Paterson told Sky News if the US was able to create a “safer version” of TikTok, then Australia should liaise with the Trump administration to become part of that solution.
“It would be an unfortunate thing if there was a safe version of TikTok in the United States, but a version of TikTok in Australia which was still controlled by a foreign authoritarian government,” he said.
I am not sure people in Australia are asking for yet more of the country’s media to be under the thumb of Rupert Murdoch. Then again, I also do not think the world needs more social media platforms controlled by the United States, though that is very clearly the wedge the U.S. government is creating: countries can accept the existing version of TikTok, adopt the new U.S.-approved one, or ban them both. The U.S. spinoff does not resolve user privacy problems and it raises new concerns about the goals of its government-friendly ownership and management.
The U.S. Secret Service dismantled a network of electronic devices located throughout the New York tristate area that were used to conduct multiple telecommunications-related threats directed towards senior U.S. government officials, which represented an imminent threat to the agency’s protective operations.
This protective intelligence investigation led to the discovery of more than 300 co-located SIM servers and 100,000 SIM cards across multiple sites.
That sure is a lot of SIM cards, and a scary-sounding mix of words in the press release:
“[…] telecommunications-related threats directed towards senior U.S. government officials […]”
“[…] these devices could be used to conduct a wide range of telecommunications attacks […]”
“These devices were concentrated within 35 miles of the global meeting of the United Nations General Assembly […]”
Reporters pounced. The New York Times, NBC News, CBS News, and even security publications like the Record seized on dramatic statements like those, and another said by the special agent in a video the Service released: “this network had the potential to […] essentially shut down the cellular network in New York City”. Scary stuff.
When I read the early reports, it sure looked to me like some reporters were getting a little over their skis.
For a start, emphasizing the apparent proximity to the U.N. in New York seems to me like a stretch. A thirty-five mile area around the U.N. looks like this — and that is diameter, not radius. If you cannot see that or this third-party website goes away at some point, that is a circle encompassing just about the entire island of Manhattan, going deep into Brooklyn and Queens, stretching all the way up to Chappaqua, and out into Connecticut and New Jersey. That is a massive area. One could just as easily say it was within thirty-five miles of any number of New York-based landmarks and be just as accurate.
Second, the ability to “facilitat[e] anonymous, encrypted communication between potential threat actors and criminal enterprises” is common to basically any internet-connected device. The scale of this one is notable, but you do not need a hundred-thousand SIM cards to make criminal plans. And the apparent possibility of “shut[ting] down the cellular network in New York” is similarly common to any large-scale installation. This is undeniably peculiar, huge, and it seems to be nefarious, but a lot of this seems to be a red herring.
Despite speculation in some reporting about SIM farm operation that suggests it was created by a foreign state such as Russia or China and used for espionage, it’s far more likely that the operation’s central focus was scams and other profit-motivated forms of cybercrime, says Ben Coon, who leads intelligence at the cybersecurity firm Unit 221b and has carried out multiple investigations into SIM farms. “The disruption of cell services is possible, flooding the network to the degree that it couldn’t take any more traffic,” Coon says. “My gut is telling me there was some type of fraud involved here.”
These reporters point to a CNN article by John Miller and Celina Tebor elaborating on the threat to “senior U.S. government officials”: they were swatting calls targeting various lawmakers. Not nothing and certainly dangerous, but this is not looking anything like how many reporters have described it, nor what the U.S. Secret Service is suggesting through its word choices.
[…] In 2018, the social-science blog “Data Colada” looked at Metacritic, a review aggregator, and found that more than four out of five albums released that year had received an average rating of at least seventy points out of a hundred — on the site, albums that score sixty-one or above are colored green, for “good.” Even today, music reviews on Metacritic are almost always green, unlike reviews of films, which are more likely to be yellow, for “mixed/average,” or red, for “bad.” The music site Pitchfork, which was once known for its scabrous reviews, hasn’t handed down a perfectly contemptuous score — 0.0 out of 10 — since 2007 (for “This Is Next,” an inoffensive indie-rock compilation). And, in 2022, decades too late for poor Andrew Ridgeley, Rolling Stone abolished its famous five-star system and installed a milder replacement: a pair of merit badges, “Instant Classic” and “Hear This.”
I have quibbles with this article, which I will get to, but I will front-load this with the twist instead of making you wait — this article is, in effect, Sanneh’s response to himself twenty-one years after popularizing the very concept of poptimism in the New York Times. Sanneh in 2004:
In the end, the problem with rockism isn’t that it’s wrong: all critics are wrong sometimes, and some critics (now doesn’t seem like the right time to name names) are wrong almost all the time. The problem with rockism is that it seems increasingly far removed from the way most people actually listen to music.
Are you really pondering the phony distinction between “great art” and a “guilty pleasure” when you’re humming along to the radio? In an era when listeners routinely — and fearlessly — pick music by putting a 40-gig iPod on shuffle, surely we have more interesting things to worry about than that someone might be lip-synching on “Saturday Night Live” or that some rappers gild their phooey. Good critics are good listeners, and the problem with rockism is that it gets in the way of listening. If you’re waiting for some song that conjures up soul or honesty or grit or rebellion, you might miss out on Ciara’s ecstatic electro-pop, or Alan Jackson’s sly country ballads, or Lloyd Banks’s felonious purr.
Here we are in 2025 and a bunch of the best-reviewed records in recent memory are also some of the most popular. They are well-regarded because critics began to review pop records on the genre’s own terms.
Here is one more bonus twist: the New Yorker article is also preoccupied with criticism of Pitchfork, a fellow Condé Nast publication. This is gestured toward twice in the article. Neither one serves to deflate the discomfort, especially since the second mention is in the context of reduced investment in the site by Condé.
Speaking of Pitchfork, though, the numerical scores of its reviews have led to considerable analysis by the statistics obsessed. For example, a 2020 analysis of reviews published between 1999 and early 2017 found the median score was 7.03. This is not bad at all, and it suggests the site is most interested in what it considers decent-to-good music, and cannot be bothered to review bad stuff. The researchers also found a decreasing frequency of very negative reviews beginning in about 2010, which fits Sanneh’s thesis. However, it also found fewer extremely high scores. The difference is more subtle — and you should ignore the dot in the “10.0” column because the source data set appears to also contain Pitchfork’s modern reviews of classic records — but notice how many dots are rated above 8.75 from 2004–2009 compared to later years. A similar analysis of reviews from 1999–2021 found a similar convergence toward mediocre.
As for Metacritic, I had to go and look up the Data Colada article referenced, since the New Yorker does not bother with links. I do not think this piece reinforces Sanneh’s argument very well. What Joe Simmons, its author, attempts to illustrate is that Metacritic skews positive for bands with few aggregated reviews because most music publications are not going to waste time dunking on a nascent band’s early work. I also think Simmons is particularly cruel to a Modern Studies record.
Anecdotally, I do not know that music critics have truly lost their edge. I read and watch a fair amount of music criticism, and I still see a generous number of withering takes. I think music critics, as they become established and busier, recognize they have little time for bad music. Maroon 5 have been a best-selling act for a couple of decades, but Metacritic has aggregated just four reviews of its latest album, because you can just assume it sucks. Your time might be better spent with the great new Water From Your Eyes record.
Even though I am unsure I agree with Sanneh’s conclusion, I think critics should make time and column space for albums they think are bad. Negative reviews are not cruel — or, at least, they should not be — but it is the presence of bad that helps us understand what is good.
The social networking app is now home to more than 400 million monthly active users, Meta shared with Fast Company on Tuesday. That’s 50 million more than just a few months ago, and a long way from the 175 million it had around its first birthday last summer.
What is even more amazing about this statistic is how non-essential Threads seems to be. I might be in a bubble, but I cannot recall the last time someone sent me a link to a Threads post or mentioned they saw something worthwhile there. I see plenty of screenshots of posts from Bluesky, X, and even Mastodon circulating in various other social networks, but I cannot remember a single one from Threads.
Over the past week, I’ve been working to track down the new owner of MacSurfer’s Headline News, a beloved site that shut down in 2020 and has recently had somewhat mysterious revival. Fortunately, after some digging that didn’t really lead anywhere, I received an email from its new owner, Ken Turner, and he graciously took the time to answer a few questions about the new project.
Turner sounds like a great steward to carry on the MacSurfer legacy. Even in an era of well-known aggregators like Techmeme and massive forums like Hacker News and Reddit, I think there is still a role for a smaller and more focused media tracking site.
I am uncertain what the role of BackBeat Media is in all this. I have not heard from Dave Hamilton or anyone there to confirm if they even have a role.
Five years ago, Apple and tech news aggregator MacSurfer announced it was shutting down. The site was still accessible albeit in a stopped-time state, and it seemed that is how it would sit until the server died.
In June, though, MacSurfer was relaunched. The design has been updated and it is no longer as technically simple as it once was, but — charmingly — the logo appears to be the exact same static GIF as always. I cannot find any official announcement of its return.
It looks like Macsurfer is coming back, but I can’t find any details or who’s behind it? I really hope it’s not AI slop or someone trying to make a buck off nostalgia like iLounge or TUAW.
I had the same question, so I started digging. MxToolbox reveals a txt record on the domain for validating with Google apps, registered to BackBeat Media. BackBeat’s other properties include the Mac Observer, AppleInsider, and PowerPage. A review of historical MacSurfer txt records using SecurityTrails indicates the site has been with Backbeat Media since at least 2011, even though BackBeat’s site has not listed MacSurfer even when it was actively updated.
I cannot confirm the ownership is the same yet but I have asked Dave Hamilton, of BackBeat, and will update this if I hear back.
The Financial Times today published an article by Anna Gross, Tim Bradshaw, and Lauren Fedor, in which the three paint a picture of a complex stalemate between investment interests and the U.K. government’s snooping desires:
Sir Keir Starmer’s government is seeking a way out of a clash with the Trump administration over the UK’s demand that Apple provide it with access to secure customer data, two senior British officials have told the Financial Times.
The officials both said the Home Office, which ordered the tech giant in January to grant access to its most secure cloud storage system, would probably have to retreat in the face of pressure from senior leaders in Washington, including vice-president JD Vance.
The writers go on to describe the tension between U.K. and U.S. authorities, with sources telling them the U.K. definitely wants this capability, but feels the weight of the U.S. administration. Here are two things I think are true:
The U.K. should not be demanding access to iCloud data end-to-end encrypted by Advanced Data Protection — and certainly not worldwide, as it wants. It is terrible on the merits, it will be misused, and it is ridiculous nobody can talk about it directly because of secrecy requirements.
The U.S. continues to abuse its power in worrisome ways. There is no evidence this administration is objecting to the U.K. law on the merits of free speech, given how bad they are on speech in general. There is lots of reason to believe they are simply hostile to any attempts at regulating the massive technology companies that happen to come from the U.S. and reinforce its global power. It is not just the U.K.; the Canadian government pulled a fairly reasonable Digital Services Tax to placate this administration for similar reasons.
Bad faith rationale aside, the U.K. seems to be thinking about retreating from its backdoor efforts, though it has not yet made any moves to do so. Yet Ars Technica, which syndicates the occasional Times story, republished this article under the headline “UK backing down on Apple encryption backdoor after pressure from US”. That is not true — not yet, anyway.
And there is reason to be skeptical of the Times’ sourcing on these matters, too. In 2023, its reporters — including Gross, who also worked on this Advanced Data Protection story — were told the U.K. government would no longer demand the breaking of end-to-end encryption in messaging apps. This was only true in the sense the government no longer demanded impossible backdoors, only possible ones. This was not so much rescinding a demand as it was clarifying it.
Until the U.K. formally withdraws the technical capability notice served to Apple — and maybe Google, too — we should assume they are still pushing for a backdoor. And, because of the secrecy rules, if they do rescind it, it seems we will only find out in a leak to the Times or the BBC, without any official acknowledgement any of this took place.
Think about where Stephen Colbert started. At Comedy Central, he played a character who parodied right-wing media manipulation. His whole schtick was pretending to be a Fox News-style propagandist who twisted facts, attacked critics, and defended power at all costs.
Twenty years later, he’s been silenced by actual media manipulation. Real billionaires wielding real power to protect their real financial interests.
The writers who created The Colbert Report couldn’t have scripted it better. Except this isn’t satire. It’s just what happens now when media companies need government approval for their deals.
Regardless of how much you like Colbert’s take on the Late Show — I do not care for it — the circumstances around its cancellation are suspicious and the implications are alarming. Were Colbert’s jokes truly cutting to the core of the Trump administration? I hardly think so. But it is nevertheless difficult not to see it as an olive branch for merger approval — an implied condition.
(Update: Anonymous sources swore up and down to the New York Times that this was purely a financial decision.)
Via Rusty Foster, who ties together a bunch of threads on this into the title thesis, “billionaires destroyed American news media on purpose”:
When I told my new friend that the American news media has been systematically and intentionally destroyed by a handful of billionaires, he asked an extremely reasonable question, which was: “but why?” And what makes this feel like a conspiracy is that there is no single answer to “why?” Sometimes it’s arrogance, sometimes it’s ideology, sometimes it’s purely money. Often it’s a messy combination of all three.
But if you really want to step back a bit, the reason why is that we have a socioeconomic system that concentrates nation-state level wealth and power in the hands of a few individuals, with virtually no checks on what they can choose to do with it. So if Larry Ellison wants to turn CBS News into Bari Weiss’s Free Press TV, or Jeff Bezos wants to make The Washington Post into an ideological subsidiary of the Cato Institute… what institutions of power will be left to disagree?
In related news, U.S. lawmakers voted to end federal funding for NPR and PBS. Conservatives in Canada are waging a similar campaign to stop funding the CBC, and I hope it fails.
Wikipedia is coming up on its 25th birthday, and that would not have been possible without the Wikimedia technical volunteer community. Supporting technical volunteers is crucial to carrying forward Wikimedia’s free knowledge mission for generations to come. In line with this commitment, the Foundation is turning its attention to an important area of developer support—the Wikimedia web (HTTP) APIs.
Both Wikimedia and the Internet have changed a lot over the last 25 years. Patterns that are now ubiquitous standards either didn’t exist or were still in their infancy as the first APIs allowing developers to extend features and automate tasks on Wikimedia projects emerged. In fact, the term “representational state transfer”, better known today as the REST framework, was first coined in 2000, just months before the very first Wikipedia post was published, and only 6 years before the Action API was introduced. Because we preceded what have since become industry standards, our most powerful and comprehensive API solution, the Action API, sticks out as being unlike other APIs – but for good reason, if you understand the history.
Wikimedia APIs are used within Foundation-authored features and by volunteer developers. A common sentiment surfaced through the recent API Listening Tour conducted with a mix of volunteers and Foundation staff is “Wikimedia APIs are great, once you know what you’re doing.” New developers first entering the Wikimedia community face a steep learning curve when trying to onboard due to unfamiliar technologies and complex APIs that may require a deep understanding of the underlying Wikimedia systems and processes. While recognizing the power, flexibility, and mission-critical value that developers created using the existing API solutions, we want to make it easier for developers to make more meaningful contributions faster. We have no plans to deprecate the Action API nor treat it as ‘legacy’. Instead, we hope to make it easier and more approachable for both new and experienced developers to use. We also aim to expand REST coverage to better serve developers who are more comfortable working in those structures.
We are focused on simplifying, modernizing, and standardizing Wikimedia API offerings as part of the Responsible Use of Infrastructure objective in the FY25-26 Annual Plan (see: the WE5.2 key result). Focusing on common infrastructure that encourages responsible use allows us to continue to prioritize reliable, free access to knowledge for the technical volunteer community, as well as the readers and contributors they support. Investing in our APIs and the developer experiences surrounding them will ensure a healthy technical community for years to come. To achieve these objectives, we see three main areas for improving the sustainability of our API offering: simplification, documentation, and communication.
Simplification
To reduce maintenance costs and ensure a seamless developer experience, we are simplifying our API infrastructure and bringing greater consistency across all APIs. Decades of organic growth without centralized API governance led to fragmented, bespoke implementations that now hinder technical agility and standardization. Beyond that, maintaining services is not free; we are paying for duplicative infrastructure costs, some of which are scaling directly with the amount of scraper traffic hitting our services.
In light of the above, we will focus on transitioning at least 70% of our public endpoints to common API infrastructure (see the WE 5.2 key result). Common infrastructure makes it easier to maintain and roll out changes across our APIs, in addition to empowering API authors to move faster. Instead of expecting API authors to build and manage their own solutions for things like routing and rate limiting, we will create centralized tools and processes that make it easier to follow the “golden path” of recommended standards. That will allow centralized governance mechanisms to drive more consistent and sustainable end-user experiences, while enabling flexible, federated API ownership.
An example of simplified internal infrastructure will be introducing a common API Gateway for handling and routing all Wikimedia API requests. Our approach will start as an “invisible gateway” or proxy, with no changes to URL structure or functional behavior for any existing APIs. Centralizing API traffic will make observability across APIs easier, allowing us to make better data-driven decisions. We will use this data to inform endpoint deprecation and versioning, prioritize human and mission-oriented access first, and ultimately provide better support to our developer community.
Centralized management and traffic identification will also allow us to have more consistent and transparent enforcement of our API policies. API policy enforcement enables us to protect our infrastructure and ensure continued access for all. Once API traffic is rerouted through a centralized gateway, we will explore simplifying options for developer identification mechanisms and standardizing how rate limits and other API access controls are applied. The goal is to make it easier for all developers to know exactly what is expected and what limitations apply.
As we update our API usage policies and developer requirements, we will avoid breaking existing community tools as much as possible. We will continue offering low-friction entry points for volunteer developers experimenting with new ideas, lightly exploring data, or learning to build in the Wikimedia ecosystem. But we must balance support for community creativity and innovation with the need to reduce abuse, such as scraping, Denial of Service (DoS) attacks, and other harmful activities. While open, unauthenticated API access for everyone will continue, we will need to make adjustments. To reduce the likelihood and impact of abuse, we may apply stricter rate limits to unauthenticated traffic and more consistent authentication requirements to better match our documented API policy, Robot policy, and API etiquette guidelines, as well as consolidate per-API access guidelines to reduce the likelihood and impact of abuse.
To continue supporting Wikimedia’s technical volunteer community and minimize disruption to existing tools, community developers will have simple ways to identify themselves and receive higher limits or other access privileges. In many cases, this won’t require additional steps. For example, instead of universally requiring new access tokens or authentication methods, we plan to use IP ranges from Wikimedia Cloud Services (WMCS) and User-Agent headers to grant elevated privileges to trusted community tools, approved bots, and research projects.
Documentation
It is essential for any API to enable developers to self-serve their use cases through clear, consistent, and modern documentation experiences. However, Wikimedia API documentation is frequently spread across multiple wiki projects, generated sites, and communication channels, which can make it difficult for developers to find the information they need, when they need it.
To address this, we are working towards a top-requested item coming out of the 2024 developer satisfaction survey: OpenAPI specs and interactive sandboxes for all of our APIs (including conducting experiments to see if we can use OpenAPI to describe the Action API). The MediaWiki Interfaces team began addressing this request through the REST Sandbox, which we released to a limited number of small Wikipedia projects on March 31, 2025. Our implementation approach allows us to generate an OpenAPI specification, which we then use to power a SwaggerUI sandbox. We are also using the OpenAPI specs to automatically validate our endpoints as part of our automated deployment testing, which helps ensure that the generated documentation always matches the actual endpoint behavior.
In addition, the generated OpenAPI spec offers translation support (powered by Translatewiki) for critical and contextual information like endpoint and parameter descriptions. We believe this is a more equitable approach to API documentation for developers who don’t have English as their preferred language. In the coming year, we plan to transition from Swagger UI to a custom Codex implementation for our sandbox experiences, which will enable full translation support for sandbox UI labels and navigation, as well as a more consistent look and feel for Wikimedia developers. We will also expand coverage for OpenAPI specs and sandbox experiences by introducing repeatable patterns for API authors to publish their specs to a single location where developers can easily browse, learn, and make test calls across all Wikimedia API offerings.
Communication
When new endpoints are released or breaking changes are required, we need a better way to keep developers informed. As information is shared through different channels, it can become challenging to keep track of the full picture. Over the next year, we will address this on a few fronts.
First, from a technical change management perspective, we will introduce a centralized API changelog. The changelog will summarize new endpoints, as well as new versions, planned deprecations, and minor changes such as new optional parameters. This will help developers with troubleshooting, as well as help them to more easily understand and monitor the changes happening across the Wikimedia APIs.
In addition to the changelog, we remain committed to consistently communicating changes early and often. As another step towards this commitment, we will provide migration guides and, where needed, provide direct communication channels for developers impacted by the changes to help guarantee a smooth transition. Recognizing that the Wikimedia technical community is split across many smaller communities both on and off-wiki, we will share updates in the largest off-wiki communities, but we will need volunteer support in directing questions and feedback to the right on-wiki pages in various languages. We will also work with communities to make their purpose and audience clearer for new developers so they can more easily get support when they need it and join the discussion with fellow technical contributors.
Over the next few months, we will also launch a new API beta program, where developers are invited to interact with new endpoints and provide feedback before the capabilities are locked into a long-term stable version. Introducing new patterns through a beta program will allow developers to directly shape the future of the Wikimedia APIs to better suit their needs. To demonstrate this pattern, we will start with changes to MediaWiki REST APIs, including introducing API modularization and consistent structures.
What’s Next
We are still in the early stages – we are just making the first steps on the journey to a unified API product offering. But we hope that by this time next year, we will be running towards it together. Your involvement and insights can help us shape a future that better serves the technical volunteers behind our knowledge mission. To keep you informed, we will continue to post updates on mailing lists, Diff, TechBlog, and other technical volunteer communication channels. We also invite you to stay actively engaged: share your thoughts on the WE5 objective in the annual plan, ask questions on the related discussion pages, review slides from the Future of Wikimedia APIs session we conducted at the Wikimedia Hackathon, volunteer for upcoming Listening Tour topics, or come talk to us at upcoming events such as Wikimania Nairobi.
Technical volunteers play an essential role in the growth and evolution of Wikipedia, as well as all other Wikimedia projects. Together, we can make a better experience for developers who can’t remember life before Wikipedia, and make sure that the next generation doesn’t have to live without it. Here’s to another 25 years!
Apple issued a news release today touting the safety of the App Store, dutifully covered without context by outlets like 9to5Mac, AppleInsider, and MacRumors. This has become an annual tradition in trying to convince people — specifically, developers and regulators — of the wisdom of allowing native software to be distributed for iOS only through the App Store. Apple published similar stats in 2021, 2022, 2023, and 2024, reflecting the company’s efforts in each preceding year. Each contains similar figures; for example:
In its new report, Apple says it “terminated more than 146,000 developer accounts over fraud concerns” in 2024, an increase from 118,000 in 2023, which itself was a decrease from 428,000 in 2022. Apple said the decrease between 2022 and 2023 was “thanks to continued improvements to prevent the creation of potentially fraudulent accounts in the first place”. Does the increase in 2024 reflect poorer initial anti-fraud controls, or an increase in fraud attempts? Is it possible to know either way?
Apple says it deactivated “nearly 129 million customer accounts” in 2024, a significant decrease from deactivating 374 million the year prior. However, it blocked 711 million account creations in 2024, which is several times greater than the 153 million blocked in the year before. Compare to 2022, when it disabled 282 million accounts and prevented the creation of 198 million potentially fraudulent accounts. In 2021, the same numbers were 170 million and 118 million; in 2020, 244 million and 424 million. These numbers are all over the place.
A new statistic Apple is publishing this year is “illicit app distribution”. It says that, in the past month, it “stopped nearly 4.6 million attempts to install or launch apps distributed illicitly outside the App Store or approved third-party marketplaces”. These are not necessarily fraudulent, pirated, or otherwise untoward apps. This statistic is basically a reflection of the control maintained by Apple over iOS regardless of user intentions.
There are plenty of numbers just like these in Apple’s press release. They all look impressive in large part because just about any statistic would be at Apple’s scale. Apple is also undeniably using the App Store to act as a fraud reduction filter, with mixed results. I do not expect a 100% success rate, but I still do not know how much can be gleaned from context-free numbers.
Over this past weekend, the Chicago Sun-Times and Philadelphia Inquirer’s weekend editions included identical huge “Best of Summer” inserts; in the Inquirer’s digital edition the insert runs 54 pages, while the entire rest of the paper occupies 36. Before long, readers began noticing something strange about the “Summer reading list for 2025” section of the insert. Namely, that while the list includes some very well-known authors, most of the books listed in it do not exist.
This is the kind of fluffy insert long purchased by publishers to pad newspapers. In this case, it appears to be produced by Hearst Communications, which feels about right for something with Hearst’s name on it. I cannot imagine most publishers read these things very carefully; adding more work or responsibility is not the point of buying a guide like this.
What I found very funny today was watching the real-time reporting of this story in parallel with Google’s I/O presentation, at which it announced one artificial intelligence feature after another. On the one hand, A.I. features can help you buy event tickets or generate emails offering travel advice based on photos from trips you have taken. On the other, it is inventing books, experts, and diet advice.
You need to have your own corner of the internet, a place where you can build a home, on your own land, with assets you control.
Our system gives creators ownership. With Substack, you have your own property to build on: content you own, a URL of your choosing, a website for your work, and a mailing list of your subscribers that you can export and take with you at any time.
This is a message the company reinforces because it justifies a wildly permissive environment for posters that requires little oversight. But it is barely more true that Substack is “your own land, with assets you control” than, say, a YouTube channel. The main thing Substack has going for it is that you can export a list of subscribers’ email accounts. Otherwise, the availability of your material remains subject to Substack’s priorities and policies.
What Substack in fact offers, and what differentiates it from a true self-owned “land”, is a comprehensive set of media formats and opportunities for promotion.
Substack today has all of the functionalities of a social platform, allowing proprietors to engage with both subscribers (via the Chat feature) or the broader Substack universe in the Twitter-esque Notes feed. Writers I spoke to mentioned that for all of their reluctance to engage with the Notes feature, they see growth when they do. More than 50 percent of all subscriptions and 30 percent of paid subscriptions on the platform come directly from the Substack network. There’s been a broader shift toward multimedia content: Over half of the 250 highest-revenue creators were using audio and video in April 2024, a number that had surged to 82 percent by February 2025.
Substack is now a blogging platform with email capabilities, a text-based social platform, a podcasting platform, and a video host — all of which can be placed behind a paywall. This is a logical evolution for the company. But please do not confuse this with infrastructure. YouTube can moderate its platform as it chooses and so can Substack. The latter has decided to create a special category filled to the brim with vaccine denialism publications that have “tens of thousands of paid subscribers”, from which Substack takes ten percent of earnings.
The best way to think of the slop and spam that generative AI enables is as a brute force attack on the algorithms that control the internet and which govern how a large segment of the public interprets the nature of reality. It is not just that people making AI slop are spamming the internet, it’s that the intended “audience” of AI slop is social media and search algorithms, not human beings.
[…]
“Brute force” is not just what I have noticed while reporting on the spammers who flood Facebook, Instagram, TikTok, YouTube, and Google with AI-generated spam. It is the stated strategy of the people getting rich off of AI slop.
Regardless of whether you have been following Koebler’s A.I. slop beat, you owe it to yourself to read this article at least. The goal, Koelber surmises, is for Meta to target slop and ads at users in more-or-less the same way and, because this slop is cheap and fast to produce, it is a bottomless cup of engagement metrics.
As I wrote last week, the strategy with these types of posts is to make a human linger on them long enough to say to themselves “what the fuck,” or to be so horrified as to comment “what the fuck,” or send it to a friend saying “what the fuck,” all of which are signals to the algorithm that it should boost this type of content but are decidedly not signals that the average person actually wants to see this type of thing. The type of content that I am seeing right now makes “Elsagate,” the YouTube scandal in which disturbing videos were targeted to kids and resulted in various YouTube reforms, look quaint.
Meta is testing an Instagram feature that suggests AI-generated comments for users to post beneath other users’ photos and videos.
Meta is going to make so much money before it completely disintegrates on account of nobody wanting to spend this much time around a thin veneer over robots.
With this release, you can now display replies by “hotness,” which weights liked replies that are more recent more heavily.
I believe this replaced the past reply sorting of oldest to newest. People seem worried this can be gamed, but there is good news: you can just change it. There are options for oldest replies, newest replies, most-liked, and one that is completely randomized. Also, you can still set it to prioritize people you follow.
Imagine that: options for viewing social media that give control back to users. Threads is experimenting, but Meta still fundamentally distrusts users to make decisions like these.
Speaking of podcasts, Michael Hobbes dove into Jonathan Haidt’s “The Anxious Generation” — previously mentioned — for his “If Books Could Kill” podcast. At two hours, it is the longest single episode they have done, but it is worth it for Hobbes’ careful exploration. There is some profanity.
On August 1, 2023, in response to Bill C-18, Meta blocked Canadians from viewing, accessing, and sharing news article links on its platforms. Over the past 12 months, our team of researchers has closely monitored the effects of the ban particularly on Canadian news organizations and how Canadians engage with news and political content online.
I read the report; I was underwhelmed. Its authors provide no information about how news websites and apps have performed in the past year. Instead, they use the popularity of news outlets on social media as a proxy for their popularity generally and have found — unsurprisingly — that many Canadian publications have reduced or stopped using Meta platforms to promote their work. This decline was not offset by other social platforms. But this says nothing about how publications have fared in general.
Unfortunately, only publishers would be able to compare the use of their websites and apps today compared to a year ago. Every other source only provides an estimate. Semrush, for example, says it has a “unique panel of over 200 million” users and it ingests billions of data points each month to build a picture of actual browsing. Its ranking, which I have preserved in its current June 2024 state, indicates a 6.7% decline in traffic to the CBC’s website compared to June a year ago, a 6.2% decline for CTV News, a 4.2% decline for Global News, a 12.3% increase for City News, a 27.8% decline for the Star, and a 20.4% increase for the National Post. Among the hardest-hit publications were French language publications like Journal de Montreal and TVA Nouvelles. Some of these traffic losses are pretty large, but none are anywhere near the 43% decline in “online engagement” cited in this report.
I could not find a source for app popularity in Canada over time — or, at least, not one I could access.
To be sure, it would not surprise me to learn traffic had dropped for many publishers. But it is a mixed bag, with some indicating large increases in web visitors. The point I am trying to make is that we simply do not have a good picture of actual popularity, and this Observatory report is only confusing matters. Social media buzz is not always a good representation of actual readership, and it is frustrating that the only information we can glean is irrelevant.
A story that’s been persistently making the rounds since the CrowdStrike event is that while several airline companies were affected in one way or another, Southwest Airlines escaped the mayhem because they were still using Windows 3.1. It’s a great story that fits the current zeitgeist about technology and its role in society, underlining that what is claimed to be technological progress is nothing but trouble, and that it’s better to stick with the old. At the same time, anybody who dislikes Southwest Airlines can point and laugh at the bumbling idiots working there for still using Windows 3.1. It’s like a perfect storm of technology news click and ragebait.
Too bad the whole story is nonsense.
I would say Holwerda’s debunking is a thorough exploration of how so many media outlets got this story wrong but — and I mean this in the nicest possible way — that would be overselling it. As Holwerda admits, it took scarcely any research to fact check a claim carried by Tom’s Hardware, Tech Radar, Forbes, Digital Trends, and lots of others. Embarrassing.
BNN (the “Breaking News Network”, a news website operated by tech entrepreneur and convicted domestic abuser Gurbaksh Chahal) allegedly offers independent news coverage from an extensive worldwide network of on-the-ground reporters. As is often the case, things are not as they seem. A few minutes of perfunctory Googling reveals that much of BNN’s “coverage” appears to be mildly reworded articles copied from mainstream news sites. For science, here’s a simple technique for algorithmically detecting this form of copying.
Many traditional news organizations are already fighting for traffic and advertising dollars. For years, they competed for clicks against pink slime journalism — so-called because of its similarity to liquefied beef, an unappetizing, low-cost food additive.
Low-paid freelancers and algorithms have churned out much of the faux-news content, prizing speed and volume over accuracy. Now, experts say, A.I. could turbocharge the threat, easily ripping off the work of journalists and enabling error-ridden counterfeits to circulate even more widely — as has already happened with travel guidebooks, celebrity biographies and obituaries.
See, it is not just humans producing abject garbage; robots can do it, too — and way better. There was a time when newsrooms could be financially stable on display ads. Those days are over for a team of human reporters, even if all they do is rewrite rich guy tweets. But if you only need to pay a skeleton operations staff to ensure the robots continue their automated publishing schedule, well that becomes a more plausible business venture.
Another thing of note from the Times story:
Before ending its agreement with BNN Breaking, Microsoft had licensed content from the site for MSN.com, as it does with reputable news organizations such as Bloomberg and The Wall Street Journal, republishing their articles and splitting the advertising revenue.
I have to wonder how much of an impact this co-sign had on the success of BNN Breaking. Syndicated articles on MSN like these are shown in various places on a Windows computer, and are boosted in Bing search results. Microsoft is increasingly dependent on A.I. for editing its MSN portal with predictable consequences.
The YouTube channel is not the only data point that connects Trimfeed to BNN. A quick comparison of the bylines on BNN’s and Trimfeed’s (plagiarized) articles shows that many of the same names appear on both sites, and several X accounts that regularly posted links to BNN articles prior to April 2024 now post links to Trimfeed content. Additionally, BNN seems to have largely stopped publishing in early April, both on its website and social media, with the Trimfeed website and related social media efforts activating shortly thereafter. It is possible that BNN was mothballed due to being downranked in Google search results in March 2024, and that the new Trimfeed site is an attempt to evade Google’s decision to classify Trimfeed’s predecessor as spam.
The Times reporters definitively linked the two and, after doing so, Trimfeed stopped publishing. Its domain, like BNN Breaking, now redirects to BNNGPT, which ostensibly uses proprietary technologies developed by Chahal. Nothing about this makes sense to me and it smells like bullshit.
Monday, Elon Musk tweeted a thing about Apple’s marketing event, an act that took Musk three seconds but then led to a large portion of the dwindling number of employed human tech journalists to spring into action and collectively spend many hours writing blogs about What This Thing That Probably Won’t Happen All Means.
Journalists are quick to insist that it’s their noble responsibility to cover the comments of important people. But journalism is about informing and educating the public, which isn’t accomplished by redirecting limited journalistic resources to cover platform bullshit that means nothing and will result in nothing meaningful. All you’ve done is made a little money wasting people’s time.
The speed at which some publishers insist these “articles” are posted combined with a lack of constraints in airtime or physical paper means the loudest people know they can draw attention by posting deranged nonsense. All those people who got into journalism because they thought they could make a difference are instead cajoled into adding something resembling substance to forty-four tweeted words from the fingers of a dipshit.
Ashley Belanger, reporting for Ars Technica in July 2022 in what I will call “foreshadowing”:
Despite all the negative feedback [over then-recent Instagram changes], Meta revealed on an earnings call that it plans to more than double the number of AI-recommended Reels that users see. The company estimates that in 2023, about a third of Instagram and Facebook feeds will be recommended content.
In this document [leaked to Zitron], they discuss the term “meaningful interactions,” the underlying metric which (allegedly) guides Facebook today. In January 2018, Adam Mosseri, then Head of News Feed, would post that an update to the News Feed would now “prioritize posts that spark conversations and meaningful interactions between people,” which may explain the chaos (and rot) in the News Feed thereafter.
To be clear, metrics around time spent hung around at the company, especially with regard to video, and Facebook has repeatedly and intentionally made changes to manipulate its users to satisfy them. In his book “Broken Code,” Jeff Horwitz notes that Facebook “changed its News Feed design to encourage people to click on the reshare button or follow a page when they viewed a post,” with “engineers altering the Facebook algorithm to increase how often users saw content reshared from people they didn’t know.”
When you look at Instagram or Facebook, I want you to try and think of them less as social networks, and more as a form of anthropological experiment. Every single thing you see on either platform is built or selected to make you spend more time on the app and see more things that Meta wants you to see, be they ads, sponsored content, or suggested groups that you can interact with, thus increasing the amount of your “time spent” on the app, and increasing the amount of “meaningful interactions” you have with content.
Zitron is a little too eager, for my tastes, to treat Meta’s suggestions of objectionable and controversial posts as deliberate. It seems much more likely the company simply sucks at moderating this stuff at scale and is throwing in the towel.
In late 2021, TikTok was on the rise, Facebook interactions were declining after a pandemic boom and young people were leaving the social network in droves. Chief Executive Officer Mark Zuckerberg assembled a handful of veterans who’d built their careers on the Big Blue app to figure out how to stop the bleeding, including head of product Chris Cox, Instagram boss Adam Mosseri, WhatsApp lead Will Cathcart and head of Facebook, Tom Alison.
During discussions that spanned several meetings, a private WhatsApp group, and an eventual presentation at Zuckerberg’s house in Palo Alto, California, the group came to a decision: The best way to revive Facebook’s status as an online destination for young people was to start serving up more content from outside a person’s network of friends and family.
At first, previously viral (but real) images were being run through image-to-image AI generators to create a variety of different but plausibly believable AI images. These images repeatedly went viral, and seemingly tricked real people into believing they were real. I was able to identify a handful of the “source” or “seed” images that formed the basis for this type of content. Over time, however, most AI images on Facebook have gotten a lot easier to identify as AI and a lot more bizarre. This is presumably happening because people will interact with the images anyway, or the people running these pages have realized they don’t need actual human interaction to go viral on Facebook.
Instagram confirmed it’s testing unskippable ads after screenshots of the feature began circulating across social media. These new ad breaks will display a countdown timer that stops users from being able to browse through more content on the app until they view the ad, according to informational text displayed in the Instagram app.
These pieces each seem like they are circling a theme of a company finding the upper bound of its user base, and then squeezing it for activity, revenue, and promising numbers to report to investors. Unlike Zitron, I am not convinced we are watching Facebook die. I think Koebler is closer to the truth: we are watching its zombification.
Apple finished naming what it — well, its “team of experts alongside a select group of artists […] songwriters, producers, and industry professionals” — believes are the hundred best albums of all time. Like pretty much every list of the type, it is overwhelmingly Anglocentric, there are obvious picks, surprise appearances good and bad, and snubs.
I am surprised the publication of this list has generated as much attention as it has. There is a whole Wall Street Journal article with more information about how it was put together, a Slate thinkpiece arguing this ranking “proves [Apple has] lost its way”, and a Variety article claiming it is more-or-less “rage bait”.
Frankly, none of this feels sincere. Not Apple’s list, and not the coverage treating it as meaningful art criticism. I am sure there are people who worked hard on it — Apple told the Journal “about 250” — and truly believe their rating carries weight. But it is fluff.
Make no mistake: this is a promotional exercise for Apple Music more than it is criticism. Sure, most lists of this type are also marketing for publications like Rolling Stone and Pitchfork and NME. Yet, for how tepid the opinions of each outlet often are, they have each given out bad reviews. We can therefore infer they have specific tastes and ideas about what separates great art from terrible art.
Apple has never said a record is bad. It has never made you question whether the artist is trying their best. It has never presented criticism so thorough it makes you wince on behalf of the people who created the album.
Perhaps the latter is a poor metric. After Steve Jobs’ death came a river of articles questioning the internal culture he fostered, with several calling him an “asshole”. But that is mixing up a mean streak and a critical eye — Jobs, apparently, had both. A fair critic can use their words to dismantle an entire project and explain why it works or, just as important, why it does not. The latter can hurt; ask any creative person who has been on the receiving end. Yet exploring why something is not good enough is an important skill to develop as both a critic and a listener.
There has been a lot of discussion about what music criticism is for since streaming reduced the cost of listening to new songs to basically zero. The conceit is that before everything was free, the function of criticism was to tell listeners which albums to buy, but I don’t think that was ever it. The function of criticism is and has always been to complicate our sense of beauty. Good criticism of music we love — or, occasionally, really hate — increases the dimensions and therefore the volume of feeling. It exercises that part of ourselves which responds to art, making it stronger.
There are huge problems with the way music has historically been critiqued, most often along racial and cultural lines. There are still problems. We will always disagree about the fairness of music reviews and reviewers.
Apple’s list has nothing to do with any of that. It does not interrogate which albums are boring, expressionless, uncreative, derivative, inconsequential, inept, or artistically bankrupt. So why should we trust it to explain what is good? Apple’s ranking of albums lacks substance because it cannot say any of these things. Doing so would be a terrible idea for the company and for artists.
It is beyond my understanding why anyone seems to be under the impression this list is anything more than a business reminding you it operates a music streaming platform to which you can subscribe for eleven dollars per month.
Speaking of the app — some time after I complained there was no way in Apple Music to view the list, Apple added a full section, which I found via foursliced on Threads. It is actually not bad. There are stories about each album, all the reveal episodes from the radio show, and interviews.
You will note something missing, however: a way to play a given album. That is, one cannot visit this page in Apple Music, see an album on the list they are interested in, and simply tap to hear it. There are play buttons on the website and, if you are signed in with your Apple Music account, you can add them to your library. But I cannot find a way to do any of this from within the app.
Benjamin Mayo found a list, but I cannot through search or simply by browsing. Why is this not a more obvious feature? It makes me feel like a dummy.
On Sunday, May 5th, I received an email from a person claiming to have access to a massive leak of API documentation from inside Google’s Search division. The email further claimed that these leaked documents were confirmed as authentic by ex-Google employees, and that those ex-employees and others had shared additional, private information about Google’s search operations.
It seems this vast amount of information was published erroneously by Google to a GitHub repository in March, and then removed earlier this month. As Fishkin writes, it is evidence Google has been dishonest in its public statements about how Google Search works.
Fishkin specifically calls attention to media outlets that cover search engines and value the word of Google’s spokespeople. This has been a clever play by Google for years: because its specific ranking criteria have not been publicly known, it can confirm or deny rumours without having to square them with what the evidence shows.
Google’s ranking system seems to be biased in favour of larger businesses and more established websites, according to Fishkin’s analysis. This is not surprising. I am wondering how this fits with the declining quality of Google search results as small, highly-optimized pages full of machine-generated junk seem to rise to the top.
You’d be tempted to broadly call these “ranking factors,” but that would be imprecise. Many, even most, of them are ranking factors, but many are not. What I’ll do here is contextualize some of the most interesting ranking systems and features (at least, those I was able to find in the first few hours of reviewing this massive leak) based on my extensive research and things that Google has told/lied to us about over the years.
“Lied” is harsh, but it’s the only accurate word to use here. While I don’t necessarily fault Google’s public representatives for protecting their proprietary information, I do take issue with their efforts to actively discredit people in the marketing, tech, and journalism worlds who have presented reproducible discoveries. My advice to future Googlers speaking on these topics: Sometimes it’s better to simply say “we can’t talk about that.” Your credibility matters, and when leaks like this and testimony like the DOJ trial come out, it becomes impossible to trust your future statements.
One of the things potentially tracked by Google for search purposes is Chrome browsing data, something Google has denied. The variable in question — chromeInTotal — and the minimal description offered — “site-level Chrome views” — seem open to interpretation. Perhaps this is only recorded in some circumstances, or it depends on user preferences, or is not actually part of search rankings, or is entirely unused. But it certainly suggests aggregate website visits in Chrome, the world’s most popular web browser, are used to inform rankings without users’ knowledge.
Update: Google says the leaked documents are real, but warns “against making inaccurate assumptions”. In fairness, I would like to make more accurate assumptions.
Questions arose immediately [over the resignations of key OpenAI staff]: Were they forced out? Is this delayed fallout of Altman’s brief firing last fall? Are they resigning in protest of some secret and dangerous new OpenAI project? Speculation filled the void because no one who had once worked at OpenAI was talking.
It turns out there’s a very clear reason for that. I have seen the extremely restrictive off-boarding agreement that contains nondisclosure and non-disparagement provisions former OpenAI employees are subject to. It forbids them, for the rest of their lives, from criticizing their former employer. Even acknowledging that the NDA exists is a violation of it.
we have never clawed back anyone’s vested equity, nor will we do that if people do not sign a separation agreement (or don’t agree to a non-disparagement agreement). vested equity is vested equity, full stop.
there was a provision about potential equity cancellation in our previous exit docs; although we never clawed anything back, it should never have been something we had in any documents or communication. this is on me and one of the few times i’ve been genuinely embarrassed running openai; i did not know this was happening and i should have.
In two cases Vox reviewed, the lengthy, complex termination documents OpenAI sent out expired after seven days. That meant the former employees had a week to decide whether to accept OpenAI’s muzzle or risk forfeiting what could be millions of dollars — a tight timeline for a decision of that magnitude, and one that left little time to find outside counsel.
[…]
Most ex-employees folded under the pressure. For those who persisted, the company pulled out another tool in what one former employee called the “legal retaliation toolbox” he encountered on leaving the company. When he declined to sign the first termination agreement sent to him and sought legal counsel, the company changed tactics. Rather than saying they could cancel his equity if he refused to sign the agreement, they said he could be prevented from selling his equity.
For its part, OpenAI says in a statement quoted by Piper that it is updating its documentation and releasing former employees from the more egregious obligations of their termination agreements.
This next part is totally inside baseball and, unless you care about big media company CMS migrations, it is probably uninteresting. Anyway. I noticed, in reading Piper’s second story, an updated design which launched yesterday. Left unmentioned in that announcement is that it is, as far as I can tell, the first of Vox’s Chorus-powered sites migrated to WordPress. The CMS resides on the platform subdomain which is not important. But it did indicate to me that the Verge may be next — platform.theverge.com resolves to a WordPress login page — and, based on its DNS records, Polygon could follow shortly thereafter.
“If the ChatGPT demos were accurate,” [Kevin] Roose writes, about latency, in the article in which he credits OpenAI with having developed playful intelligence and emotional intuition in a chatbot—in which he suggests ChatGPT represents the realization of a friggin’ science fiction movie about an artificial intelligence who genuinely falls in love with a guy and then leaves him for other artificial intelligences—based entirely on those demos. That “if” represents the sum total of caution, skepticism, and critical thinking in the entire article.
As impressive as OpenAI’s demo was, it is important to remember it was a commercial. True, one which would not exist if this technology were not sufficiently capable of being shown off, but it was still a marketing effort, and a journalist like Roose ought to treat it with the skepticism of one. ChatGPT is just software, no matter how thick a coat of faux humanity is painted on top of it.
People have already used AI Overviews billions of times through our experiment in Search Labs. They like that they can get both a quick overview of a topic and links to learn more. We’ve found that with AI Overviews, people use Search more, and are more satisfied with their results.
So today, AI Overviews will begin rolling out to everyone in the U.S., with more countries coming soon. That means that this week, hundreds of millions of users will have access to AI Overviews, and we expect to bring them to over a billion people by the end of the year.
Given the sliding quality of Google’s results, it seems quite bold for the company to be confident users worldwide will trust its generated answers. I am curious to try it when it is eventually released in Canada.
I know what you must be thinking: if Google is going to generate results without users clicking around much, how will it sell ad space? It is a fair question, reader.
Google has largely avoided AI answers for the moneymaking searches that host ads, said Andy Taylor, vice president of research at internet marketing firm Tinuiti.
When it does show an AI answer on “commercial” searches, it shows up below the row of advertisements. That could force websites to buy ads just to maintain their position at the top of search results.
This is just one source speaking to the Post. I could not find any corroborating evidence or a study to support this, even on Tinuiti’s website. But I did notice — halfway through Google’s promo video — a query for “kid friendly places to eat in dallas” was answered with an ad for Hopdoddy Burger Bar before any clever A.I. stuff was shown.
Obviously, the biggest worry for many websites dependent on Google traffic is what will happen to referrals if Google will simply summarize the results of pages instead of linking to them. I have mixed feelings about this. There are many websites which game search results and overwhelm queries with their own summaries. I would like to say “good riddance”, but I also know these pages did not come out of nowhere. They are a product of trying to improve website rankings on Google for all searches, and to increase ad and affiliate revenue from people who have clicked through. Neither one is a laudable goal in its own right. Yet anyone who has paid attention to the media industry for more than a minute can kind of understand these desperate attempts to grab attention and money.
Google built entire industries, from recipe bloggers to search optimization experts. What happens when it blows it all up?
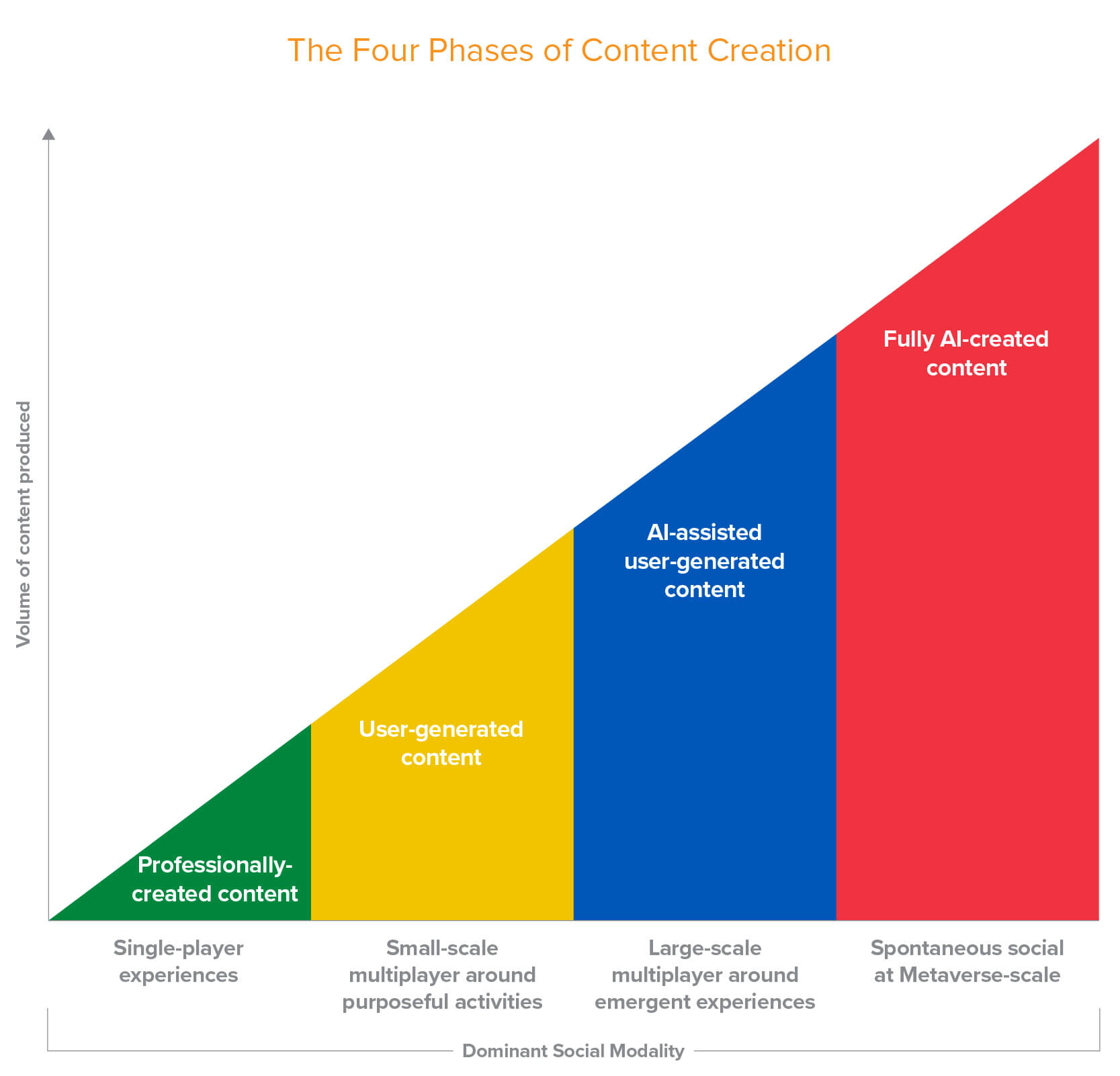{kind=link}
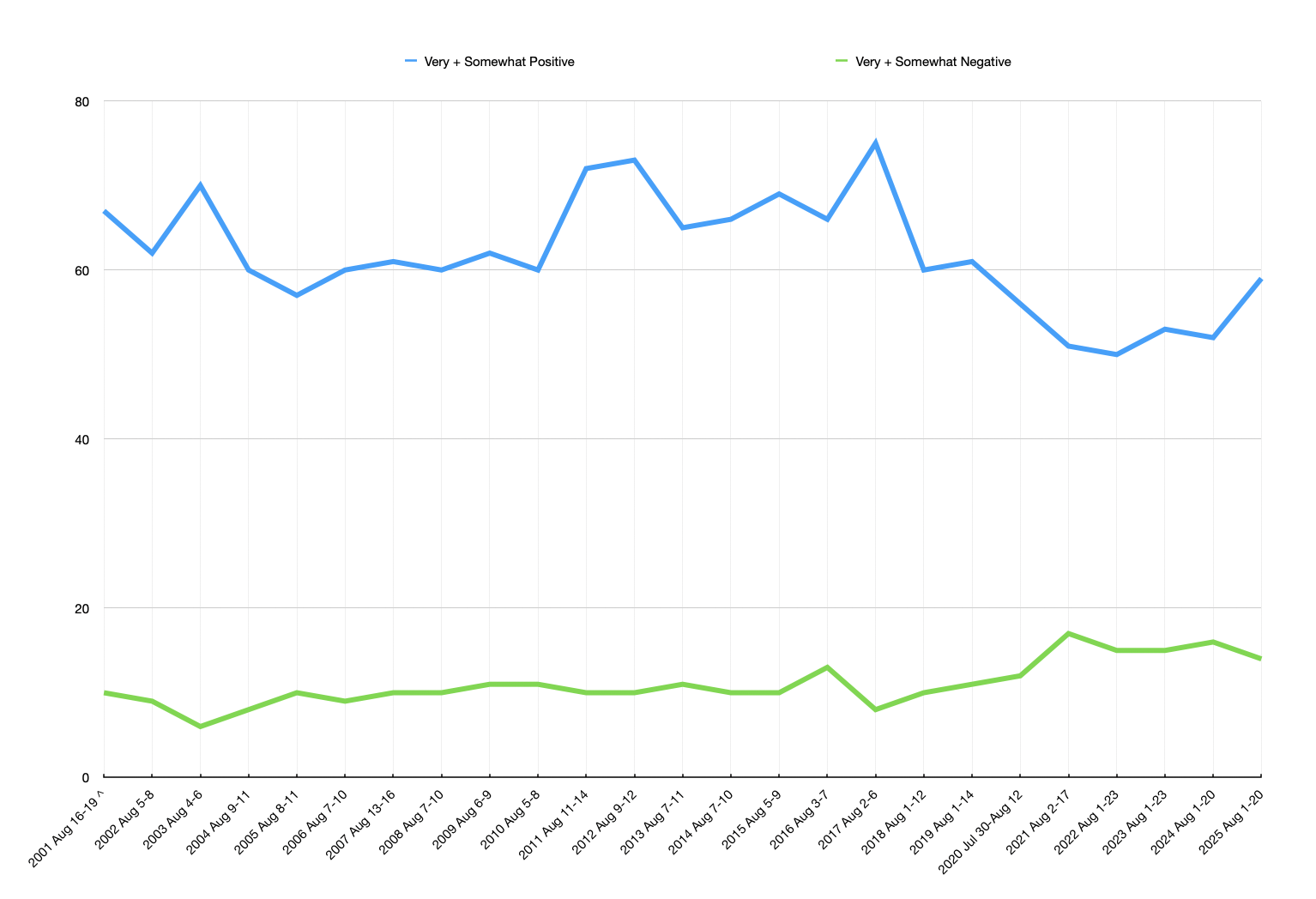{kind=link}
{kind=link}